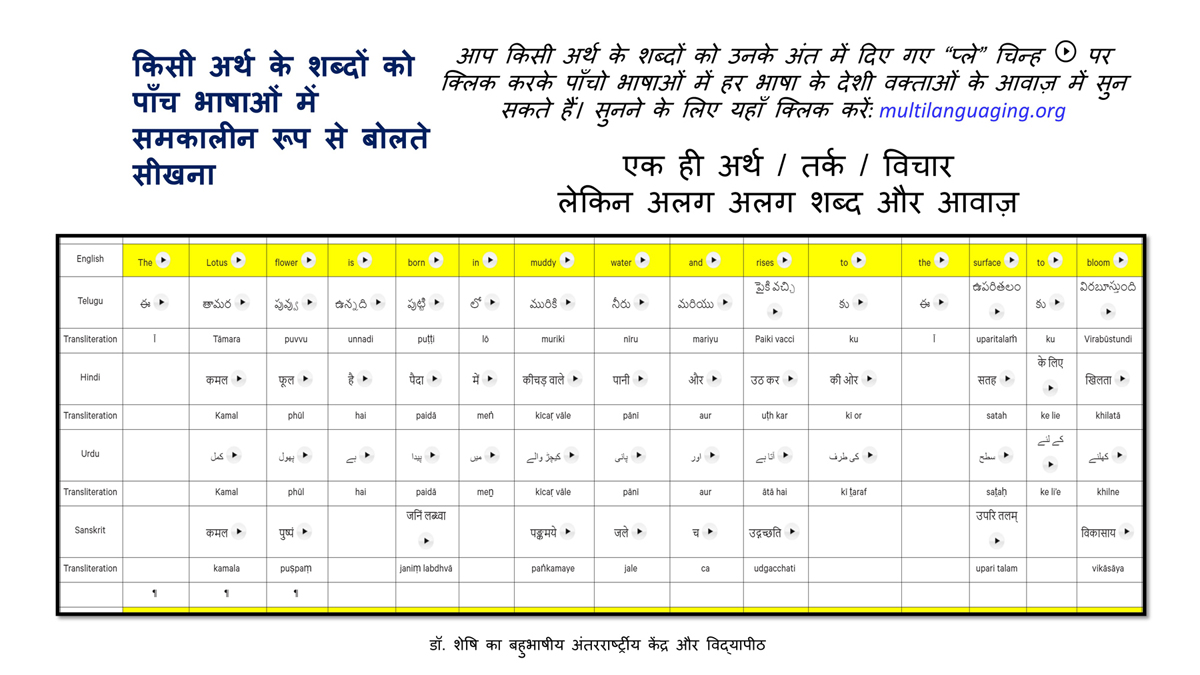
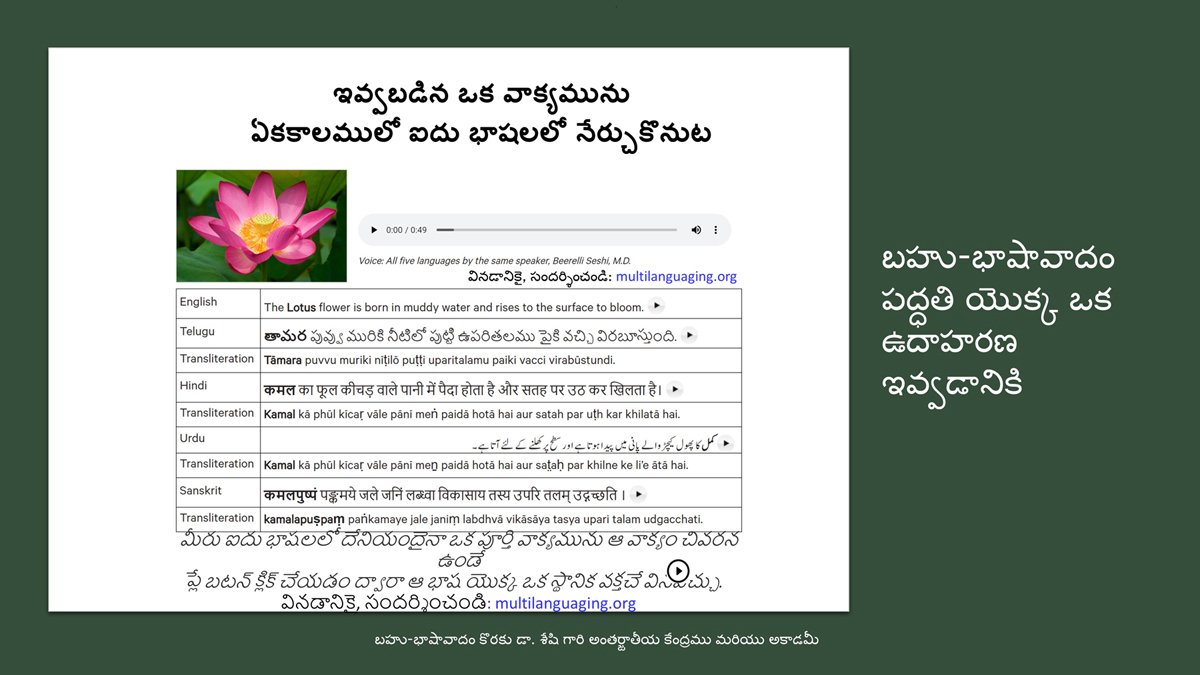
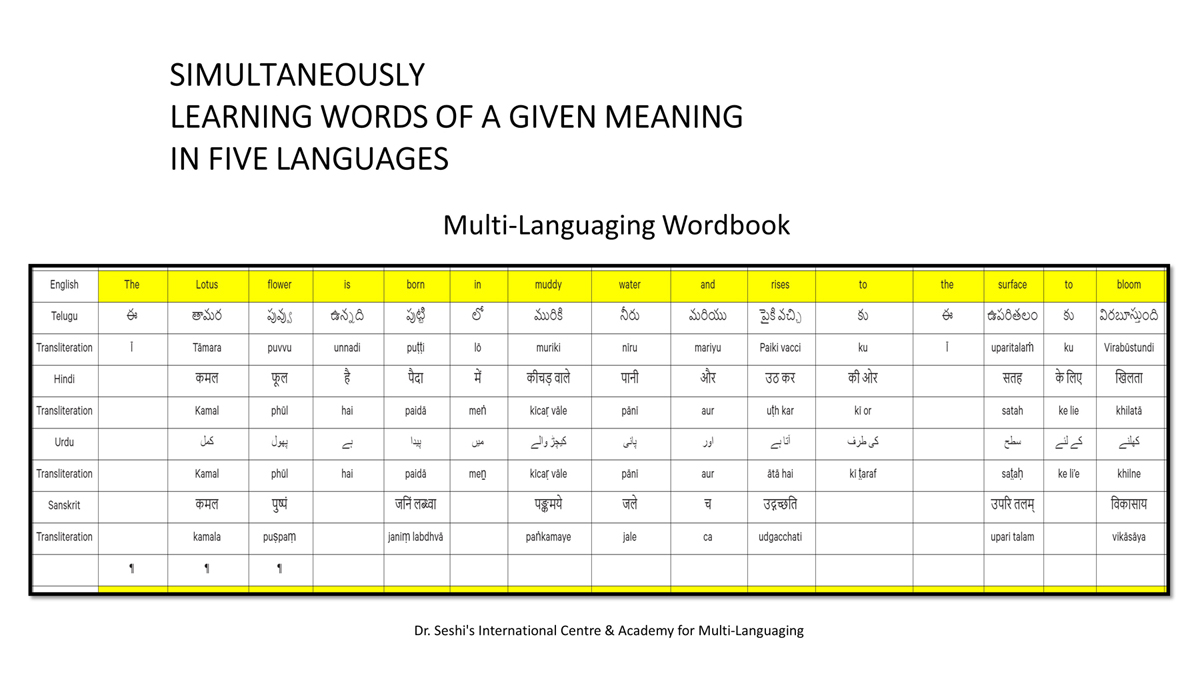
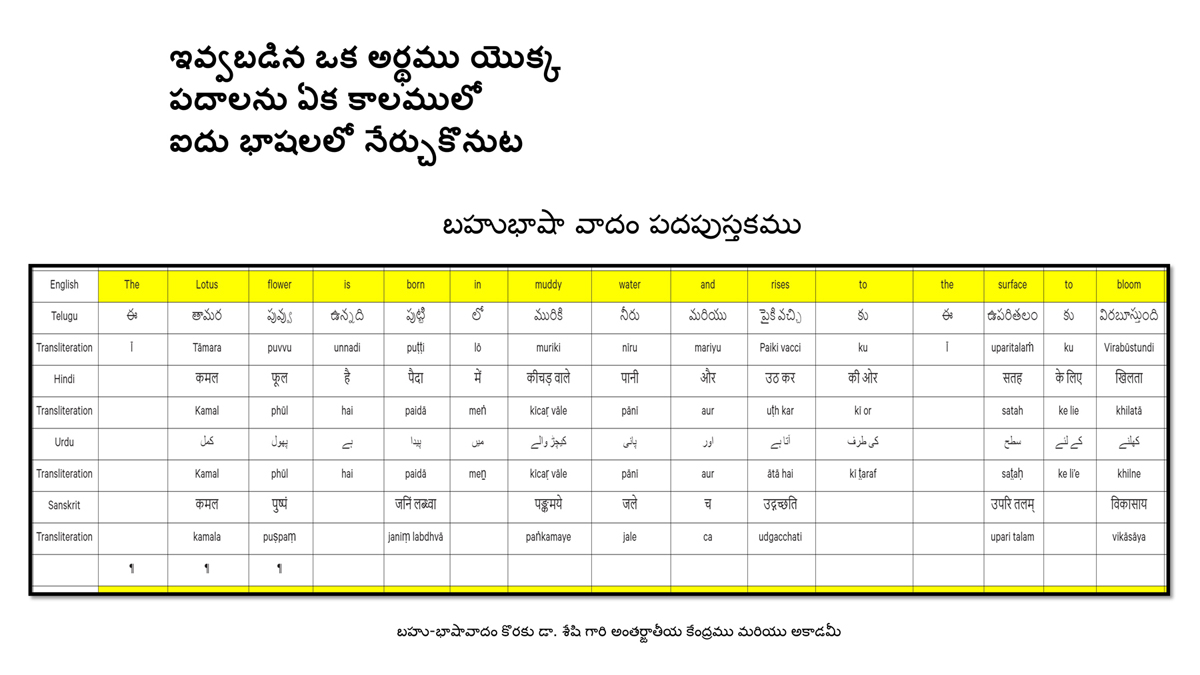
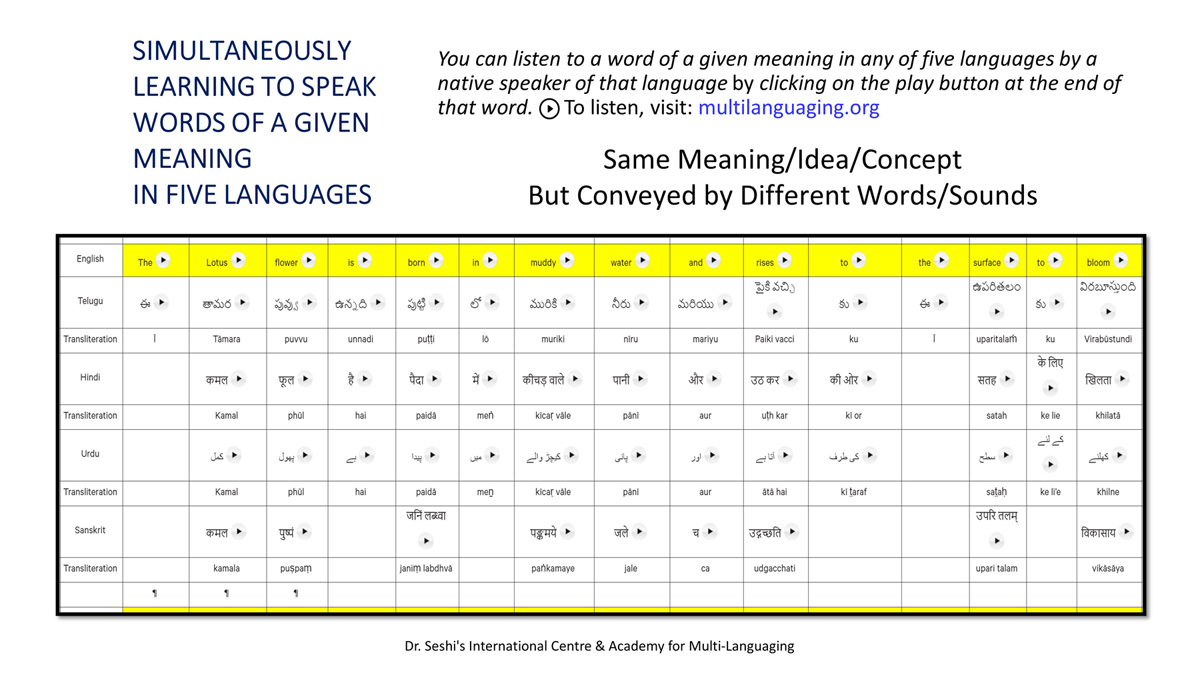
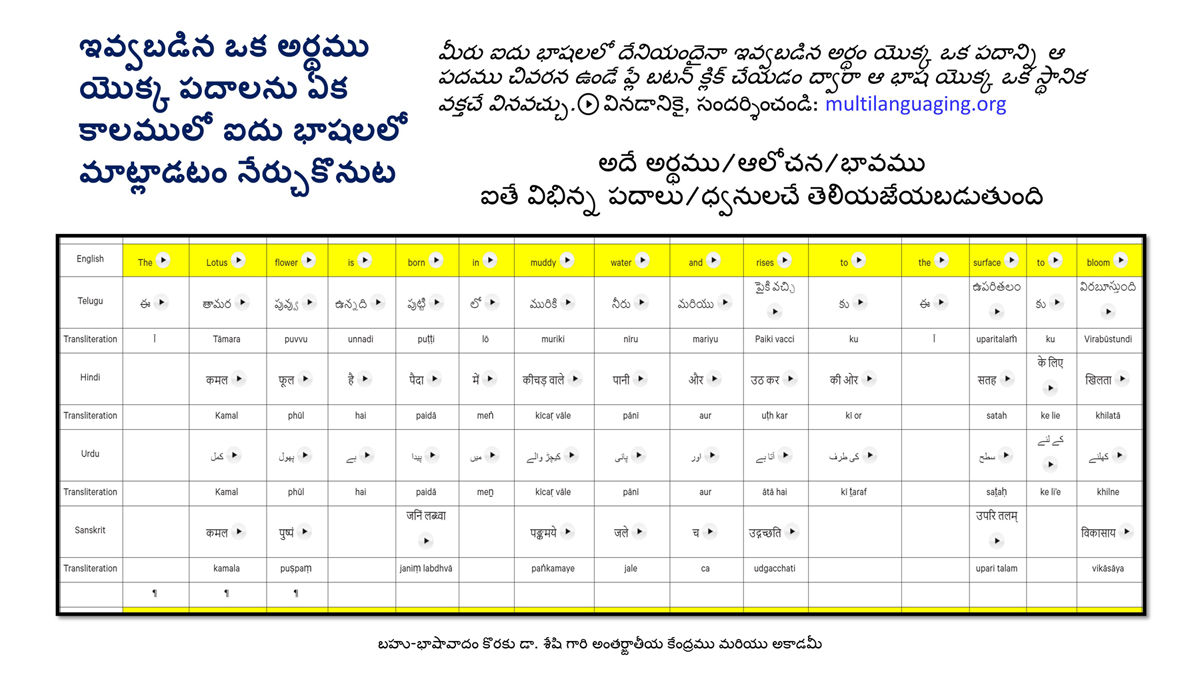
