"भाषा बदलो, और आप के विचार बदल जाएंगे।"
कार्ल अल्ब्रेक्ट

बीरेल्लि शेषि, एम.डी.
Alphabetics: An Attempt at Character Mapping Across the Scripts for Sanskrit/Hindi (Devanagari), Telugu, and Urdu (Nastaleeq)

Beerelli Seshi, M.D.
Introduction
By character mapping, I mean character-by-character or letter-by-letter translation across languages (such as English, Telugu, Hindi, Urdu, and Sanskrit).
अक्षर-मानचित्रण से मेरा तात्पर्य विभिन्न भाषाओं (जैसे अंग्रेज़ी, तेलुगु, हिंदी, उर्दू और संस्कृत) में
वर्ण-दर-वर्ण या अक्षर-दर-अक्षर अनुवाद का है।
Akshar-mānacitraṇ se merā tātparya vibhinn bhāshāoṅ (jaise angrezī, telugu, hindī aur Sanskrit) meṅ varṇa-dar-varṇa yā akshar-dar-akshar anuvād kā hai.
That is mapping the sounds of one language to others.
इसका अर्थ है एक भाषा का दूसरी भाषाओं के उच्चारण आवाज़ से मानचित्रण करना।
Isakā arth hai ek bhāshā kā dūsarī bhāshāoṅ ke uccāraṇ āvāz se mānacitraṇ karanā.
It is a converse of the word-by-word and sentence-by-sentence translations as they are implemented in this project.
यह इस परियोजना में उपयोगित शब्द-दर-शब्द और वाक्य-दर-वाक्य अनुवाद के रूप से उल्टा है।
Yah is pariyojanā meṅ upayogit śabd-dar-śabd aur vākya-dar-vākya anuvād ke rūp se ulaṭā hai.
While the conventional translations map meanings across languages, alphabetics maps sounds.
जहाँ पारम्परिक अनुवादों भाषाओं के बीच अर्थ का मानचित्रण करते हैं, वर्णानुक्रम विज्ञान में उच्चारण की आवाज़ों का मानचित्रण होता है।
Jahāṅ pāramparik anuvādoṅ bhāshāoṅ ke bīc arth kā mānacitraṇ karate haiṅ, varṇānukram vigyān meṅ uccāraṇ kī āvāzoṅ kā mānacitraṇ hotā hai.
Letter-level translation between languages may interchangeably be viewed as transliteration.
अक्षर के स्तर पर किए गए अनुवाद को वैकल्पिक रूप से लिप्यंतरण के रूप में भी देखा जा सकता है।
Akshar ke star par kie gae anuvād ko vaikalpik rūp se lipyantaraṇ ke rūp meṅ bhī dekhā jā sakatā hai.
¶
Just as word/sentence translation maps meanings/concepts/ideas, so too letter-by-letter translation maps the sounds of one language to another.
जैसे कि शब्द/वाक्य अनुवाद अर्थ/अवधारणा/विचार का मानचित्रण करते हैं, अक्षर-दर-अक्षर अनुवाद एक भाषा के उच्चारण को दूसरी भाषा के उच्चारण से प्रतिचित्रित करता है।
Jaise ki śabd/vākya anuvād arth/avadhāraṇā/vicār kā mānacitraṇ karate haiṅ, akshar-dar-akshar anuvād ek bhāshā ke uccāraṇ ko dūsarī bhāshā ke uccāraṇ se praticitrit karatā hai.
In a sense, the former is more a mental exercise dealing with objects or ideas represented by words/sentences, regardless of the sounds that accompany them, whereas the latter, in a sense, is more physical and sensory, dealing exclusively with the impression of the sound that is conveyed by the letter.
एक प्रकार से, जहाँ पहला वाला अधिकतर रूप से शब्दों और वाक्यों में वर्णित वस्तु या विचार से सम्बंधित मानसिक व्यायाम है जो संलग्न आवाज़ों से अचेत है, वहां दूसरा, एक रूप से, आम तौर पर शारीरिक और संवेदी है जो अक्षर के द्वारा अवगत किए गए उच्चारण के प्रभाव पर केन्द्रित है।
Ek prakār se, jahāṅ pahalā vālā adhikatar rūp se śabdoṅ aur vākyoṅ meṅ varṇit vastu yā vicār se sambandhit mānasik vyāyām hai jo saṅlagn āvāzoṅ se acet hai, vahāṅ dūsarā, ek rūp se, ām taur par śārīrik aur saṅvedī hai jo akshar ke dvārā avagat kie gae uccāraṇ ke prabhāv par kendrit hai.
¶
It may, at first thought, appear to be challenging and difficult for the students to have to learn alphabets of five languages.
संभावित रूप से, प्रारंभिक विचार में, छात्रों को पाँच भाषाओं की वर्णमाला सीखना देखने में चुनौतीपूर्ण और कठिन लग सकता है।
Sambhāvit rūp se, prārambhik vicār meṅ, chātroṅ ko pāṅc bhāshāoṅ kī varṇamālā dekhane meṅ cunautīpūrṇa aur kaṭhin lag sakatā hai.
However, it may not be as intimidating as it appears to be once the students start learning them.
तथापि, एक बार छात्र जब उन्हें सीखना शुरू करेंगे तब यह इतना डरावना नहीं होगा।
Tathāpi ek bār chātra jab unheṅ sīkhanā śurū karenge tab yah itanā ḍarāvanā nahīṅ hogā.
The purpose of the accompanying Excel worksheets is to highlight the kinship among these alphabets, contributing to their learnability.
संलग्न एक्सेल के कार्यपत्रक का उद्देश्य इन वर्णमालाओं के बीच की समानताओं को दर्शाना है जिस से उनकी अधिगम्यता में योगदान होगा।
Saṅlagn eksel ke kāryapatrak kā uddeśya in varṇamālāoṅ ke bīc kī samānatāoṅ ko darśānā hai jis se unakī adhigamyatā meṅ yogadān hogā.
¶
As many of the readers would know, Hindi and Sanskrit use the same script, Devanagari.
जैसे कि कई पाठको को ज्ञान होगा, हिंदी और संस्कृत एक ही लिपि, देवनागरी, का उपयोग करते हैं।
Jaise ki kaī pāṭhako ko gyān hogā, hindī aur Sanskrit ek hī lipi, devanāgarī, kā upayog karate haiṅ.
Although Telugu uses a different script, its alphabet is essentially identical to Devanagari.
हालाँकि तेलुगु अलग लिपि का उपयोग करती हैं, उसकी वर्णमाला मूल रूप से देवनागरी के समान है।
Hālāṅki telugu alag lipi kā upayog karatī haiṅ, usakī varṇamālā mūl rūp se devanāgarī ke samān hai.
This is not to trivialize the differences, but the THS alphabets are practically one alphabet.
विभिन्नता के महत्व को कम न करते हुए यह बताना आवश्यक है कि तेलुगु/हिंदी/संस्कृत (THS) वर्णमाला व्यावहारिक दृष्टि से एक समान हैं।
Vibhinnatā ke mahatva ko kam na karate hue yah batānā āvaśyak hai ki telugu/hindī/Sanskrit (THS) varṇamālā vyāvahārik drushṭi se ek samān haiṅ.
The difference is that, while Sanskrit and Hindi use Devanagari script, Telugu uses a different script―the same sounds, but different scripts/representations.
अंतर यह है कि जहाँ संस्कृत और हिंदी देवनागरी लिपि का उपयोग करते हैं, तेलुगु अलग लिपि का उपयोग करती हैं―आवाज़ें वही लेकिन लिपियाँ/प्रतिरूप अलग।
Antar yah hai ki jahāṅ Sanskrit aur hindī devanāgarī lipi kā upayog karate haiṅ, telugu alag lipi kā upayog karati haiṅ – āvāzeṅ vahī lekin lipiyāṅ/pratirūp alag.
This concept of "same sound but different script symbol" is another visible form of India’s national motto, "Unity in Diversity"―"विविधतायामेकता"―"vividhatāyāmekatā".
"एक ही आवाज़ परन्तु अलग लिपि" की यह अवधारणा भारत के राष्ट्रीय आदर्श-वाक्य "विविधतायामेकता" का एक और प्रत्यक्ष रूप है।
"ek hī āvāz parantu alag lipi" kī yah avadhāraṇā bhārat ke rāshṭrīya ādarś-vākya "vividhatāyāmekatā" kā ek aur pratyaksh rūp hai.
The important message to be imparted to the children is that, although outward forms differ, the essence is the same―the same sound "a" is represented differently across scripts for Telugu, Sanskrit/Hindi, and Urdu―అ, अ/अ, and ا.
बच्चों को यह समझाना महत्वपूर्ण है कि अगर बाहरी रूप अलग भी हो, मूल तब भी वही है―तेलुगु, संस्कृत/हिंदी, और उर्दू में एक ही उच्चारण "a" ("अ") अलग अलग रूप में दर्शाएँ जाते हैं: అ, अ/अ, और ا.
Baccoṅ ko yah samajhānā mahatvapūrṇa hai ki agar bāharī rūp alag bhī ho, mūl tab bhī vahī hai – telugu, sanskrit/hindī aur urdū meṅ ek hī uccāraṇ "a" alag alag rūp meṅ darśāeṅ jāte haiṅ: అ, अ/अ, aur ا.
¶
This could be achieved in an imaginative and entertaining manner through visual media, especially videos or smartphone apps for children.
इसे एक कल्पनाशील और मनोरंजक तरीके से दृश्य माध्यम, और विशेष रूप से बच्चों के लिए बनाए गए वीडियो या स्मार्टफोन ऐप, द्वारा प्राप्त किया जा सकता है।
Ise ek kalpanāśīl aur manoranjak tarīke se druśya mādhyam, aur viśesh rūp se baccoṅ ke lie banāe gae vīḍiyo yā smārṭfon aip, dvārā prāpt kiyā jā saktā hai.
It will be equally instructive for adult learners, as it would convey a powerful message of underlying sameness hidden by outwardly different form.
यह वयस्क शिक्षार्थियों के लिए उतना ही शिक्षाप्रद होगा क्योंकि इसमें से भिन्न बाहरी रूप से छिपी हुई अन्तर्निहित समानता का शक्तिशाली सन्देश प्रकट होता है।
Yah vayask śikshārthiyoṅ ke lie utanā hī śikshāprad hogā kyoṅki isameṅ se bhinn bāharī rūp se chipī huī antarnihit samānatā kā śaktiśālī sandeś prakaṭ hotā hai.
Moreover, it will emphasize the fact that all these languages are intimately connected to each other either as mother-daughter or as sisters/cousins.
इसके अतिरिक्त, इन भाषाओं का एक दूसरे से या तो माँ-बहन जैसा और या बहनों/चचेरी बहनों जैसा अंतरंग संबंध इस विधि के द्वारा बल देकर दर्शाया जाएगा।
Isake atirikt, in bhāshāoṅ kā ek dūsare se yā to māṅ-bahan jaisā aur yā bahanoṅ/cacerī bahanoṅ jaisā antarang sambandh is vidhi ke dvārā bal dekar darśāyā jāegā.