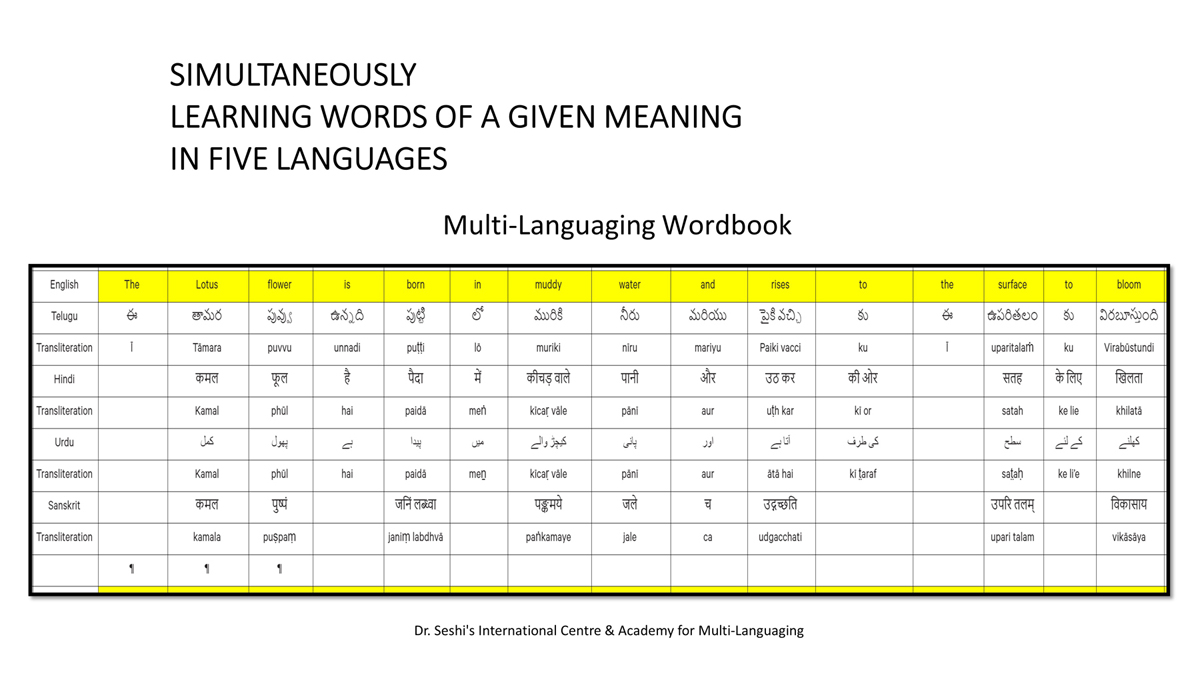
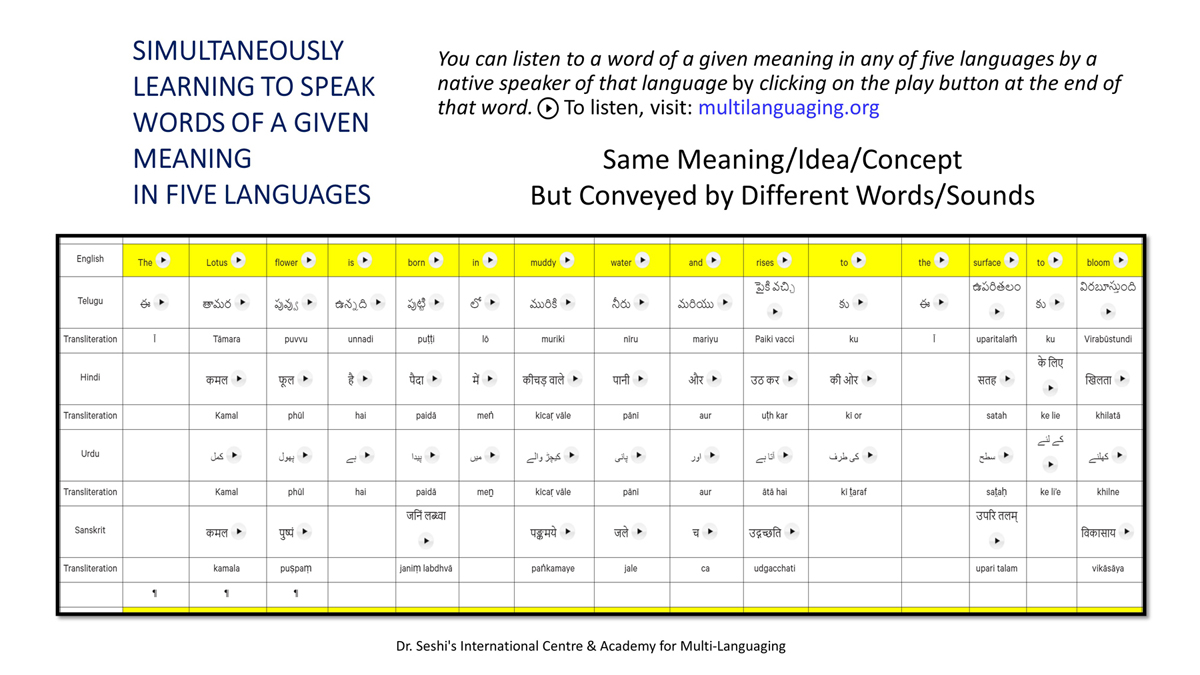
By character mapping, I mean character-by-character or letter-by-letter translation across languages (such as English, Telugu, Hindi, Urdu, and Sanskrit).
حروف کی نقشہ سازی سے مراد ہر ایک زبان کے مابین علامت بہ علامت یا حرف بہ حرف ترجمہ (جیسے کہ انگریزی، تیلگو، ہندی، اردو اور سنسکرت) کی ہے۔
ḥurūf kī naqshah sāzī se murād har ek zubān ke mā bain ʿalāmat bah ʿalāmat yā ḥarf bah ḥarf tarjumeh (jaise keh angrezī telugū, urdū aur Sanskrit) kī hai.
That is mapping the sounds of one language to others.
یعنی ایک زبان کی آوازوں کو دوسری زبانوں کی آوازوں سے نقشہ بند کرنا۔
Yaʿnī ek zubān kī āvāzon̠ ko dūsrī zubānon̠ kī āvāzon̠ se naqshah band karnā.
It is a converse of the word-by-word and sentence-by-sentence translations as they are implemented in this project.
یہ لفظ بہ لفظ اور جملے بہ جملے ترجمہ کا ، اس منصوبے میں ان کے اطلاق کی حیثیت سے،بر عکس ہے ۔
Yeh lafz̤ bah lafz̤ aur jumle bah jumle tarjumeh kā, is manṣūbe men̠ un ke int̤ilāq kī ḥais̱iyat se, bar ʿaks hai.
While the conventional translations map meanings across languages, alphabetics maps sounds.
جہاں روایتی تراجم مختلف زبانوں کے ما بین معانی کی نقشہ سازی کرتے ہیں ، حروف تہجی کے سائنس میں آوازوں کی نقشہ سازی ہوتی ہیں ۔
Jahān̠ rivāyatī tarājim muḵẖtalif zubānon̠ ke mā bain maʿānī kī naqshah sāzī karte hain̠, ḥurūf-i tahajjī ke sā’ins men̠ āvāzon̠ kī naqshah sāzī hotī hain̠.
Letter-level translation between languages may interchangeably be viewed as transliteration.
زبانوں کے مابین حرفی سطح کے ترجمے کو متبادل طور پر نقل حرفی کے طور پر بھی دیکھا جاسکتا ہے۔
Zubānon̠ ke mā bain ḥarfī sat̤aḥ ke tarjume ko mutabādil t̤aur par naql-i ḥarfī ke t̤aur par bhī dekhā jā saktā hai.
¶
Just as word/sentence translation maps meanings/concepts/ideas, so too letter-by-letter translation maps the sounds of one language to another.
جس طرح لفظ /جملے کے ترجمے معنی/تصورات/نظریات کو نقشہ بند کرتے ہیں، اسی طرح حرف بہ حرف ترجمے ایک زبان کی آواز کو دوسری زبان کی آواز سے نقشہ بند کرتے ہے۔
Jis t̤araḥ lafẓ / jumle ke tarjume maʿnā/taṣavvurāt/naz̤ariyāt ko naqshah band karte hain̠, usī t̤araḥ ḥarf bah ḥarf tarjume ek zubān kī āvāz ko dūsrī zubān kī āvāz se naqshah band karte hai.
In a sense, the former is more a mental exercise dealing with objects or ideas represented by words/sentences, regardless of the sounds that accompany them, whereas the latter, in a sense, is more physical and sensory, dealing exclusively with the impression of the sound that is conveyed by the letter.
ایک اعتبار سے، سابقہ الفاظ/جملے کے ذریعہ نمائندگی کردہ اشیاء یا نظریات سے نمٹنے کے لئے زیادہ سے زیادہ ذہنی مشق کرنا ہے، ان آوازوں سے قطع نظر جو ان مے ہوں، جبکہ دوسرا ، زیادہ طبعی یا حسی ہے، اور مجموعی طور پر وہ آواز جو خط کے ذریعہ پہنچائی جاتی ہے اس کے ساتھ نبرد آزما ہونا ہے۔
Ek eʿtibār se, sābiqah alfāz̤ / jumle ke ẕarīʿe numā’indgī kardah ashyā’ yā naz̤ariyāt se nimaṭne ke li’e zyādah se zyādah ẕehnī mashq karnā hai, un āvāzon̠ se qat̤eʿ naz̤ar ko un me hon̠, jabkeh dūsrā zyādah t̤abʿī yā ḥissī hai, aur majmūʿī t̤aur par voh āvāz jo ḵẖat̤ ke ẕarīʿeh pehcānī jātī hai us ke sāth nabard āzmā honā hai.
¶
It may, at first thought, appear to be challenging and difficult for the students to have to learn alphabets of five languages.
یہ، ابتدائی غور وفکر میں طلبہ کے لئے محنت طلب اور مشکل دکھائی دے رہا ہے کہ وہ پانچ زبانوں کے حروف تہجی سیکھیں۔
Yeh, ibtidā’ī g̠h̠aur o fikr men̠ t̤albah ke li’e meḥnat t̤alab aur mushkil dikhā’ī de rahā hai keh voh pān̠c zubānon̠ ke ḥurūf-i tahajjī sīkhen̠.
However, it may not be as intimidating as it appears to be once the students start learning them.
تاہم، یہ اتنا ڈراونا نہیں ہے جتنا لگتا ہے، جب طلبا ان کو سیکھنا شروع کردیں۔
Tāham, yeh utnā ḍaravnā nahīn̠ hai jitnā lagtā hai, jab t̤albā un ko sīkhnā shurūʿ kar den̠.
The purpose of the accompanying Excel worksheets is to highlight the kinship among these alphabets, contributing to their learnability.
ایکسل ورک شیٹس کو ملحق کرنے کا مقصد یہ ہے کہ ان حروف کے درمیان تعلق کو اجاگر کیا جائے، تاکہ ان کی سیکھنے کی اہلیت میں مدد دی جائے۔
Eksal vark shīṭs ko mulḥiq karne kā maqṣad yeh hai keh in ḥurūf ke darmyān taʿalluq ko ujāgar kiyā jā’e, tākeh un kī sīkhne kī ehliyat me madad dī jā’e.
¶
As many of the readers would know, Hindi and Sanskrit use the same script, Devanagari.
جیسا کہ بہت سے قارئین جانتے ہوں گے، ہندی اور سنسکرت ایک ہی رسم الخط، دیواناگری کا استعمال کرتے ہیں ۔
Jaisā keh bohot se qāri’īn jānte hon̠ ge, hindī aur Sanskrit ek hī rasmul ḵẖat̤, devānāgrī kā istaʿmāl karte hain̠.
Although Telugu uses a different script, its alphabet is essentially identical to Devanagari.
اگرچہ تیلگو میں مختلف رسم الخط کا استعمال کیا جاتا ہے، لیکن اس کے حروف تہجی بنیادی طور پر دیواناگری کے مترادف ہیں۔
Agarceh telugū men̠ muḵẖtalif rasmul ḵẖat̤ kā istaʿmāl kiyā jātā hai, lekin us ke ḥurūf-i tahajjī bunyādī t̤aur par devānāgrī ke mutarādif hain̠.
This is not to trivialize the differences, but the THS alphabets are practically one alphabet.
یہ اختلافات کی اہمیت کو کم کرنا نہیں ہے، لیکن "THS" (تیلگو، ہندی، سنسکرت) کے حروف تہجی عملی طور پر ایک ہی حرف ہیں۔
Yeh iḵẖtelāfāt kī ehmiyat ko kam karnā nahīn̠ hai, lekin "THS" (telugū, hindī, Sanskrit) ke ḥurūf-i tahajjī ʿamalī t̤aur par ek hī ḥarf hain̠.
The difference is that, while Sanskrit and Hindi use Devanagari script, Telugu uses a different script―the same sounds, but different scripts/representations.
فرق یہ ہے کہ، سنسکرت اور ہندی میں دیواناگری رسم الخط کا استعمال کیا جاتا ہے اور تیلگو میں مختلف اسکرپٹ کا استعمال کیا جاتا ہے ― وہی یکساں آوازیں، لیکن مختلف رسم الخط/اظہارات۔
Farq yeh hai keh, Sanskrit aur hindī men̠ devānāgrī rasmul ḵẖat̤ kā istaʿmāl kiyā jātā hai aur telugū men̠ muḵẖtalif iskripṭ kā istaʿmāl kiyā jātā hai – wahī yaksān̠ āvāzen̠ lekin muḵẖtalif rasmul ḵẖat̤ / iz̤hārāt.
This concept of "same sound but different script symbol" is another visible form of India’s national motto, "Unity in Diversity"―"विविधतायामेकता"―"vividhatāyāmekatā".
"ایک ہی آواز لیکن مختلف رسم الخط کی علامت" کا یہ تصور ہندوستان کے قومی مقصد کی ایک اور دکھائی دینے والی شکل ہے، "تنوع میں اتحاد" – " विविधतायामेकता " – " vividhatāyāmekatā "۔
"ek hī āvāz lekin muḵẖtalif rasmul ḵẖat̤ kī ʿalāmat" kā yeh taṣavvur hindustān ke qaumī maqṣad kī ek aur dikhā’ī dene vālī shakl hai, "tanavvuʿ men̠ ittiḥād" – "विविधातायामेकता" – "vividhatāyāmekatā".