I have also endeavored to convey this message while answering the FAQs, especially FAQ 3 and FAQ 10.
मैंने भी अधिक पूछे जाने वाले प्रश्न ३ और अधिक पूछे जाने वाले प्रश्न 10 में इस सन्देश को व्यक्त करने का प्रयास किया है।
Maiṅne bhī adhik pūche jāne vāle praśn 3 aur adhik pūche jāne vāle praśn 10 meṅ is sandeś ko vyakt karane kā prayās kiyā hai.
¶
In fact, alphabetics makes this point rather more emphatically than the vocabulary/words of these languages.
वास्तव में, वर्णानुक्रम विज्ञान इस तर्क को इन भाषाओं के शब्दावली / शब्द की तुलना में अधिक सशक्त ढंग से रखता है।
Vāstav meṅ, varṇānukram vigyān is tark ko in bhāshāoṅ ke śabdāvalī / śabd kī tulanā meṅ adhik saśakt ḍhang se rakhatā hai.
With words, we see that an identical word may sometimes have a different sense or a more nuanced sense in different languages (sometimes leading to confusion in translations) due to the passage of time and variance from the source.
शब्दों में, हम देखते हैं कि समय बीतने और स्रोत से विचरण के कारण समान शब्द का कभी कभी दूसरी भाषाओं में अलग या सूक्ष्म भेद युक्त अर्थ बन जाता है (जिस से अनुवाद में कभी कभी भ्रम की स्थिति उत्पन्न होती है)।
Śabdoṅ meṅ, ham dekhate haiṅ ki samay bītane aur strot se vicaraṇ ke kāraṇ samān śabd kā kabhī kabhī dūsarī bhāshāoṅ meṅ alag yā sūksham bhed yukt arth ban jātā hai (jis se anuvād meṅ kabhī kabhī bhram kī sthiti utpann hotī hai).
However, the sounds remain the same, new sounds may be added, or some old ones omitted, but the alphabet remains unaltered to a very great extent, especially among THS languages.
परन्तु, आवाज़ें नहीं बदलती है; नइ आवाज़ें जुड़ सकती है और पुरानी ढल सकती है, लेकिन, विशेष रूप से तेलुगु/हिंदी/संस्कृत (THS) भाषाओं में, वर्णमाला बहुत हद तक स्थिर रहती है।
Parantu, āvāzeṅ nahīṅ badalatī hai; naī āvāzeṅ juṛ sakatī hai aur purānī ḍhal sakatī hai, lekin viśesh rūp se telugu/hindī/Sanskrit (THS) bhāshāoṅ meṅ, varṇamālā bahut had tak sthir rahatī hai.
Therefore, I cannot overemphasize the importance of learning and cherishing these alphabets.
इसलिए, मैं इन वर्णमालाओं को सीखने और इन पर ध्यान देने के महत्व को जितना बल दूँ कम है।
Isalie, maiṅ in varṇamālāoṅ ko sīkhane aur in par dhyān dene ke mahatva ko jitanā bal dūṅ kam hai.
¶
English uses the Latin/Roman alphabet, which to its credit is the easiest to learn.
अंग्रेज़ी भाषा लातीनी/रोमन वर्णमाला का उपयोग करती हैं, जो – इसके सौभाग्य से – सीखने में सब से आसान है।
Angrezī bhāshā lātīnī/roman varṇamālā kā upayog karatī haiṅ, jo – isake saubhāgya se – sīkhane meṅ sab se āsān hai.
The script that stands out in terms of difficulty is that of Urdu, which is based on a Perso-Arabic alphabet that is quite different from the Latin and THS alphabets.
फारसी-अरबी वर्णमाला पर आधारित उर्दू की लिपि सब से कठिन है, और यह लातीनी और तेलुगु/हिंदी/संस्कृत (THS) वर्णमाला से बिलकुल विभिन्न है।
Phārasī-arabī varṇamālā par ādhārit urdū kī lipi sab se kaṭhin hai, aur yah lātīnī aur telugu/hindī/Sanskrit (THS) varṇamālā se bilakul vibhinn hai.
On the other hand, although Urdu uses a different script from Hindi, their day-to-day language and grammar are basically identical.
दूसरी ओर, जहाँ उर्दू की लिपि हिंदी से भिन्न है, वहां दोनों भाषाओं की आम बोली और व्याकरण मूल रूप से समान है।
Dūsarī or, jahāṅ urdū kī lipi hindī se bhinn hai, vahāṅ donoṅ bhāshāoṅ kī ām bolī aur vyākaraṇ mūl rūp se samān hai.
¶
As outlined above, my point is that it is not like having to learn five unrelated languages or scripts, like Arabic, Chinese, Devanagari, Greek, and Yucatec Maya, for example.
जैसा कि ऊपर बताया गया, मेरा तर्क है कि यह पाँच असंबंधित भाषाएँ, उदाहरणार्थ अरबी, चीनी, देवनागरी, यूनानी और युकाटेक माया, सीखने जैसा नहीं है।
Jaisā ki ūpar batāyā gayā, merā tark hai ki yah pāṅc asambandhit bhāshāeṅ, udāharaṇārth arabī, cīnī, devanāgarī, yūnānī aur yukāṭek māyā, sīkhane jaisā nahīṅ hai.
¶
The accompanying "Alphabet Mapping Tables" section graphically highlights the relatedness of THUS alphabets.
संलग्न "वर्णमाला मानचित्रण तालिकाओं" का अनुभाग तेलुगु/हिंदी/उर्दू/संस्कृत (THUS) भाषाओं की वर्णमालाओं की संबंधता को दर्शाता है।
Saṅlagn "varṇamālā mānacitraṇ tālikāoṅ" kā anubhāg telugu/hindī/urdū/Sanskrit (THUS) bhāshāoṅ kī varṇamālāoṅ kī sambandhatā ko darśātā hai.
To encourage the new learner and ensure that he/she not be intimidated by the chaotic-appearing Urdu script, I have tried to organize the Urdu letters into various groupings showing the underlying visual pattern within each group.
नए शिक्षार्थी को प्रोत्साहित करने के लिए और यह सुनिश्चित करने के लिए कि वह अराजक दिखने वाली उर्दू लिपि से भयभीत न हो जाए, मैं ने उर्दू अक्षरों को विभिन्न समूहों में व्यवस्थित करने का प्रयास किया है जिस में हर समूह के अक्षरों के बीच के अन्तर्निहित दृश्य स्वरूप को दिखाया गया है।
Nae śikshārthī ko protsāhit karane ke lie aur yah suniścit karane ke lie ki vah arājak dikhane vālī urdū lipi se bhayabhīt na ho jāe, maiṅ ne urdū aksharoṅ ko vibhinn samūhoṅ me vyavasthit karane kā prayās kiyā hai jise meṅ har samūh ke aksharoṅ ke bīc ke antarnihit druśya svarūp ko dikhāyā gayā hai.
To facilitate the reference, learning, remembering and usage of the THUS alphabets, I have organized them in the form of ten tables laid out horizontally as in the accompanying "Alphabet Mapping Tables" section, from left to right:
तेलुगु/हिंदी/उर्दू/संस्कृत (THUS) भाषाओं की वर्णमालाओं के अध्ययन, सीखने, याद रखने और उपयोग को सुगम बनाने के लिए मैं ने उन्हें संलग्न "वर्णमाला मानचित्रण तालिकाओं" के अनुभाग के अंदाज़ में क्षितिज के समांतर दिशा में बनी दस तालिकाओं में बाएं से दाएं व्यवस्थित किया है:
Telugu/hindī/urdū/Sanskrit (THUS) bhāshāoṅ kī varṇamālāoṅ ke Adhyayan, sīkhane, yād rakhane aur upayog ko sugam banāne ke lie maiṅ ne unheṅ saṅlagn "varṇamālā mānacitraṇ tālikāoṅ" ke anubhāg ke andāz meṅ kshitij ke samāntar diśā meṅ banī das tālikāoṅ meṅ bāeṅ se dāeṅ vyayasthit kiyā hai:
¶
Table 1 – Devanagari and Telugu Vowels
तालिका १ – देवनागरी और तेलुगु स्वर
Tālikā 1 – devanāgarī aur telugu svar
Table 2 – Devanagari and Telugu Consonants
तालिका २ – देवनागरी और तेलुगु व्यंजन
Tālikā 2 – devanāgarī aur telugu vyanjan
Table 3 – Devanagari Consonant Clusters
तालिका ३ – देवनागरी व्यंजन समूह
Tālikā 3 – devanāgarī vyanjan samūh
Table 4 – Devanagari and Urdu Special Consonants
तालिका ४ – देवनागरी और उर्दू विशेष व्यंजन
Tālikā 4 – devanāgarī aur urdū viśesh vyanjan
Table 5 – Devanagari Hindi vs. Urdu Vowels
तालिका 5 – देवनागरी हिंदी बनाम उर्दू स्वर
Tālikā 5 – devanāgarī hindī banām urdū svar
Table 6 – Devanagari Hindi vs. Urdu Consonants
तालिका 6 – देवनागरी हिंदी बनाम उर्दू व्यंजन
Tālikā 6 – devanāgarī hindī banām urdū vyanjan
Table 7 – Devanagari vs. Urdu: Digraphs (Stressed Consonants/Aspirates)
तालिका 7 – देवनागरी बनाम उर्दू: महाप्राण व्यंजन
Tālikā 7 – devanāgarī banām urdū: mahāprāṇ vyanjan
Table 8 – Urdu Letters with Dots
तालिका 8 – नुक़्ता वाले उर्दू अक्षर
Tālikā 8 – nuqtā vāle urdū akshar
Table 9 – Urdu Letters Without Dots
तालिका 9 – बिना नुक़्ता वाले उर्दू अक्षर
Tālikā 9 – binā nuqtā vāle urdū akshar
Table 10 – Complete Urdu Alphabet in All Forms
तालिका १० – सभी रूपों में पूरी उर्दू वर्णमाला
Tālikā 10 – sabhī rūpoṅ meṅ pūrī urdū varṇamālā
¶
It is hoped that this will make it easier to learn, remember and use the alphabets in question.
आशा की जाती है कि इन तालिकाओं से सम्बंधित वर्णमालाओं को सीखने, याद रखने और उनका उपयोग करने में सरलता होगी।
Āśā kī jātī hai ki in tālikāoṅ se sambandhit varṇamālāoṅ ko sīkhane, yād rakhane aur unakā upayog karane meṅ saralatā hogī.