The important message to be imparted to the children is that, although outward forms differ, the essence is the same―the same sound "a" is represented differently across scripts for Telugu, Sanskrit/Hindi, and Urdu―అ, अ/अ, and ا.
بچوں کو یہ اہم پیغام دینا ہے کہ، اگرچہ ظاہری شکلیں مختلف ہیں―لیکن بنیادی جوہر ایک ہی ہے―اسی آواز "اے" کو تیلگو ، سنسکرت/ہندی، اور اردو کے رسم الخط میں الگ الگ انداز అ, अ/अ اور ا سے ظاہر کیا جاتا ہے۔
Baccon̠ ko yeh ehem paig̠h̠ām denā hai keh, agarceh ẓāhirī shaklen̠ muḵẖtalif hain̠ – lekin bunyādī jauhar ek hī hai – usī āvāz "e" ko telugū, Sanskrit/hindī aur urdū ke rasmul ḵẖat̤ men̠ alag alag andāz అ, अ/अ, aur ا se z̤āhir kiyā jātā hai.
¶
This could be achieved in an imaginative and entertaining manner through visual media, especially videos or smartphone apps for children.
اسے بصری میڈیا خصوصا ویڈیوز یا بچوں کے لئے اسمارٹ فون ایپس کے ذریعے تخیلاتی اور تفریحی انداز میں حاصل کیا جاسکتا ہے۔
Ise baṣrī mīḍiyā ḵẖuṣūṣan vīḍyoz yā baccon̠ ke li’e ismārṭ fon aips ke ẕarīʿe taḵẖaiyolātī aur tafrīḥī andāz men̠ ḥāṣil kiyā jā saktā hai.
It will be equally instructive for adult learners, as it would convey a powerful message of underlying sameness hidden by outwardly different form.
یہ بالغان کے لئے یکساں طور پر تعلیم دینے والا ہوگا، کیونکہ یہ ظاہری طور پر مختلف شکلوں سے پوشیدہ بنیادی یکسانیت کا ایک طاقتور پیغام پہنچائے گا۔
Yeh bālig̠h̠ān ke li’e yaksān̠ t̤aur par taʿlīm dene vālā hogā, kyūn̠keh yeh z̤āhirī t̤aur par muḵẖtalif shaklon̠ se poshīdah bunyādī yaksāniyat kā ek t̤āqatvar paig̠h̠ām pohn̠cā’e gā.
Moreover, it will emphasize the fact that all these languages are intimately connected to each other either as mother-daughter or as sisters/cousins.
مزید یہ کہ اس حقیقت پر بھی زور دیا جائے گا کہ یہ ساری زبانیں ایک دوسرے سے یا تو ماں بیٹی کے طور پر یا بہنوں/کزنوں کی حیثیت سے جڑی ہوئی ہیں۔
Mazīd yeh keh is ḥaqīqat par bhī zor diyā jā’e gā keh yeh sārī zubānen̠ ek dūsre se yā to mān̠ beṭī ke t̤aur par yā behnon̠ / kazinon̠ kī ḥais̱iyat se juṛī hu’ī hain̠.
I have also endeavored to convey this message while answering the FAQs, especially FAQ 3 and FAQ 10.
میں نے اکثر پوچھے گئے سوالات، خاص طور پر اکثر پوچھے گئے سوال 3 اور اکثر پوچھے گئے سوال 10 کا جواب دیتے ہوئے یہ پیغام پہنچانے کی کوشش کی ہے۔
Main̠ ne aks̱ar pūche ga’e savālāt, ḵẖāṣ t̤aur par aks̱ar pūche ga’e savāl 3 aur aks̱ar pūche ga’e savāl 10 kā javāb dete hu’e yeh paig̠h̠ām pohn̠cāne kī koshish kī hai.
¶
In fact, alphabetics makes this point rather more emphatically than the vocabulary/words of these languages.
دراصل، حروف تہجی کا سائنس اس نکتے کو ان زبانوں کے الفاظ کی نسبت زیادہ زور دے کر واضح کرتا ہیں۔
Dar aṣal, ḥurūf-i tahajjī kā sā’ins is nukte ko in zubānon̠ ke alfāz̤ ki nisbat zyādah zor de kar vāẓeḥ kartā hain̠.
With words, we see that an identical word may sometimes have a different sense or a more nuanced sense in different languages (sometimes leading to confusion in translations) due to the passage of time and variance from the source.
الفاظ کے ساتھ، ہم دیکھتے ہیں کہ وقت گزرنے اوراصل سے انحراف کی وجہ سے ایک جیسے لفظ کی بعض اوقات مختلف زبانوں میں مختلف معنی یا زیادہ متشابہ معنی ہوسکتی ہیں (بعض اوقات ترجمہ میں الجھن پیدا ہوتی ہے)۔
Alfāz̤ ke sāth ham dekhte hain̠ keh vaqt guzarne aur aṣl se inḥirāf kī vajah se ek jaise lafz̤ kī baʿaẓ avqāt muḵẖtalif zubānon̠ men̠ muḵẖtalif maʿnā yā zyādah mutashābih maʿnā ho saktī hain̠ (baʿaẓ avqāt tarjumeh men̠ uljhan paidā hotī hai).
However, the sounds remain the same, new sounds may be added, or some old ones omitted, but the alphabet remains unaltered to a very great extent, especially among THS languages.
تاہم، آوازیں وہی رہتی ہیں، نئی آوازیں شامل کی جاسکتی ہیں، یا کچھ پرانی آوازوں کو نظر انداز کیا جا سکتا ہے، لیکن حرف تہجی بہت حد تک غیر تبدیل شدہ رہتے ہیں، خاص طور پر THS زبانوں میں۔
Tāham, āvāzen̠ vahī rehtī hain̠, na’ī āvāzen̠ shāmil kī jā saktī hain̠, yā kuch purānī āvāzon̠ ko naz̤ar andāz kiyā jā saktā hai, lekin ḥarf-i tahajjī bohot ḥad tak g̠h̠air tabdīl shudah rehte hain̠, ḵẖāṣ t̤aur par THS zubānon̠ men̠.
Therefore, I cannot overemphasize the importance of learning and cherishing these alphabets.
لہذا، میں ان حروف تہجی کو سیکھنے اور اس کی پیروی کرنے کی اہمیت کو اس سے زیادہ واضح نہیں کرسکتا۔
Lihāẕā, main̠ in ḥurūf-i tahajjī ko sīkhne aur us kī pairvī karne kī ehmiyat ko is se zyādah vāẓeḥ nahīn̠ kar saktā.
¶
English uses the Latin/Roman alphabet, which to its credit is the easiest to learn.
انگریزی میں لاطینی/رومن حروف تہجی کا استعمال کیا جاتا ہے، جس کی وجہ سے اس کا سیکھنا بہت آسان ہے۔
Angrezī men̠ lāt̤īnī / roman ḥurūf-i tahajjī kā istaʿmāl kiyā jātā hai, jis kī vajah se is kā sīkhnā bohot āsān hai.
The script that stands out in terms of difficulty is that of Urdu, which is based on a Perso-Arabic alphabet that is quite different from the Latin and THS alphabets.
مشکل کے لحاظ سے جو رسم الخط مشکل ہے وہ اردو کا ہے، جو فارسی-عربی حرف تہجی پر مبنی ہے جو لاطینی اور THS حروف تہجی سے بالکل مختلف ہے۔
Mushkil ke liḥāz̤ se jo rasmul ḵẖat̤ mushkil hai voh urdū kā hai, jo fārsī-ʿarbī ḥarf-i tahajjī par mabnī hai jo lāt̤īnī aur THS ḥurūf-i tahajjī se bilkul muḵẖtalif hai.
On the other hand, although Urdu uses a different script from Hindi, their day-to-day language and grammar are basically identical.
دوسری جانب، اگرچہ ہندی میں اردو سے مختلف رسم الخط کا استعمال کیا جاتا ہے، لیکن ان کی روزمرہ کی زبان اور گرامر بنیادی طور پر ایک جیسے ہیں۔
Dūsrī jānib, agarceh hindī men̠ urdū se muḵẖtalif rasmul ḵẖat̤ kā istaʿmāl kiyā jātā hai, lekin un kī roz marrah kī zubān aur girāmar bunyādī t̤aur par ek jaise hain̠.
¶
As outlined above, my point is that it is not like having to learn five unrelated languages or scripts, like Arabic, Chinese, Devanagari, Greek, and Yucatec Maya, for example.
جیسا کہ اوپر بیان کیا گیا ہے، میرا نکتہ یہ ہے کہ یہ سب عربی، چینی، دیواناگری، یونانی اور یوکاٹک مایا جیسی پانچ غیر متعلقہ زبانیں یا رسم الخط سیکھنے کی طرح نہیں ہے۔
Jaisā keh ūpar bayān kiyā gayā hai, merā nuktah yeh hai keh yeh sab ʿarbī, cīnī, devānāgrī, yūnānī aur yūkāṭik māyā jaisī pān̠c g̠h̠air mutaʿalliqa zubānen̠ yā rasmul ḵẖat̤ sīkhne kī t̤araḥ nahīn̠ hai.
¶
The accompanying "Alphabet Mapping Tables" section graphically highlights the relatedness of THUS alphabets.
اس کے ساتھ "حرفی نقشہ سازی کے جداول" سیکشن گراف کے انداز میں ان حرفوں کی مناسبت کو نمایاں کرتا ہے۔
Is ke sāth "ḥarfī naqshah sāzī ke jadāvil" sekshan girāf ke andāz men̠ in ḥarfon̠ kī munāsabat ko numāyā kartā hai.
To encourage the new learner and ensure that he/she not be intimidated by the chaotic-appearing Urdu script, I have tried to organize the Urdu letters into various groupings showing the underlying visual pattern within each group.
نئے سیکھنے والوں کی حوصلہ افزائی کرنے اور اس بات کو یقینی بنانے کے لئے کہ وہ اردو کے افراتفری سے ظاہر ہونے والے رسم الخط سے نہ گھبرائیں، میں نے مختلف مجموعات میں اردو کے الفاظ کو ترتیب دینے کی کوشش کی ہے جس میں ہر مجموعہ کے اندر بنیادی انداز کو ظاہر کیا گیا ہے۔
Na’e sīkhne vālon̠ kī ḥauṣlah afzā’ī karne aur is bāt ko yaqīnī banāne ke li’e keh voh urdū ke afrā tafrī se z̤āhir hone vāle rasmul ḵẖat̤ se na ghabrā’en̠, main̠ ne muḵẖtalif majmūʿāt men̠ urdū ke alfāz̤ ko tartīb dene kī koshish kī hai jis men̠ har majmūʿeh ke andar bunyādī andāz ko z̤āhir kiyā gayā hai.
To facilitate the reference, learning, remembering and usage of the THUS alphabets, I have organized them in the form of ten tables laid out horizontally as in the accompanying "Alphabet Mapping Tables" section, from left to right:
ان THUS (تیلگو، ہندی، اردو اور سنسکرت) حروف کے حوالے، سیکھنے، یاد رکھنے اور استعمال میں آسانی کے لئے، میں نے انہیں دس جداول کی شکل میں ترتیب دیا ہے جنہیں افقی طور پر رکھی گئی ہے، جیسا کہ ساتھ والے با ئیں سے دائیں طرف کے "حرفی نقشہ سازی کے جداول" کے حصے میں ہے:
In THUS (telugū, hindī, urdū aur Sanskrit) ḥurūf ke ḥavāle, sīkhne, yād rakhne aur istaʿmāl men̠ āsānī ke li’e, main̠ ne unhen̠ das jadāvil kī shakl men̠ tartīb diyā hai jinhen̠ ufqī t̤aur par rakhī ga’ī hai, jaisā keh sāth vāle bā’en̠ se dā’en̠ t̤araf ke "ḥarfī naqshah sāzī ke jadāvil" ke ḥiṣṣe men̠ hai:
¶
Table 1 – Devanagari and Telugu Vowels
جدول 1 – دیواناگری اور تیلگو حروف علت
Jadval 1 – devānāgrī aur telugū ḥurūf-i ʿillat
Table 2 – Devanagari and Telugu Consonants
جدول 2 – دیواناگری اور تیلگو حروف صامت
Jadval 2 – devānāgrī aur telugū ḥurūf-i ṣāmit
Table 3 – Devanagari Consonant Clusters
جدول 3 – دیواناگری حرف صامت مجموعات
Jadval 3 – devānāgrī ḥarf-i ṣāmit majmūʿāt
Table 4 – Devanagari and Urdu Special Consonants
جدول 4 – دیواناگری اور اردو خصوصی حروف صامت
Jadval 4 – devānāgrī aur urdū ḵẖuṣūṣī ḥurūf-i ṣāmit
Table 5 – Devanagari Hindi vs. Urdu Vowels
جدول 5 – دیواناگری ہندی بمقابلہ اردو حروف علت
Jadval 5 – devānāgrī hindī bamuqāblah urdū ḥurūf-i ʿillat
Table 6 – Devanagari Hindi vs. Urdu Consonants
جدول 6۔ دیواناگری ہندی بمقابلہ اردو حروف صامت