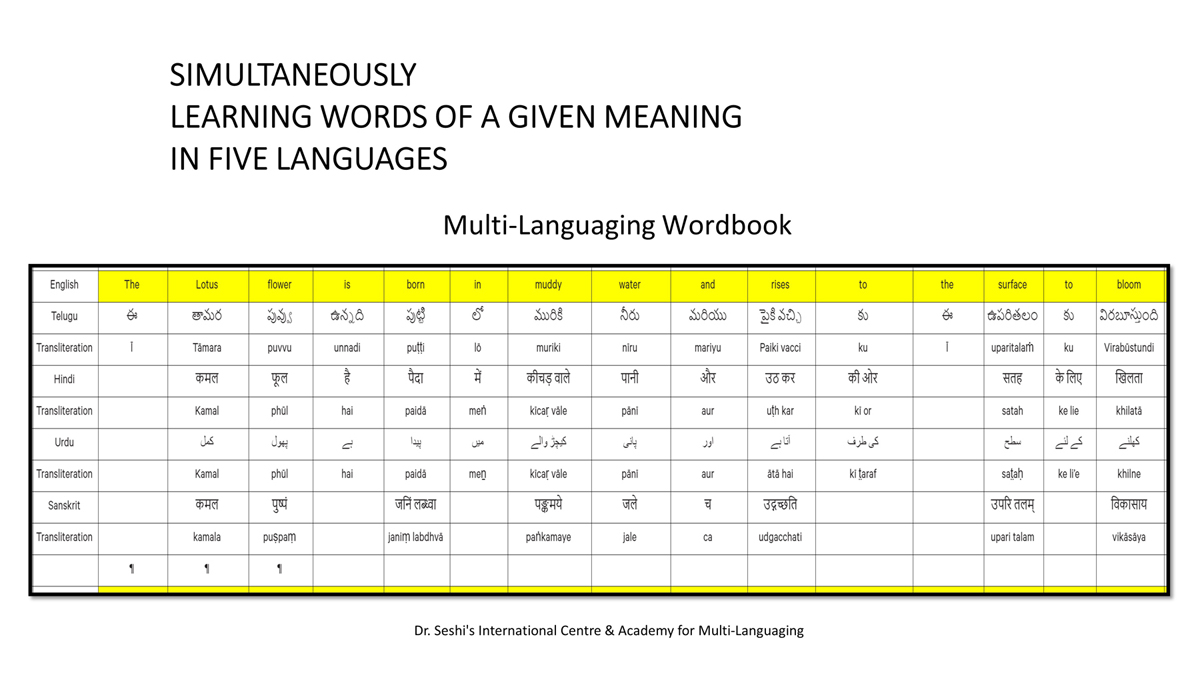
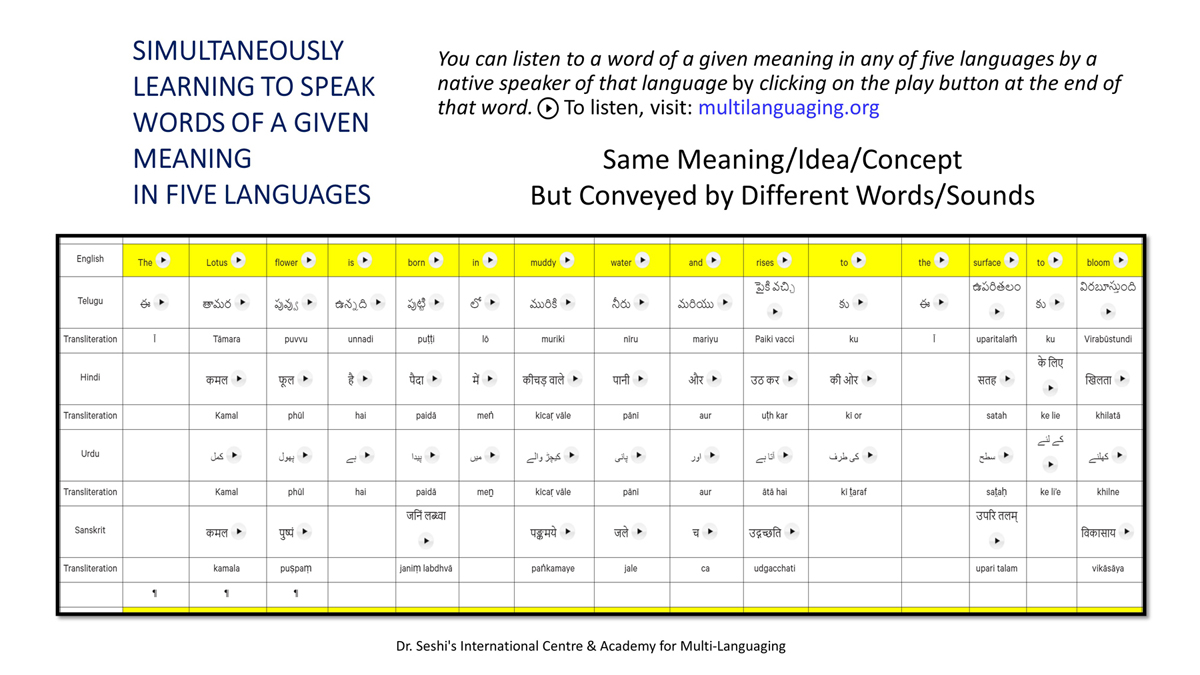
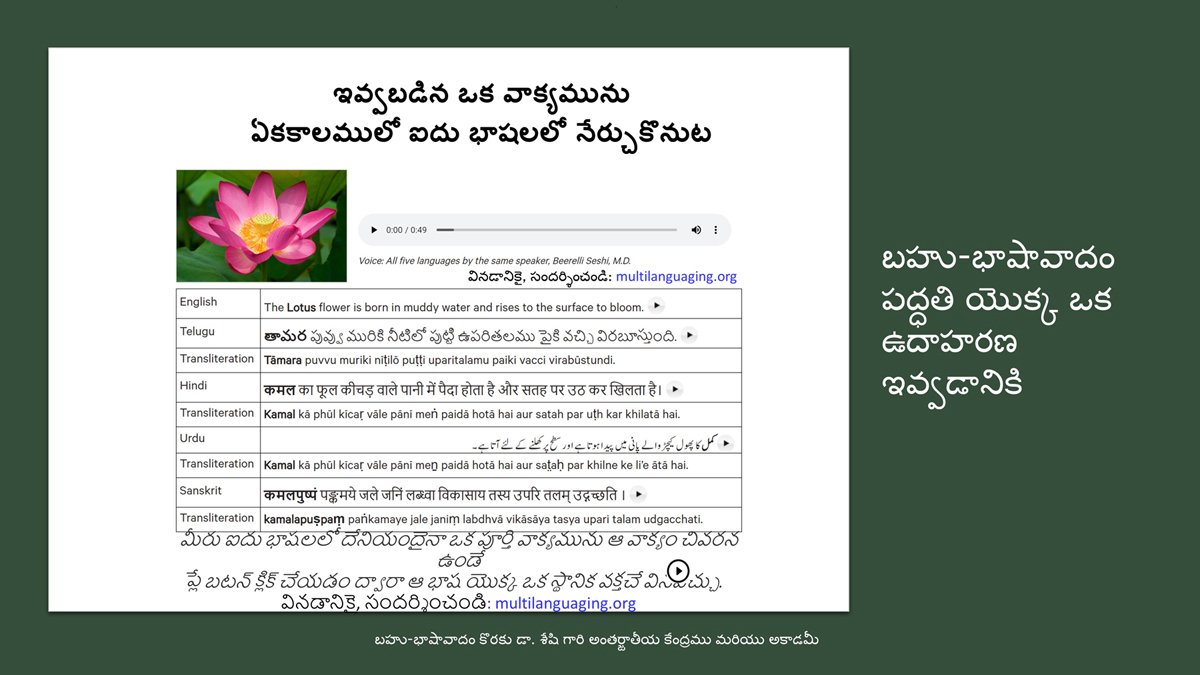
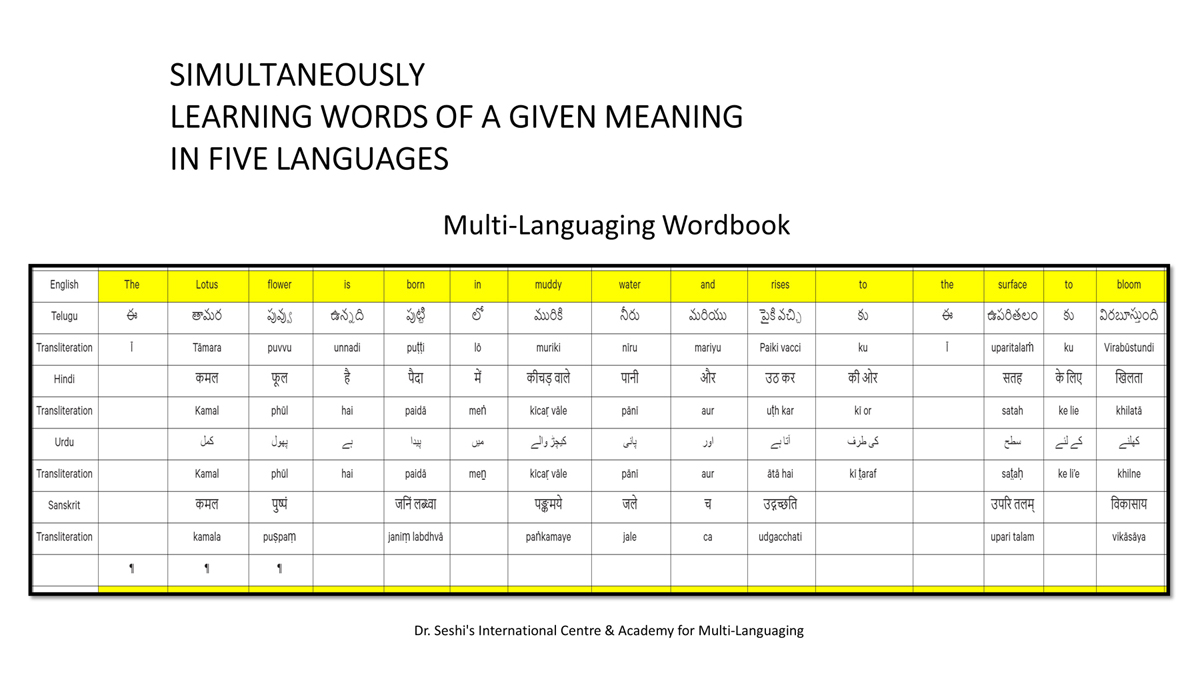
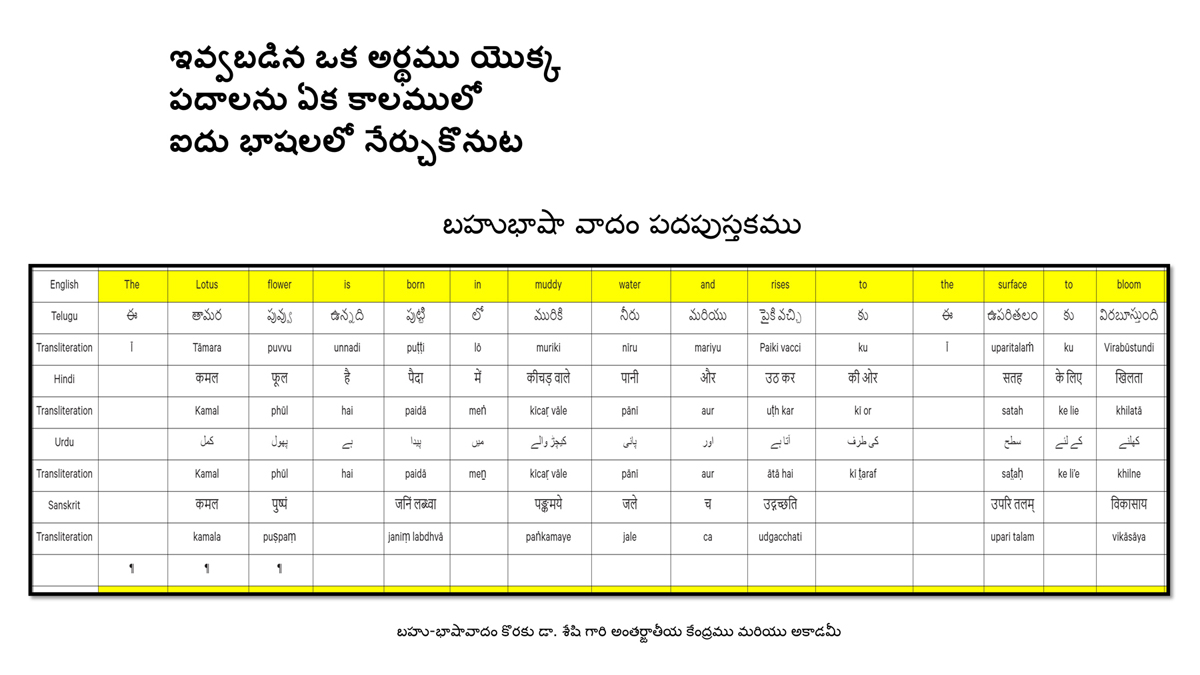
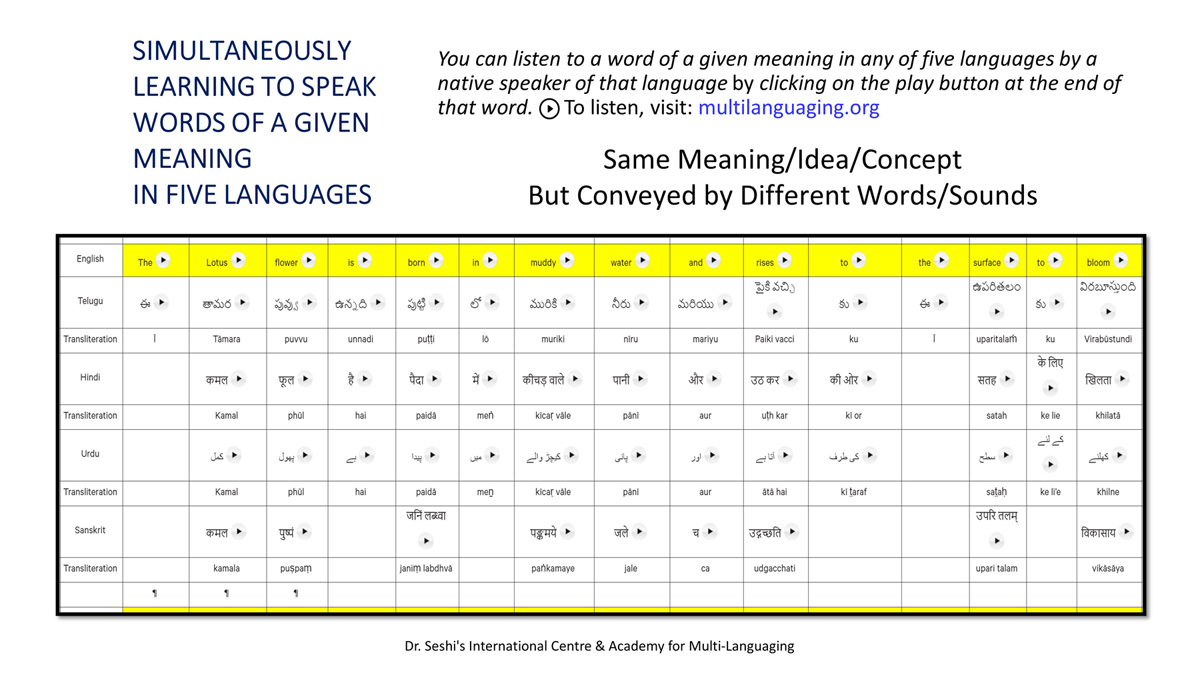
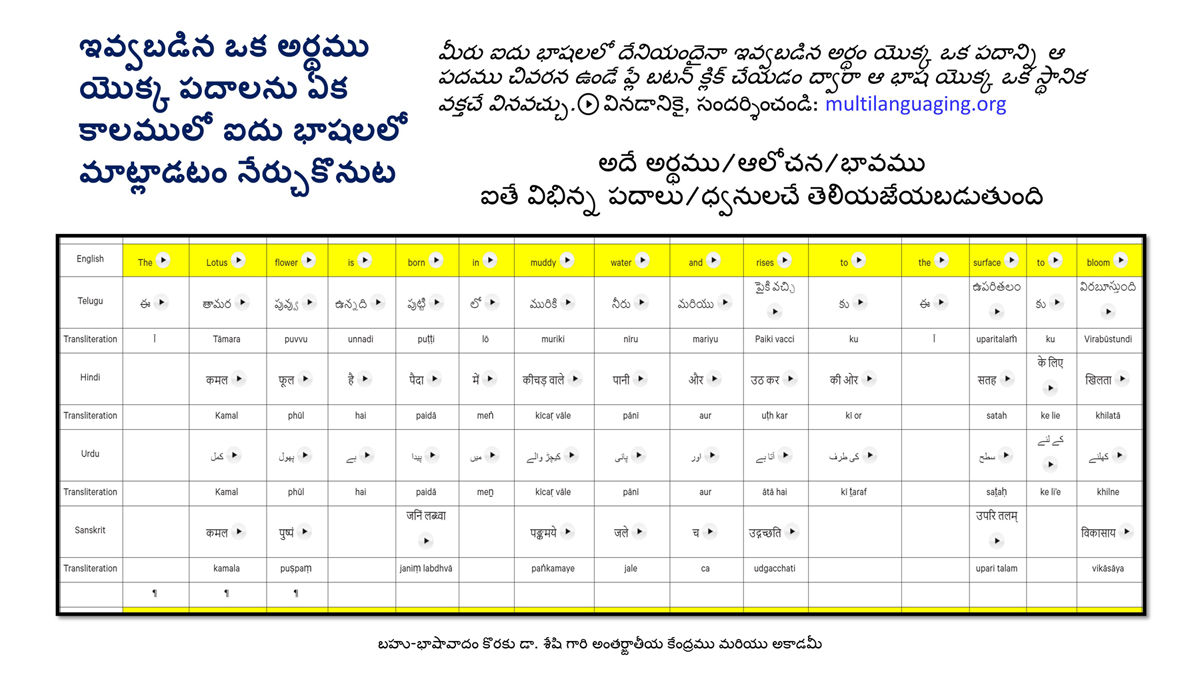
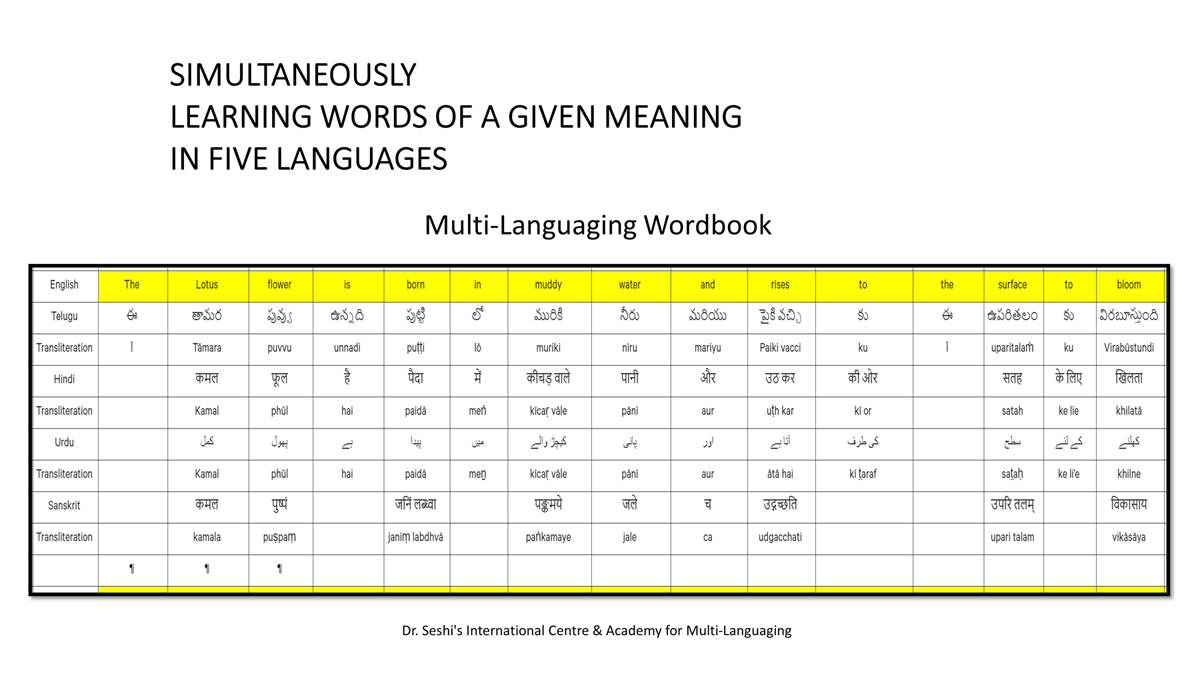
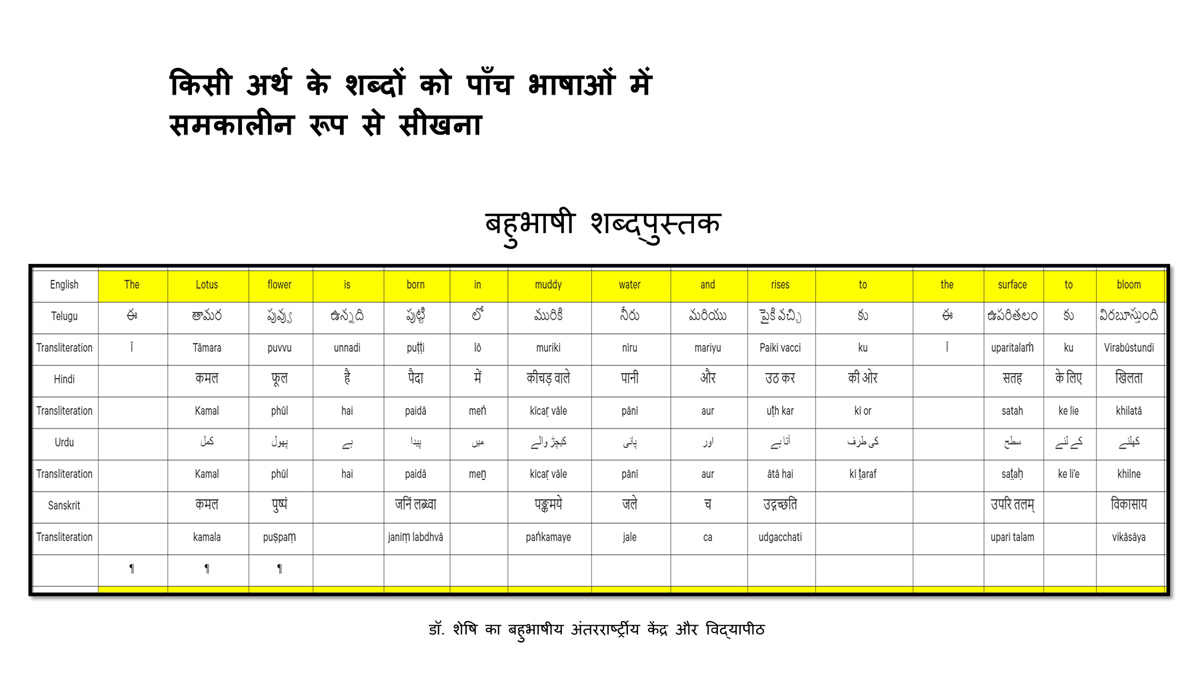
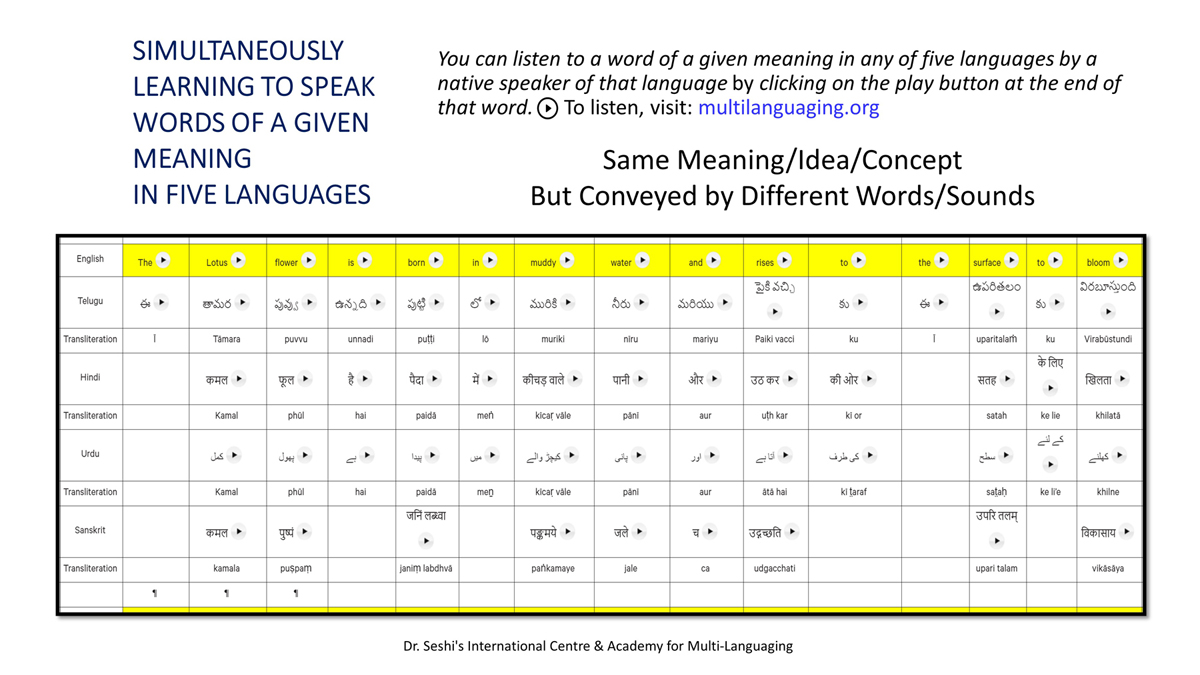
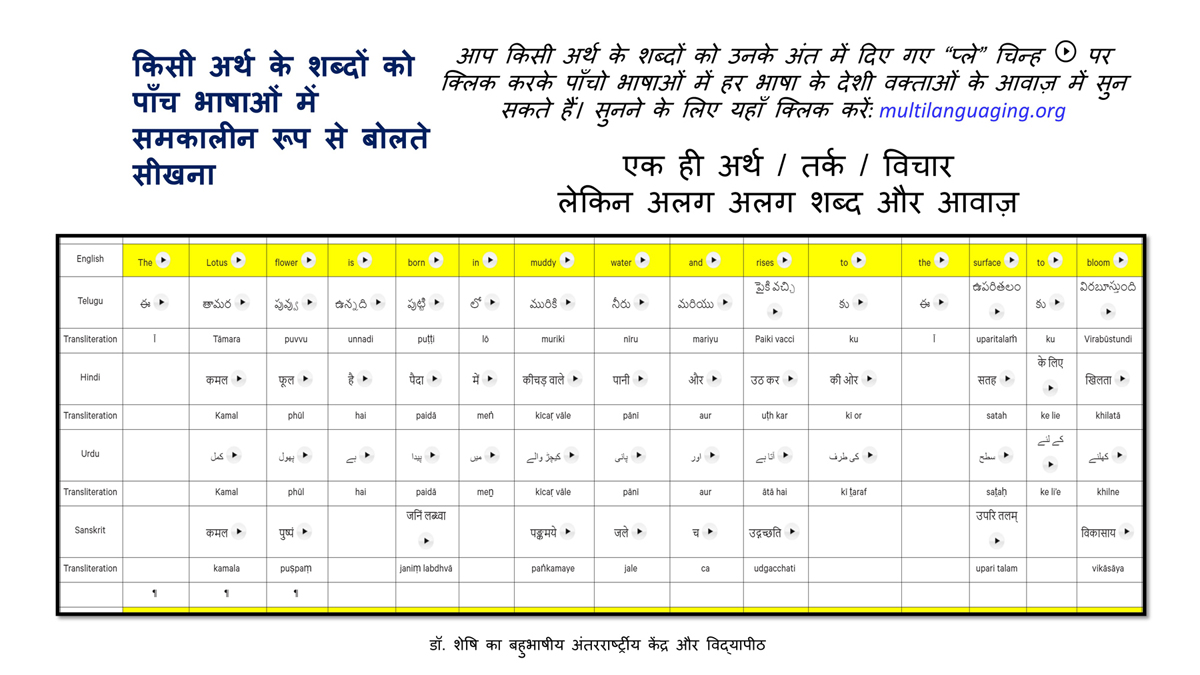
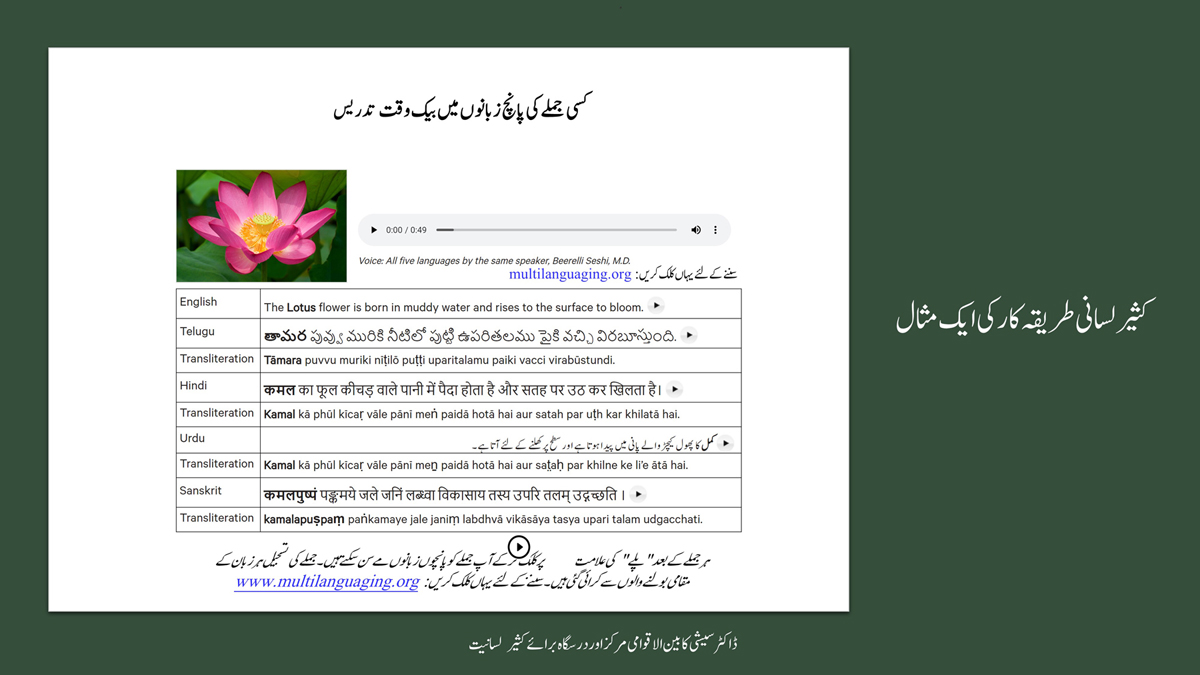
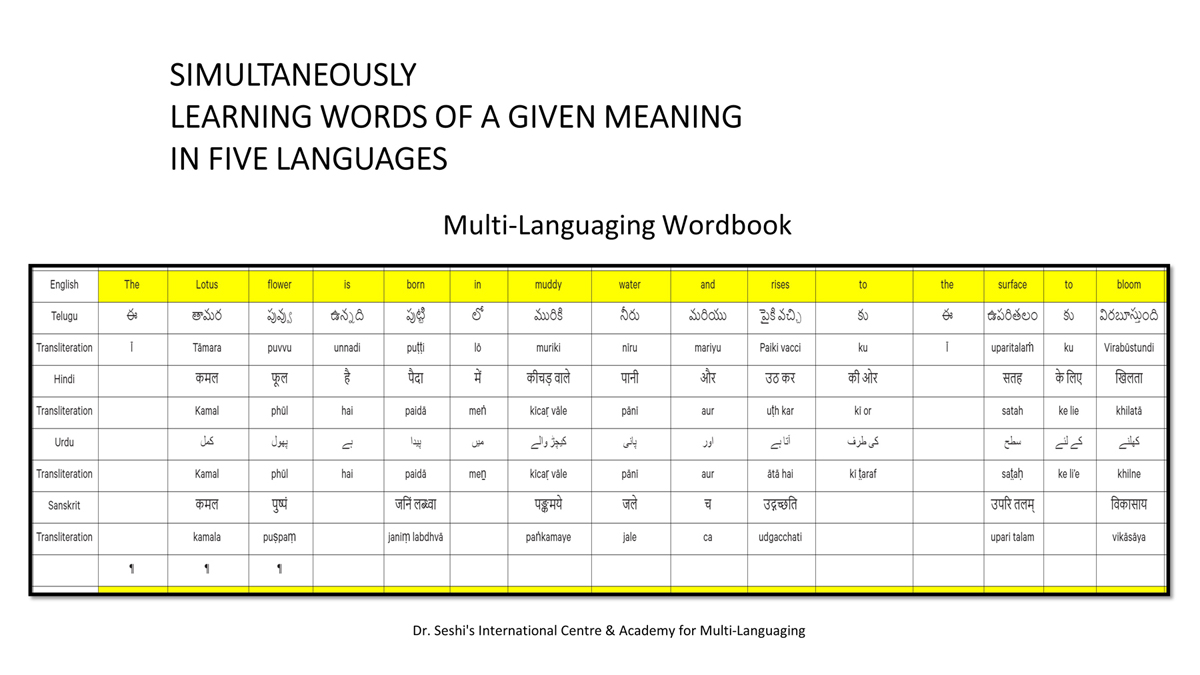
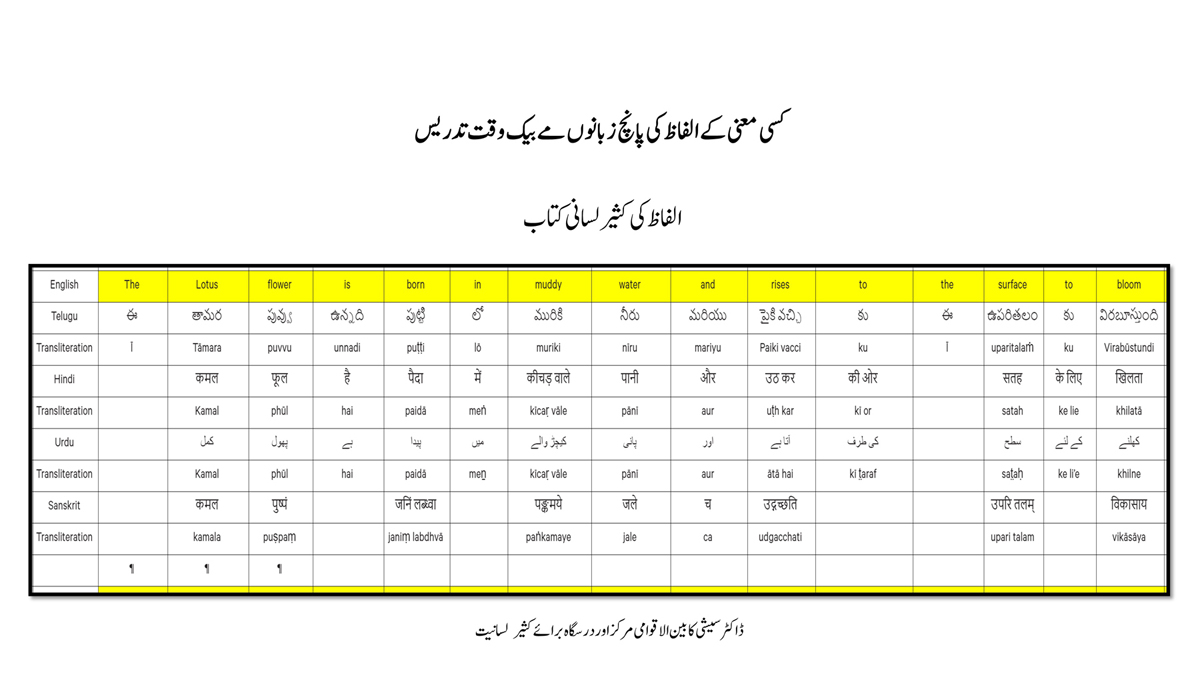
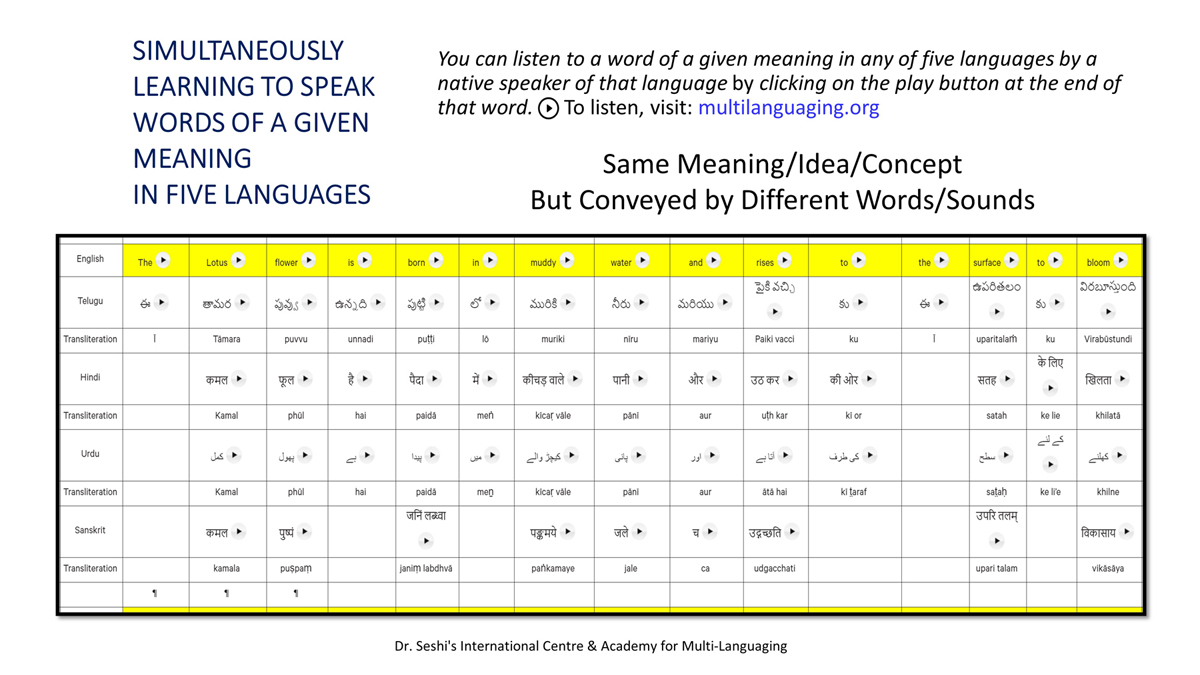
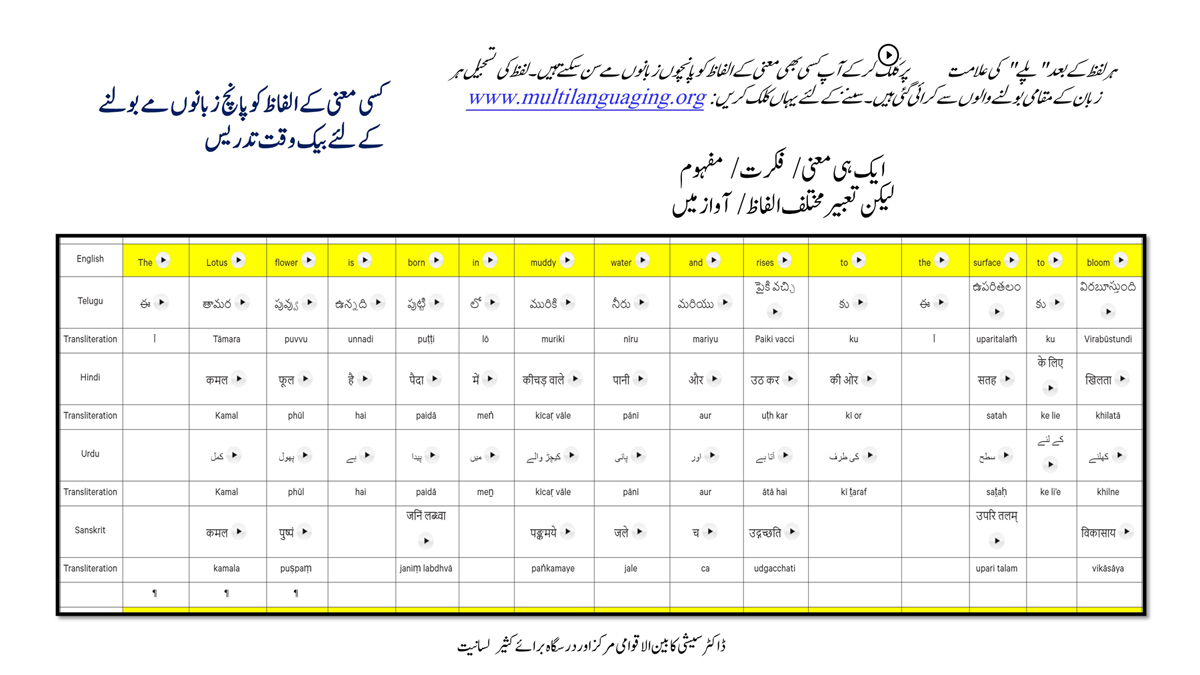
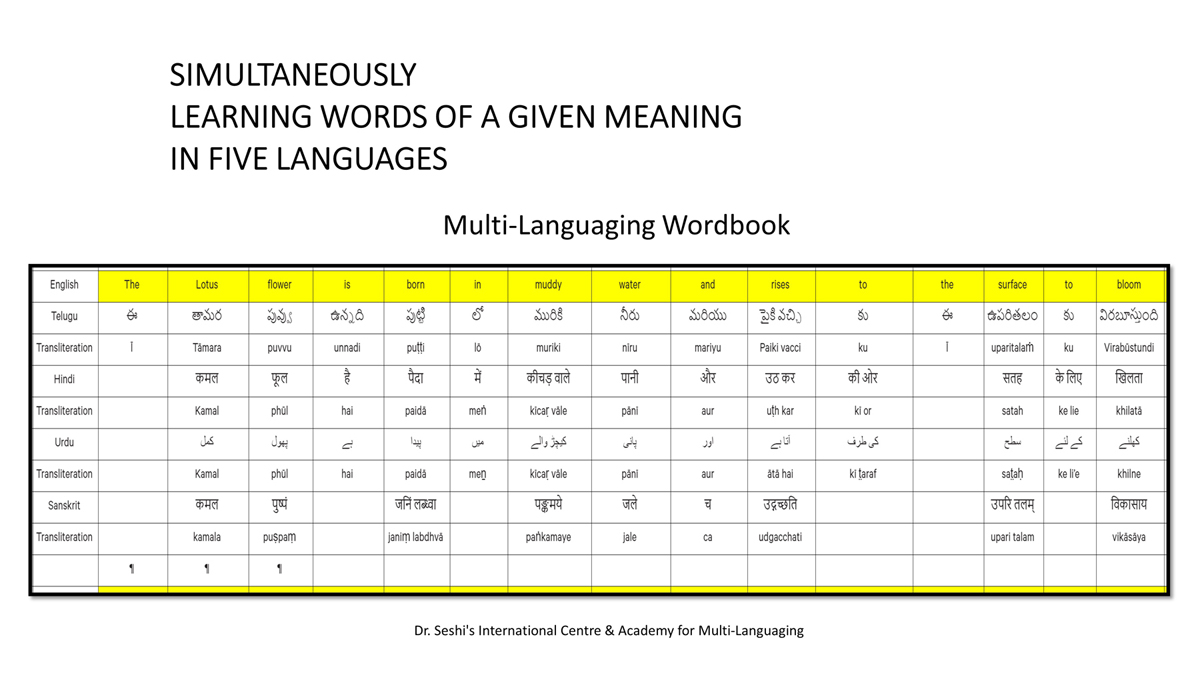
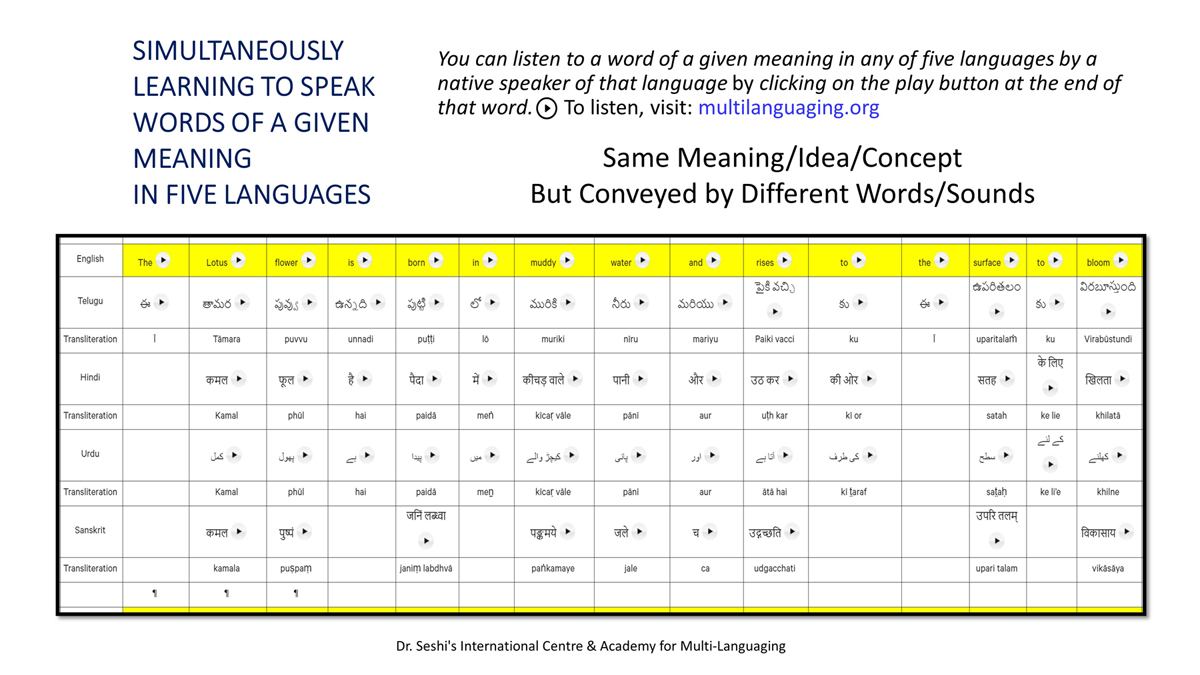
The accompanying section on "Alphabet Charts Showing Word-Level Mapping" presents the alphabet charts of five languages as children would traditionally learn them in a given language, by associating each letter with an example word that typically starts with that letter and is represented by a concrete image.