Jadval 6 – devānāgrī hindī bamuqāblah urdū ḥurūf-i ṣāmit
Table 7 – Devanagari vs. Urdu: Digraphs (Stressed Consonants/Aspirates)
جدول 7 – دیواناگری بمقابلہ اردو: ڈیگراف (بھاری حروف صامت/سانس والی آواز)
Jadval 7 – devānāgrī bamuqāblah urdū: daigirāf (bhārī ḥurūf ṣāmit / sān̠s vālī āvāz)
Table 8 – Urdu Letters with Dots
جدول 8۔ نقاط والے اردو کے حروف
Jadval 8 – niqāt̤ vāle urdū ke ḥurūf
Table 9 – Urdu Letters Without Dots
جدول 9۔ نقاط کے بغیر اردو کے حروف
Jadval 9 – nuqāt̤ ke bag̠h̠air urdū ke ḥurūf
Table 10 – Complete Urdu Alphabet in All Forms
جدول 10۔ تمام اشکال میں مکمل اردو حرف تہجی
Jadval 10 – tamām ashkāl men̠ mukammal urdū ḥarf-i tahajjī
¶
It is hoped that this will make it easier to learn, remember and use the alphabets in question.
یہ امید کی جاتی ہے کہ اس سے متعلقہ حروف تہجی کو سیکھنے، یاد رکھنے اور استعمال کرنے میں آسانی ہوگی۔
Yeh ummīd kī jātī hai keh is se mutaʿalliqah ḥurūf-i tahajjī ko sīkhne, yā rakhne aur istaʿmāl karne men̠ āsānī hogī.
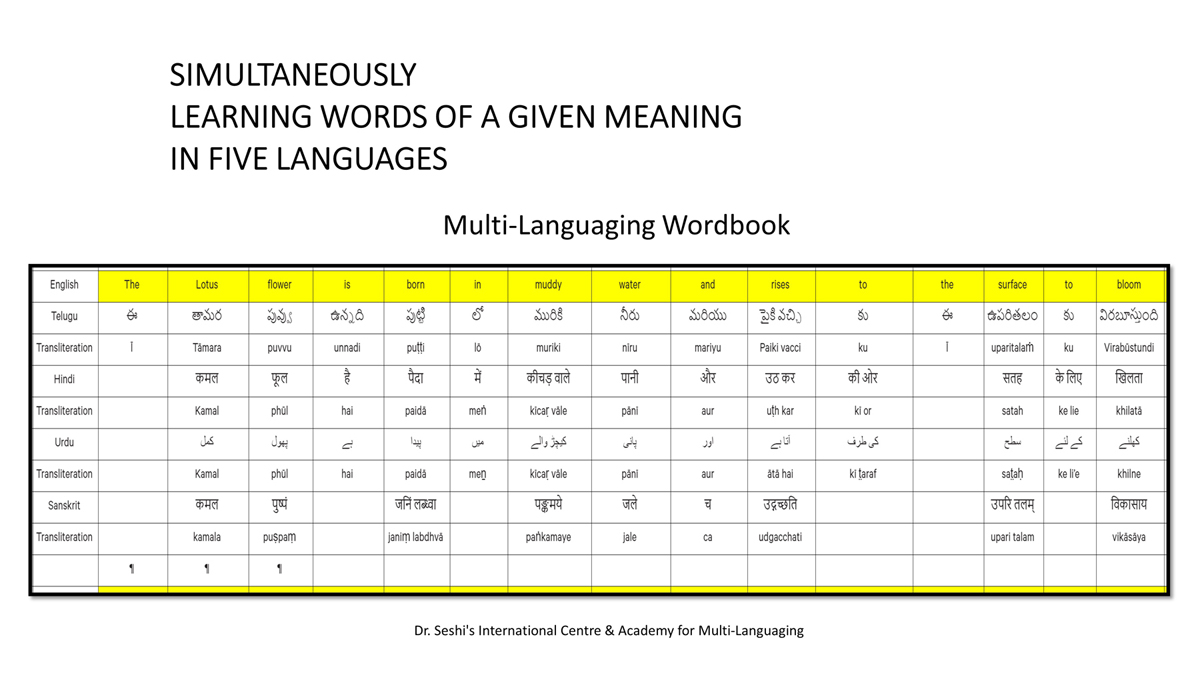
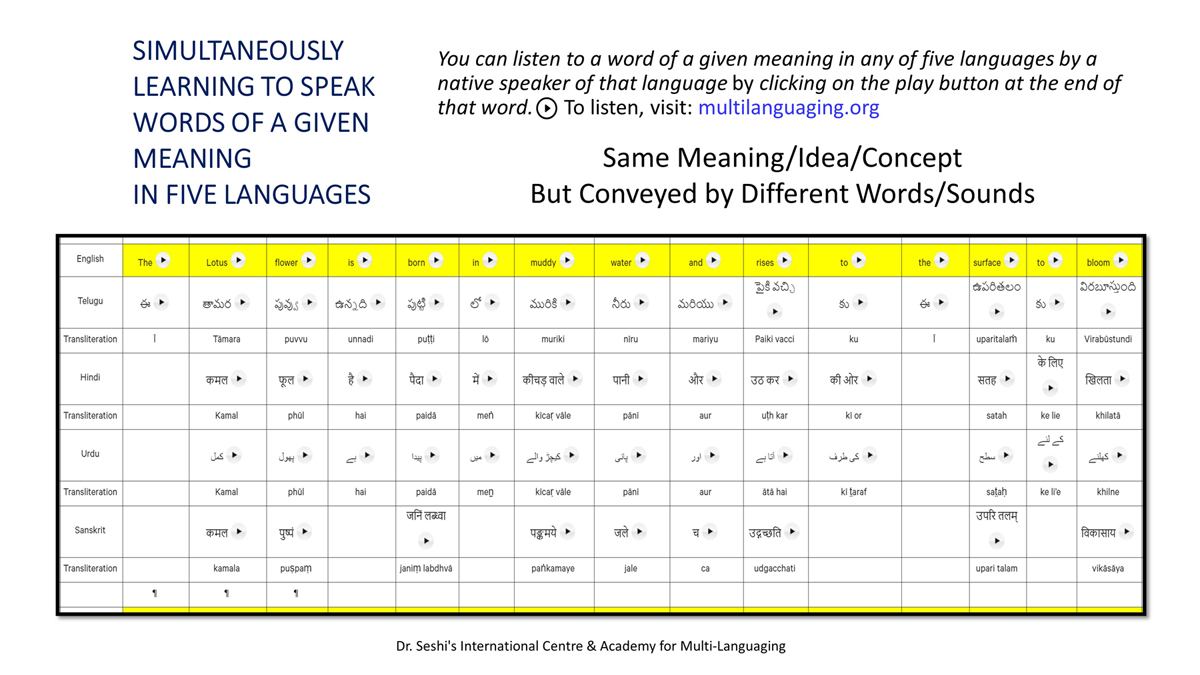
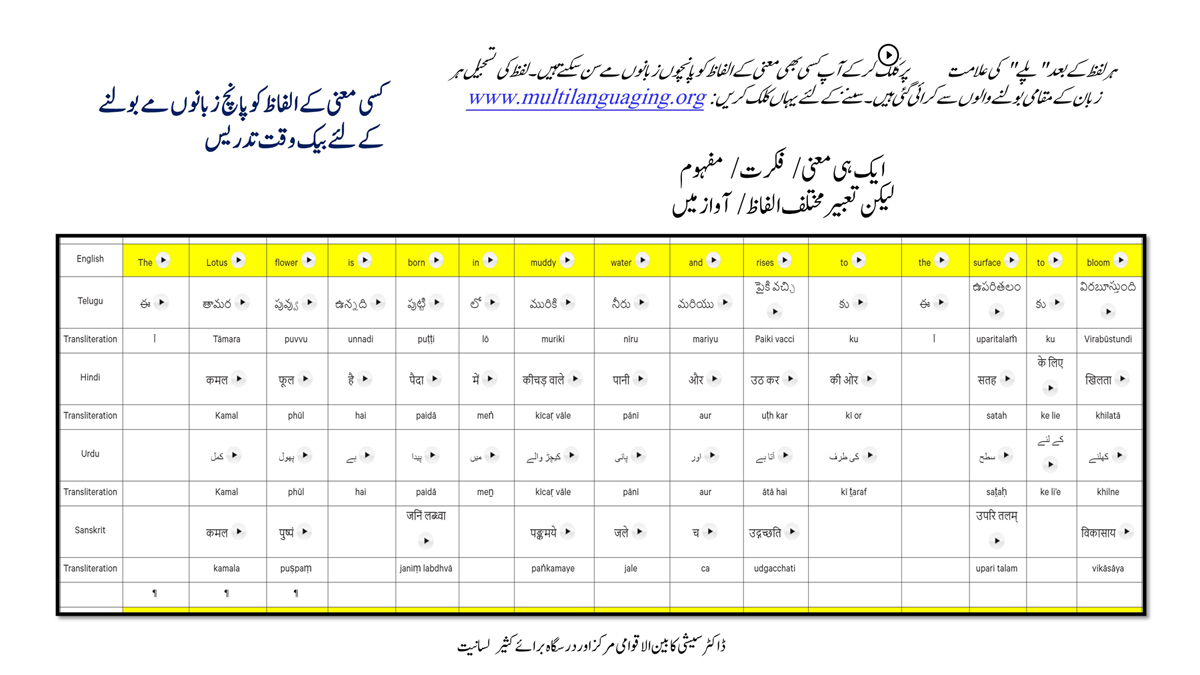
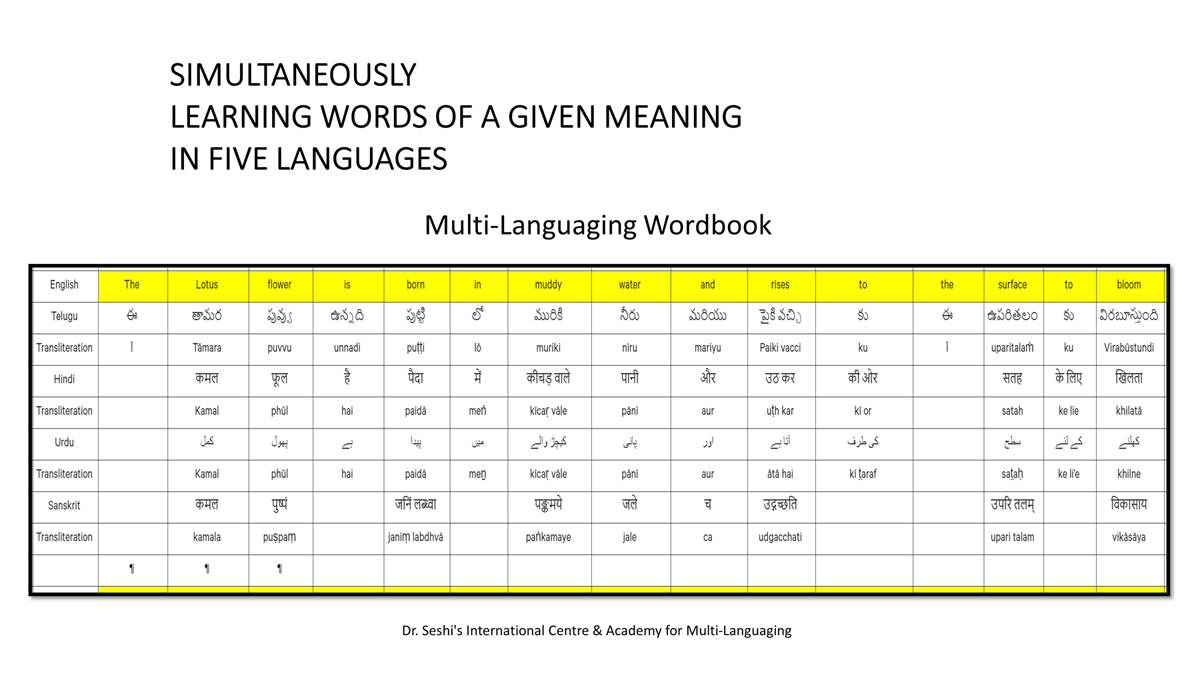
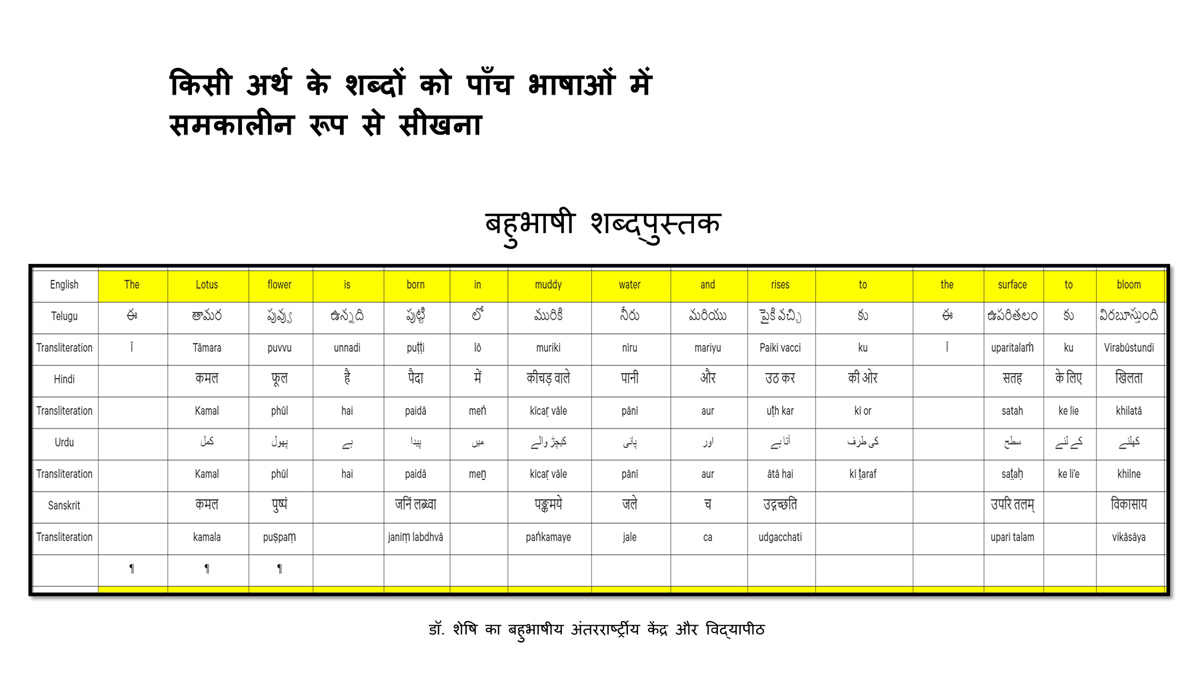
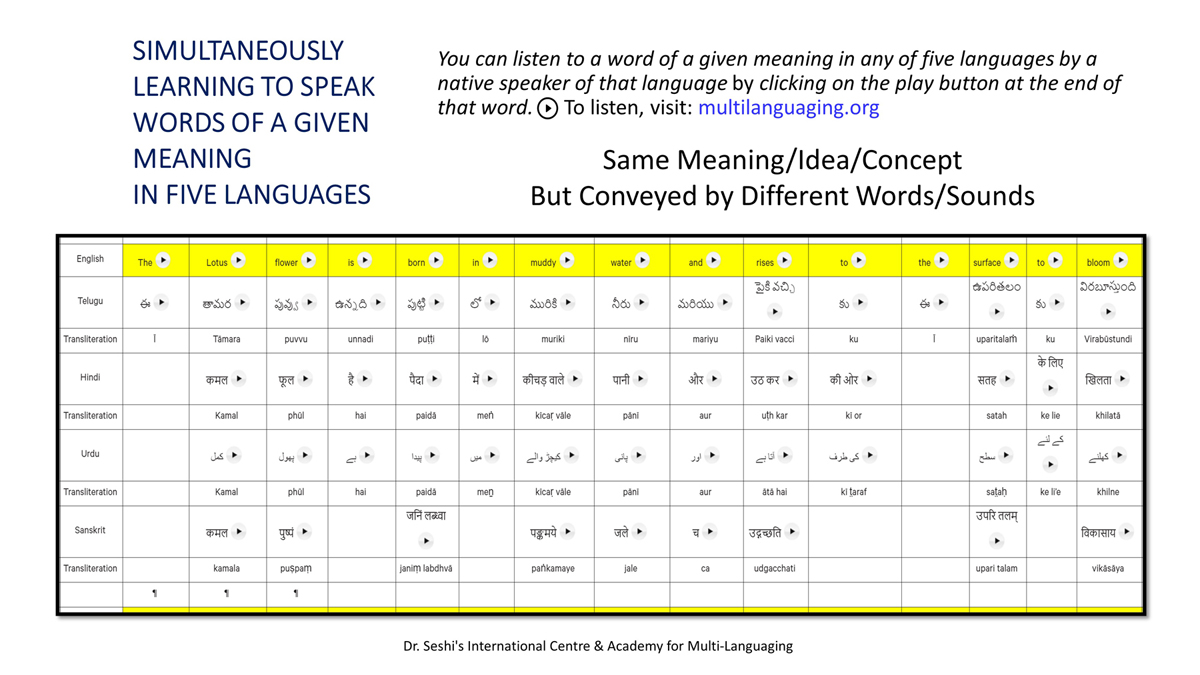
The accompanying section on "Alphabet Charts Showing Word-Level Mapping" presents the alphabet charts of five languages as children would traditionally learn them in a given language, by associating each letter with an example word that typically starts with that letter and is represented by a concrete image.