संलग्न "शब्द-स्तर का मानचित्रण दिखाने वाले वर्णमाला विवरणपट" पाँचो भाषाओं की वर्णमालाओं को उस रूप में उपस्थित करते हैं जैसे बच्चे पारंपरिक रूप से किसी भाषा को सीखते हो, अर्थात्, हर अक्षर को एक उदाहरण शब्द से जोड़ कर जो आम तौर पर उसी अक्षर से शुरू होता है और एक ठोस छवि के माध्यम से वर्णित किया जाता है।
Saṅlagn "śabd-star kā mānacitraṇ dikhāne vāle varṇamālā vivarṇpaṭ" pāṅcoṅ bhāshāoṅ kī varṇamālāoṅ ko us rūp meṅ upasthit karate haiṅ jaise bacce pāramparik rūp se kisī bhāshā ko sīkhate ho, arthāt, har akshar ko ek udāharaṇ śabd se joṛ kar ko ām taur par usī akshar se śurū hotā hai aur ek ṭhos chavi ke mādhyam se varṇit kiyā jātā hai.
¶
The targeted students will be pre-school children, ages 3-5 years.
लक्षित छात्र ३-५ वर्ष के उम्र वाले प्री-स्कूल के बच्चे होगे।
Lakshit chātra 3-5 varsh ke umra vāle prī-skūl ke bacce hoge.
¶
Importantly, to allow for comparative/correlative thinking and learning by their "absorbent minds," this section simultaneously introduces familiarity with the corresponding example words by translating them from each language into the remaining four languages.
महत्त्वपूर्ण रूप से, बच्चों के "शोषक मन" द्वारा तुलनात्मक/सहसंबंधी विचारशक्ति और शिक्षा को सुगम बनाने के लिए यह अनुभाग में एक साथ हर भाषा के उदाहरण शब्दों को परिचय हेतु अन्य चार भाषाओं में अनुवादित किया जाता है।
Mahatvapūrṇa rūp se, baccoṅ ke "śoshak man" dvārā tulanātmak/sahasambandhī vicāraśakti aur śikshā ko sugam banāne ke lie yah anubhāg meṅ ek sāth har bhāshā ke udāharaṇ śabdoṅ ko paricay hetu anya cār bhāshāoṅ meṅ anuvādit kiyā jātā hai.
The example word meanings elected to illustrate each language alphabet are exclusive to that language, without overlapping.
हर भाषा के अक्षरों को दर्शाने के लिए चयनित उदाहरण शब्द-अर्थ उस भाषा के लिए विशेष है; एक भाषा का उदाहरण शब्द किसी दूसरी भाषा की सूचि में नहीं पाया जाएगा।
Har bhāshā ke aksharoṅ ko darśāne ke lie cayanit udāharaṇ śabd-arth us bhāshā ke lie viśesh hai; ek bhāshā kā udāharaṇ śabd kisī dūsarī bhāshā kī sūci me nahīṅ pāyā jāegā.
Considering that English, Telugu, Hindi, Urdu, and Sanskrit respectively have 26, 51, 57, 39, and 49 characters/letters, it allows for the inculcation of the young minds with the cultural value of a mosaic of 222 images/words/meanings in five different languages.