"الفاظ کی سطح کی نقشہ سازی دکھائے جانے والے حروف تہجی کے خرائط " پر ساتھ والے حصے میں پانچ زبانوں کے حروف تہجی کے خرائط اسی انداز میں پیش کیے گئے ہیں جیسے بچے روایتی طور پر ان کو ایک مخصوص زبان میں سیکھتے ہیں، ہر حرف کو ایک مثال کے لفظ کے ساتھ جوڑ کر جو عام طور پر اس حرف سے شروع ہوتا ہے اور ٹھوس شبیہ کی صورت میں اس کی نمائندگی کرتا ہے۔
"alfāz̤ kī sat̤aḥ kī naqshah sāzī dikhā’e jāne vāle ḥurūf-i tahajjī ke ḵẖarā’it̤" par sāth vāle ḥiṣṣe men̠ pān̠c zubānon̠ ke ḥurūf-i tahajjī ke ḵẖarā’it̤ isī andāz men̠ pesh kiye ga’e hain̠ jaise bacce rivāyatī t̤aur par un ko ek maḵẖṣūṣ zubān men̠ sīkhte hain̠, har ḥarf ko ek mis̱āl ke lafz̤ ke sāth joṛ kar jo ʿām t̤aur par us ḥarf se shurūʿ hotā hai aur ṭhos shabīh kī ṣūrat men̠ us kī numā’indgī kartā hai.
¶
The targeted students will be pre-school children, ages 3-5 years.
ہدف کردہ طلباء 3 سے 5 سال تک کے پری اسکول کے بچے ہوں گے۔
Hadaf kardah t̤albā 3 se 5 sāl tak ke prī iskūl ke bacce hon̠ ge.
¶
Importantly, to allow for comparative/correlative thinking and learning by their "absorbent minds," this section simultaneously introduces familiarity with the corresponding example words by translating them from each language into the remaining four languages.
اہم بات یہ ہے کہ، ان کے "جاذب ذہنوں" کے ذریعہ تقابلی/متعلقہ سوچ اور سیکھنے میں سہولت دینے کے لئے، یہ حصہ بیک وقت اسی متعلقہ مثال کے الفاظ سے ہر ایک کی زبان کو باقی چار زبانوں میں ترجمہ کرتے ہوئے اس سے متعارف کرواتا ہے۔
Ehem bāt yeh hai keh, un ke "jāẕib ẕehnon̠" ke ẕarīʿe taqābulī / mutaʿalliqah soc aur sīkhne men̠ sahūlat dene ke li’e, yeh ḥīṣṣah bayak vaqt usī mutaʿalliqah mis̱āl ke alfāz̤ se har ek kī zubān ko bāqī cār zubānon̠ men̠ tarjumah karte hu’e us se mutaʿārif karvātā hai.
The example word meanings elected to illustrate each language alphabet are exclusive to that language, without overlapping.
ہر زبان کے حروف تہجی کو واضح کرنے کے لئے منتخب کردہ مثال کے الفاظ کے معنی، بغیر کسی عبور کے، اس زبان کے لئے خاص ہیں۔
Har zubān ke ḥurūf-i tahajjī ko vāẓeḥ karne ke li’e muntaḵẖab kardah mis̱āl ke alfāz̤ ke maʿnā, bag̠h̠air kisī ʿabūr ke, us zubān ke li’e ḵẖāṣ hain̠.
Considering that English, Telugu, Hindi, Urdu, and Sanskrit respectively have 26, 51, 57, 39, and 49 characters/letters, it allows for the inculcation of the young minds with the cultural value of a mosaic of 222 images/words/meanings in five different languages.
انگریزی، تیلگو، ہندی، اردو اور سنسکرت میں بالترتیب 26، 51، 57، 39، اور 49 علامات/حروف ہیں، اس پر غور کرتے ہوئے، یہ 222 تصاویر/الفاظ / معانی کی ایک فنکارانہ پیشکش ثقافتی قدر کے ساتھ نوجوان ذہنوں کو آمادہ کرتا ہے۔
Angrezī, telugū, hindī aur Sanskrit men̠ bittartīb 26, 51, 57, 39 aur 49 ʿalāmāt / ḥurūf hain̠, is par g̠h̠aur karte hu’e, yeh 222 taṣāvīr / alfāz̤ / maʿānī ek fankārānah peshkash s̱aqāftī qadr ke sāth naujavān ẕehnon̠ ko āmādah kartā hai.
By learning two example words instead of one for each character/letter, this number will increase twofold (making it a few over 440).
ہر ایک علامت/ حرف کے لئے ایک کے بجائے دو مثال کے الفاظ سیکھنے سے، اس کی تعداد میں دوگنا اضافہ ہوجائے گا (اس کی تعداد 440 سے زیادہ ہوجائے گی)۔
Har ek ʿalāmat / ḥarf ke li’e ek ke bajā’e do mis̱āl ke alfāz̤ sīkhne se, is kī taʿdād men̠ do gunā iẓāfah ho jā’e gā (us kī taʿdād 440 se zyādah ho jā’e gī).
This expanded scope allows the introduction of additional new meanings/concepts/ideas, especially as they may relate to the cultural mores of these languages, to the formative minds further than the standard lists of words that have been in vogue for decades would allow.
اس وسعت والے دائرہ کار سے اضافی نئے معانی/ تصورات/ خیالات تخلیقی ذہنوں سے متعارف کرائے جا سکتے ہیں، خاص طور پر جب وہ ان زبانوں کے ثقافتی وسائل سے متعلق ہو سکتے ہیں، اور یہ تعارف لفظوں کی معیاری فہرستوں ، جو ابتدائی عشروں سے رواں دواں ہیں ، سے کہیں زیادہ متعلق ہو سکتا ہے۔
Is vusʿat vāle dā’ira-yi kār se iẓāfī na’e maʿānī / taṣavvurāt / ḵẖayālāt taḵẖlīqī ẕehnon̠ se mutaʿārif karā’e jā sakte hain̠, ḵẖāṣ t̤aur par jab voh un zubānon̠ ke s̱aqāftī vasā’il se mutaʿalliq ho sakte hain̠, aur yeh taʿāruf lafz̤on̠ kī meʿyārī fehriston̠, jo ibtedā’ī ʿashron̠ se ravān̠ davān̠ hain̠, se kahīn̠ zyādah mutaʿalliq ho saktā hai.
¶
To facilitate reference and learning, I have organized these charts, 1-5, laid out horizontally from left to right―English, Telugu, Hindi, Urdu, and Sanskrit.
حوالے اور سیکھنے کی سہولت کے لئے، میں نے―انگریزی، تیلگو، ہندی، اردو اور سنسکرت کے بائیں جانب سے افقی طور پر رکھے ہوئے ان خرائط کو، 1-5 تک ترتیب دیا ہے۔
ḥavāle aur sīkhne kī sahūlat ke li’e main̠ ne – angrezī, telugū, hindī, urdū aur Sanskrit ke bā’en̠ jānib se ufqī t̤aur par rakhe hu’e ḵẖarā’it̤ ko 1-5 tak tartīb diyā hai.
In future pictorial examples, voice-overs and animations will be portrayed by employing fictional teachers, like:
مستقبل کی تصویری مثالوں مے ، صوتی اور متحرک تصاویر کا تصور خیالی اساتذہ کے طور پر پیش کیا جائے گا ، جیسے کہ:
Mustaqbil kī taṣvīrī mis̱ālon̠ me, ṣautī aur mutaḥarrik taṣāvīr kā taṣvvur ḵẖayālī asātiẕah ke t̤aur par pesh kiyā jā’e gā, jaise keh:
¶
Ms. Saroja (for Sarojini Naidu – English)
محترمہ سروجا (سروجینی نائیڈو کے لئے – انگریزی)
Moḥtarmah Sarojā (sarojinī nā’iḍū ke li’e – angrezī)
Mr. Vema (for Vemana – Telugu)
جناب ویما (ویمنا کے لئے – تلوگو)
Janāb vemā (vemanā ke li’e – telugū)
Mr. Prem (for Premchand – Hindi)
جناب پریم (پریم چند کے لئے – ہندی)
Janāb prem (prem cand ke li’e – hindī)
Mr. Mirza (for Ghalib – Urdu)
جناب مرزا (غالب کے لئے – اردو)
Janāb mirza (g̠h̠ālib ke li’e – urdū)
Mr. Kalidas (for Kalidasa – Sanskrit)
جناب کالیداس (کالیڈاسا کے لئے – سنسکرت)
Janāb kālīdās (kālīdāsā ke li’e – Sanskrit)
¶
Mix-and-match letter and/or word games and exercises will be created with the objective of integrating the knowledge of all five language alphabets learned.
مرکب اور مشابہ حرف اور/یا الفاظ کے کھیل اور مشقیں تخلیق کی جائیں گی، جس کا مقصد سیکھے گئے پانچوں زبان کےحروف تہجی کے علم کو اکٹھا کرنا ہے ۔
Murakkab aur mushābeh ḥurūf aur / yā alfāz̤ ke khel aur mashqen̠ taḵẖlīq kī jā’en̠ gī, jis kā maqṣad sīkhe ga’e pān̠con̠ zubān ke ḥurūf-i tahajjī ke ʿilm ko ikhaṭṭhā karnā hai.
Envision a child with a mastery of the alphabets as outlined above, going to school feeling empowered, like a juggernaut or colossus, with full confidence.
درج بالا میں بیان کردہ حروف تہجی کی مہارت کے ساتھ، جگرنا ٹ یا ایک عظیم جثہ کی طرح، پورے اعتماد کے ساتھ بااختیار ہو کر اسکول میں جانے والے کسی بچے کا تصور کریں۔
Darj-i bālā men̠ bayān kardah ḥurūf-i tahajjī kī mahārat ke sāth, jagarnāṭ yā ek ʿaz̤īm jus̱s̱eh kī t̤araḥ, pūre eʿtemād ke sāth bā iḵẖtiyār ho kar iskūl men̠ jāne vāle kisī bacce kā taṣavvur karen̠.