यह देखते हुए कि अंग्रेज़ी, तेलुगु, हिंदी, उर्दू और संस्कृत में क्रमश: २६, ५१, ५७, ३९ और ४९ अक्षर है, इस से बच्चों के प्रगतिशील बुद्धि में २२२ चित्र/शब्द/अर्थ के सांस्कृतिक मूल्य वाली एक संयोजित तस्वीर बिठाई जाती हैं।
Yah dekhate hue ki angrezī, telugu, hindī, urdū aur Sanskrit meṅ kramashaha 26, 51, 57, 39 aur 49 akshar hai, is se baccoṅ ke pragatiśīl buddhi meṅ 222 citra/śabd/arth ke sānskrutik mūlya vālī ek saṅyojit tasvīr biṭhāī jātī haiṅ.
By learning two example words instead of one for each character/letter, this number will increase twofold (making it a few over 440).
हर अक्षर के दो उदाहरण शब्द सीखने से यह गिनती दुगनी हो जाती हैं (४४० से कुछ अधिक)।
Har akshar ke do udāharaṇ śabd sīkhane se yah ginatī duganī ho jātī haiṅ (440 se kuch adhik).
This expanded scope allows the introduction of additional new meanings/concepts/ideas, especially as they may relate to the cultural mores of these languages, to the formative minds further than the standard lists of words that have been in vogue for decades would allow.
यह विस्तारित दायरा अतिरिक्त रूप से बच्चों के रचनात्मक दिमागों में नए अर्थ/अवधारणा/विचार को स्थापित करने की अनुमति देता है, विशेषतः क्योंकि उनका सम्बन्ध इन भाषाओं के सांस्कृतिक परंपराओं के साथ जुड़ा है, और इसका प्रभाव दशकों से चली आ रहीं शब्दों की मानक सूचीयों से कई अधिक होगा।
Yah vistārit dāyrā atirikt rūp se baccoṅ ke racanātmak dimāgoṅ meṅ nae arth/avadhāraṇā/vicār ko sthāpit karane kī anumati detā hai, viśeshataha kyoṅki unakā sambandh in bhāshāoṅ ke sānskrutik paramparāoṅ ke sāth juṛā hai, aur isakā prabhāv daśakoṅ se calī ā rahīṅ śabdoṅ kī mānak sūcīyoṅ se kaī adhik hogā.
¶
To facilitate reference and learning, I have organized these charts, 1-5, laid out horizontally from left to right―English, Telugu, Hindi, Urdu, and Sanskrit.
अध्ययन और शिक्षण को आगे बढ़ाने के लिए मैं ने इन पाँच विवरणपटो – संख्या १ से ५ – को क्षितिज के समांतर दिशा में बाएं से दाएं व्यवस्थित किया है – अंग्रेज़ी, तेलुगु, हिंदी, उर्दू, और संस्कृत।
Adhyayan aur śikshaṇ ko āge baṛhāne ke lie maiṅ ne in pāṅc vivaraṇpaṭo – sankhyā 1 se 5 – ko kshitij ke samāntar diśā meṅ bāeṅ se dāeṅ vyavasthit kiyā hai – angrezī, telugu, hindī, urdū aur Sanskrit.