¶
As we progress on this project, and as mentioned above and discussed under FAQ 13, we may need to write a smartphone app, prepare a video, or even create a video game treating the letters as human characters in a play, highlighting the similarities and differences between these alphabets.
ہم اس پروجیکٹ پر جیسے جیسے آگے بڑھ رہے ہیں، اور جیسا کہ اوپر ذکر کیا گیا ہے اور اکثر پوچھے گئے سوال 13 کے تحت بات چیت کی گئی ہے، کہ ہمیں اسمارٹ فون ایپ بنانے، ایک ویڈیو تیار کرنے یا حتی کہ ایک مماثلت کو اجاگر کرنے والے ایک ڈرامے میں حروف کو ان حروف کے مابین اختلافات اور یکسانیت کو ظاہر کرنے کے لئے انسانی کرداروں کی طرح پیش کرنے والا ویڈیو گیم بنانے کی ضرورت ہوسکتی ہے۔
Ham is projekṭ par jaise jaise āge baṛh rahe hain̠, aur jaisā keh ūpar ẕikr kiyā gayā hai aur aks̱ar pūche ga’e savāl 13 ke teḥet bāt cīt kī ga’ī hai, keh hamen̠ ismārṭ fon aip banāne, ek viḍiyo taiyār karne yā ḥattā ek mumās̱alat ko ujāgar karne vāle ek ḍrāme men̠ ḥurūf ko in ḥurūf ke mā bain iḵẖtilāfāt aur yaksāniyat ko z̤āhir karne ke li’e insānī kirdāron̠ kī t̤araḥ pesh karne vālā viḍiyo gem banāne kī ẓarūrat ho saktī hai.
Furthermore, lullabies or nursery rhymes focused on alphabets can be written and joyfully sung.
مزید برآں، حروف تہجی پر مرکوز کردہ لوریوں یا نرسری کی نظموں کو لکھا جاسکتا ہے اور خوشنما انداز مے گایا جاسکتا ہے۔
Mazīd bar ān̠, ḥurūf-i tahajjī par markūz kardah loriyon̠ yā narsarī naz̤mon̠ ko likhā jā saktā hai aur ḵẖushnumā andāz me gāyā jā saktā hai.
This will help achieve the comparative teaching of these alphabets with a hilarious effect.
اس سے ایک زندہ دل اثر کے ساتھ ان حروف تہجی کی تقابلی تعلیم حاصل کرنے میں مدد ملے گی۔
Is se ek zindah dil as̱ar ke sāth in ḥurūf-i tahajjī kī taqābulī taʿlīm ḥāṣil karne men̠ madad mile gī.
Ultimately, this multi-languaging project is expected to promote the preservation of the diversity of scripts and languages from extinction, as they embody an integral part of human culture and history.
آخر کار، اس کثیر لسانی منصوبے سے توقع کی جاتی ہے کہ رسم الخط اور زبانوں کے تنوع کو معدوم ہونے سے بچایا جائے گا، کیونکہ وہ انسانی ثقافت اور تاریخ کا ایک لازمی جزو ہیں۔
Āḵẖirkār, is kas̱īr lisānī manṣūbe se tavaqqoʿ kī jātī hai keh rasmul ḵẖat̤ aur zubānon̠ ke tanavvuʿ ko maʿdūm hone se bacāyā jā’e gā, kyun̠keh voh insānī s̱aqāfat aur tārīḵẖ kā ek lāzmī juzū hain̠.
For now, it suffices to be able to see their close relatedness, or lack thereof.
فی الحال ، ان کی انتہائی قرابت یا اس کی کمی کو دیکھنے کے قابل ہونا کافی ہے۔
Filḥāl, un kī intihā’ī qarābat yā us kī kami ko dekhne ke qābil honā kāfī hai.
¶
The following transliteration (Romanization) schemes are used in this multi-languaging project:
اس کثیر لسانی منصوبے میں مندرجہ ذیل نقل حرفی اسکیموں کا استعمال کیا جاتا ہے۔
Is kas̱īr lisānī manṣūbe men̠ mundarijah-yi ẕail naql-i ḥarfī iskīmon̠ kā istaʿmāl kiyā jātā hai.
¶
Devanagari – Sanskrit: International Alphabet of Sanskrit Transliteration (IAST)
دیواناگری – سنسکرت: سنسکرت نقل حرفی کی بین الاقوامی حروف تہجی (IAST)
Devānāgrī – Sanskrit: Sanskrit naql-i ḥarfī kī bainal aqvāmī ḥurūf-i tahajjī (IAST)
Devanagari – Hindi: Library of Congress (LoC) system
دیواناگری۔ ہندی: لائبریری آف کانگریس (LoC) سسٹم
Devānāgrī – hindī: lā’ibrarī āf kāngres (LoC) sisṭam
Telugu: LoC system
تیلگو: (LoC) سسٹم
Telugū: (LoC) sisṭam
Urdu: LoC system
اردو: (LoC) سسٹم
Urdū: (LoC) sisṭam
¶
It may help to know that IAST and LoC systems are, in fact, similar.
یہ جاننا اہم ہے کہ حقیقت میں، IAST اور LoC سسٹم ایک جیسے ہیں۔
Yeh jānnā ehem hai keh ḥaqīqat men̠, IAST aur LoC sisṭam ek jaise hain̠.
¶
It is hoped that the above groundwork will pave the way as we progress toward implementing the idea of teaching scripts concurrently.
یہ امید کی جاتی ہے کہ مذکورہ بالا بنیادی کام اس وقت ہموار ہوجائے گا جب ہم رسم الخط کے بیک وقت تدریسی نظریے کے نفاذ کی جانب پیش قدمی کریں گے۔
Yeh ummīd kī jātī hai keh maẕkūra-yi bālā bunyādī kām us vaqt hamvār ho jā’en̠ ge jab ham rasmul ḵẖat̤ ke bayak vaqt tadrīsī naz̤arye ke nafāẕ kī jānib pesh qadmī karen̠ ge.
At this stage of the project, this "Introduction" on alphabetics is targeted primarily for adult learners, parents, teachers/educators, software developers, policy decision makers and interested citizens.
منصوبے کے اس مرحلے میں، حروف تہجی کے سائنس سے متعلق یہ "تعارف" کو بنیادی طور پر بالغ سیکھنے والوں، والدین، اساتذہ/معلمین، سافٹ ویئر ڈیویلپرز، پالیسی کے فیصلہ سازوں اور دلچسپی رکھنے والے شہریوں کے لئے بنایا جاتا ہے۔
Manṣūbe ke is marḥale men̠, ḥurūf-i tahajjī ke sā’ins se mutaʿalliq yeh "taʿāruf" ko bunyādī t̤aur par bālig̠h̠ sīkhne vālon̠, vālidain, asātiẕah / moʿallimīn, sāfṭ we’ar ḍevelaparz, pālisī ke faiṣlah sāzon̠ aur dilcaspī rakhne vāle shehriyon̠ ke li’e banāyā jātā hai.
This work undoubtedly will help prepare the appropriate tools (software or otherwise) needed for simultaneously teaching these scripts to pre-school children, which is the eventual goal.
یہ کام بلا شبہ پری اسکول کے بچوں کو بیک وقت ان رسم الخط کی تعلیم کے لئے درکار مناسب ذرائع (سافٹ ویئر یا کسی اور طرح) کی تیاری میں مدد دے گا، جو کہ حتمی مقصد ہے۔
Yeh kām bilā shubah prī iskūl ke baccon̠ ko bayak vaqt in rasmul ḵẖat̤ kī taʿlīm ke li’e darkār munāsib ẕarā’iʿ (sāfṭ we’ar yā kisī aur t̤araḥ) kī taiyārī men̠ madad de gā, jo keh ḥatmī maqṣad hai.
¶
Finally, it is important to keep in mind that the information presented is by no means complete and may not have addressed all the nuances and intricacies which are expected to be learned in classroom.
آخر میں یہ بات ذہن نشین ہونا ضروری ہے کہ پیش کردہ معلومات کسی بھی طرح سے مکمل نہیں ہے اور یہ عین ممکن ہے کہ اس میں ان تمام باریکیوں اور پیچیدگیوں پر بھی توجہ نہ دی جا سکی ہو جن کے بارے میں کلاس کے دوران سیکھے جانے کی توقع کی جاتی ہے۔
Āḵẖir men̠ yeh bāt ẕehn nashīn honā ẓarūrī hai keh pesh kardah maʿlūmāt kisī bhī t̤araḥ se mukammal nahīn̠ hai aur yeh ʿain mumkin hai keh is men̠ un tamām bārīkiyon̠ aur pecīdgiyon̠ par bhī tavajjoh nah dī jā sakī ho jin ke bāre men̠ kilās ke daurān sīkhe jāne kī tavaqqoʿ kī jātī hai.
See the accompanying "References" section for a detailed picture.
تفصیلی تصویر کے لئے ملحقہ "حوالہ جات" کا حصہ ملاحظہ کریں۔
Tafṣīlī taṣvīr ke li’e mulḥiqah "ḥavālah jāt" kā ḥiṣṣah mulāḥiz̤ah karen̠.
¶
Acknowledgment:
اظہار تشکر:
Iz̤-hār-i tashakkur:
I thank the anonymous linguists, Mr. SS and Mr. TS, for offering strong encouragement, critical review, and helpful comments in preparing the Alphabetics documents.
میں گمنام ماہر لسانیات، محترم SS اور محترم TS کا شکریہ ادا کرتا ہوں کہ انہوں نے حروف تہجی کے سائنس سے متعلق دستاویزات کی تیاری میں بھرپور حوصلہ افزائی، تنقیدی جائزے، اور مددگار تبصروں کی پیش کش کی۔
Main̠ gumnām māhir-i lisāniyāt, moḥtaram SS aur moḥtaram TS kā shukriyah adā kartā hūn̠ keh unhon̠ ne ḥurūf-i tahajjī ke sā’ins se mutaʿlliq dastāvīzāt kī taiyārī men̠ bhar pūr ḥauṣlah afzā’ī, tanqīdī jā’ize aur madadgār tabṣiron̠ kī pesh kash kī.
¶