In future pictorial examples, voice-overs and animations will be portrayed by employing fictional teachers, like:
भविष्य में चित्रात्मक उदाहरण, पार्श्व आवाज़ और चंचल चित्र को काल्पनिक शिक्षको द्वारा चित्रित किया जाएगा:
Bhavishya meṅ citrātmak udāharaṇ, pārśav āvāz aur cancal citra ko kālpanik śikshako dvārā citrit kiyā jāegā:
¶
Ms. Saroja (for Sarojini Naidu – English)
श्रीमती सरोजा (सरोजिनी नायडू के लिए – अंग्रेज़ी)
Shrīmatī sarojā (sarojinī nayḍū ke lie – angrezī)
Mr. Vema (for Vemana – Telugu)
श्री वेमा (वेमना के लिए – तेलुगु)
Shrī vemā (vemanā ke lie – telugu)
Mr. Prem (for Premchand – Hindi)
श्री प्रेम (प्रेमचंद के लिए – हिंदी)
Shrī prem (premcand ke lie – hindī)
Mr. Mirza (for Ghalib – Urdu)
श्री मिर्ज़ा (ग़ालिब के लिए – उर्दू)
Shrī mirzā (g̱ẖālib ke lie – urdū)
Mr. Kalidas (for Kalidasa – Sanskrit)
श्री कालिदास (कालिदास के लिए – संस्कृत)
Shrī kālidās (kālidās ke lie – Sanskrit)
¶
Mix-and-match letter and/or word games and exercises will be created with the objective of integrating the knowledge of all five language alphabets learned.
पाँचों भाषाओं की वर्णमाला के ज्ञान को एकत्रित करने के उद्देश्य से मिश्रण और मेल अक्षर और/या शब्द खेल और अभ्यास पत्र तैयार किए जाएगे।
Pāṅcoṅ bhāshāoṅ kī varṇamālā ke gyān ko ekatrit karane ke uddeśya se mishraṇ aur mel akshar aur/yā śabd khel aur abhyās patra taiyār kie jāege.
Envision a child with a mastery of the alphabets as outlined above, going to school feeling empowered, like a juggernaut or colossus, with full confidence.
उपरोक्त वर्णमालाओं पर निपुणता पाए हुए एक ऐसे बच्चे की कल्पना करें जो पूरे आत्मविश्वास के साथ, सशक्त बन कर एक प्रकांड व्यक्ति के समान पाठशाला की ओर बढ़ता है।
Uparokt varṇamālāoṅ par nipuṇatā pāe hue ek aise bacce kī kalpanā kareṅ jo pūre ātmaviśvās ke sāth, saśakt ban kar ek prakāṅḍ vyakti ke samān pāṭhśālā kī or baṛhatā hai.
¶
As we progress on this project, and as mentioned above and discussed under FAQ 13, we may need to write a smartphone app, prepare a video, or even create a video game treating the letters as human characters in a play, highlighting the similarities and differences between these alphabets.
आगे बढ़ते हुए, और जैसे कि ऊपर बताया गया और अधिक पूछे जाने वाले प्रश्न १३ में चर्चा हुई, हमें इन अक्षरों के बीच की भिन्नता को उजागर करने के लिए एक स्मार्टफोन ऐप या एक वीडियो तैयार करना होगा, या यहां तक कि अक्षरों को एक नाटक के अभिनेताओं के रूप में प्रस्तुत करते हुए एक वीडियो गेम बनाना होगा।
Āge baṛhate hue, aur jaise ki ūpar batāyā gayā aur adhik pūche jāne vāle praśn 13 meṅ carcā huī, hameṅ in aksharoṅ ke bīc kī bhinnatā ko ujāgar karane ke lie ek smārṭphon aip yā ek vīḍiyo taiyār karanā hogā, yā yahāṅ tak ki aksharoṅ ko ek nāṭak ke abhinetāoṅ ke rūp meṅ prastut karate hue ek vīḍiyo gem banānā hogā.
Furthermore, lullabies or nursery rhymes focused on alphabets can be written and joyfully sung.
इसके अलावा, वर्णमाला पर केंद्रित लोरी या नर्सरी कविता को लिखा और खुशी से गाया जा सकता है।
Isake alāvā, varṇamālā par kendrit lorī yā narsarī kavitā ko likhā aur khuśī se gāyā jā sakatā hai.
This will help achieve the comparative teaching of these alphabets with a hilarious effect.
यह इन वर्णमालाओं के तुलनात्मक शिक्षण को एक मनोरंजक ढंग से प्राप्त करने में मदद करेगा।
Yah in varṇamālāoṅ ke tulanātmak śikshaṇ ko ek manoranjak ḍhang se prāpt karane meṅ madad karegā.
Ultimately, this multi-languaging project is expected to promote the preservation of the diversity of scripts and languages from extinction, as they embody an integral part of human culture and history.
मूलभूत रूप से, यह बहुभाषी परियोजना से अपेक्षा की जाती है कि इस से लिपियों और भाषाओं के बीच की विविधता को विलोपन से बचाया जा सकेगा क्योंकि वे मानव संस्कृति और इतिहास का एक अभिन्न अंग हैं।
Mūlbhūt rūp se, yah bahubhāshī pariyojanā se apekshā kī jātī hai ki is se lipiyoṅ aur bhāshāoṅ ke bīc kī vividhatā ko vilopan se bacāyā jā sakegā kyoṅki ve mānav sanskriti aur itihās kā ek abhinn ang haiṅ.
For now, it suffices to be able to see their close relatedness, or lack thereof.
अभी के लिए इनका निकट सम्बन्ध या असंबद्धता देख लेना ही पर्याप्त होगा।
Abhī ke lie inakā nikaṭ sambandh yā asambaddhatā dekh lenā hī paryāpt hogā.
¶
The following transliteration (Romanization) schemes are used in this multi-languaging project:
इस बहुभाषी परियोजना में निम्नलिखित लिप्यान्तरण (रोमनीकरण) प्रणालीयों का उपयोग हुआ है:
Is bahubhāshī pariyojanā meṅ nimnlikhit lipyāntaraṇ (romanīkaraṇ) praṇāliyoṅ kā upayog huā hai:
¶
Devanagari – Sanskrit: International Alphabet of Sanskrit Transliteration (IAST)
देवनागरी – संस्कृत: अन्तर्राष्ट्रीय संस्कृत लिप्यन्तरण वर्णमाला – आई.ए.एस.टी. (IAST)
Devanāgarī – Sanskrit: antarrāshṭrīya Sanskrit lipyantaraṇ varṇamālā – āī.e.es.ṭī. (IAST)
Devanagari – Hindi: Library of Congress (LoC) system
देवनागरी – हिंदी: लाइब्रेरी ऑफ़ कांग्रेस – एल.ओ.सी. (LoC) प्रणाली
Devanāgarī – hindī: lāībrerī āf kāngres – el.o.sī. (LoC) praṇālī
Telugu: LoC system
तेलुगु: एल.ओ.सी. (LoC) प्रणाली
Telugu: ek.o.sī. (LoC) praṇālī
Urdu: LoC system
उर्दू: एल.ओ.सी. (LoC) प्रणाली
Urdū: el.o.sī (LoC) praṇālī
¶
It may help to know that IAST and LoC systems are, in fact, similar.
यह जान लेना महत्वपूर्ण होगा कि आई.ए.एस.टी. (IAST) और एल.ओ.सी. (LoC), वास्तव में, समान हैं।
Yah gyān lenā mahatvapūrṇa hogā ki āī.e.es.ṭī. (IAST) aur el.o.sī.
¶
It is hoped that the above groundwork will pave the way as we progress toward implementing the idea of teaching scripts concurrently.
आशा की जाती हैं कि उपरोक्त आधार पर किए गए कार्य लिपियों के सहसंबंध शिक्षण के विचार के क्रियान्वयन के लिए मार्ग प्रशस्त करेंगे।
Āśā kī jātī haiṅ ki uparokt ādhār par kie gae kārya lipyoṅ ke sahasambandh śikshaṇ ke vicār ke kriyānvayan ke lie mārg praśast karenge.
At this stage of the project, this "Introduction" on alphabetics is targeted primarily for adult learners, parents, teachers/educators, software developers, policy decision makers and interested citizens.
परियोजना के इस मोड़ पर, वर्णानुक्रम विज्ञानं का यह "परिचय" मूल रूप से वयस्क शिक्षार्थी, माता-पिता, शिक्षक, सॉफ्टवेयर डेवलपर, नीति निर्णय निर्माता और इच्छुक नागरिकों की ओर लक्षित है।
Pariyojanā ke is moṛ par, varṇānukram vigyān kā yah "paricay" mūl rūp se vayask śikshārthī, mātā-pitā, śikshak, sāphṭweyar ḍevalapar, nīti nirṇay nirmātā aur icchuk nāgarikoṅ kī or lakshit hai.
This work undoubtedly will help prepare the appropriate tools (software or otherwise) needed for simultaneously teaching these scripts to pre-school children, which is the eventual goal.
यह कार्य उपरोक्त लिपियों के सह्सम्बन्धी शिक्षण के लिए उपयुक्त उपकरण (सॉफ्टवेयर या अन्य) बनाने में बेशक मदद करेगा, जिसका अंतिम लक्ष्य प्री स्कूल के छात्र हैं।
Yah kārya uparokt lipiyoṅ ke sahsambandhī śikshaṇ ke lie upayukt (sāphṭweyar yā anya) banāne meṅ beśak madad karegā, jisakā antim lakshya prī skūl ke chātra haiṅ.
¶
Finally, it is important to keep in mind that the information presented is by no means complete and may not have addressed all the nuances and intricacies which are expected to be learned in classroom.
अंत में, यह याद रखना उचित होगा कि यहाँ रखी गई जानकारी किसी भी रूप से पूर्ण नहीं है और यह बिलकुल मुमकिन है कि कक्षा में सीखी जाने वाली बारीकियों और पेचीदगियों का व्यापक उल्लेख इस में न किया गया हो।
Ant meṅ, yah yād rakhanā ucit hogā ki yahāṅ rakhī gaī jānakārī kisī bhī rūp se pūrṇa nahīṅ hai aur yah bilakul mumakin hai ki kakshā meṅ sīkhī jāne vālī bārīkiyoṅ aur pecīdagiyoṅ kā vyāpak ullekh is meṅ na kiyā gayā ho.
See the accompanying "References" section for a detailed picture.
विस्तार में समझने के लिए संलग्न "सन्दर्भ" अनुभाग देखें।
Vistār meṅ samajhane ke lie saṅlagn "sandarbh" anubhāg dekheṅ.
¶
Acknowledgment:
स्वीकृति
svīkruti
I thank the anonymous linguists, Mr. SS and Mr. TS, for offering strong encouragement, critical review, and helpful comments in preparing the Alphabetics documents.
मैं गुमनाम भाषाविदों श्री स.स. और श्री त.श. का धन्यवाद करता हूँ कि दोनों ने वर्णानुक्रम विज्ञान के दस्तावेज़ के निर्माण में शक्तिशाली प्रोत्साहन, महत्वपूर्ण समीक्षा और सहायक टिप्पणियों की पेशकश की।
Maiṅ gumanām bhāshāvidoṅ shrī sa.sa. aur shrī ta.śa. kā dhanyavād karatā hūṅ ki donoṅ ne varṇānukram vigyān ke dastāvez ke nirmāṇ meṅ śaktiśālī protsāhan, mahatvapūrṇa samīkshā aur sahāyak ṭippaṇiyoṅ kī peśkaś kī.
¶