"भाषा बदलो, और आप के विचार बदल जाएंगे।"
कार्ल अल्ब्रेक्ट

बीरेल्लि शेषि, एम.डी.
वर्णानुक्रम विज्ञान: संस्कृत/हिंदी (देवनागरी), तेलुगु और उर्दू (नस्तालीक़) की लिपियों के बीच अक्षर-मानचित्रण का एक प्रयास

बीरेल्लि शेषि, एम.डी.
परिचय
अक्षर-मानचित्रण से मेरा तात्पर्य विभिन्न भाषाओं (जैसे अंग्रेज़ी, तेलुगु, हिंदी, उर्दू और संस्कृत) में वर्ण-दर-वर्ण या अक्षर-दर-अक्षर अनुवाद का है।
इसका अर्थ है एक भाषा का दूसरी भाषाओं के उच्चारण आवाज़ से मानचित्रण करना।
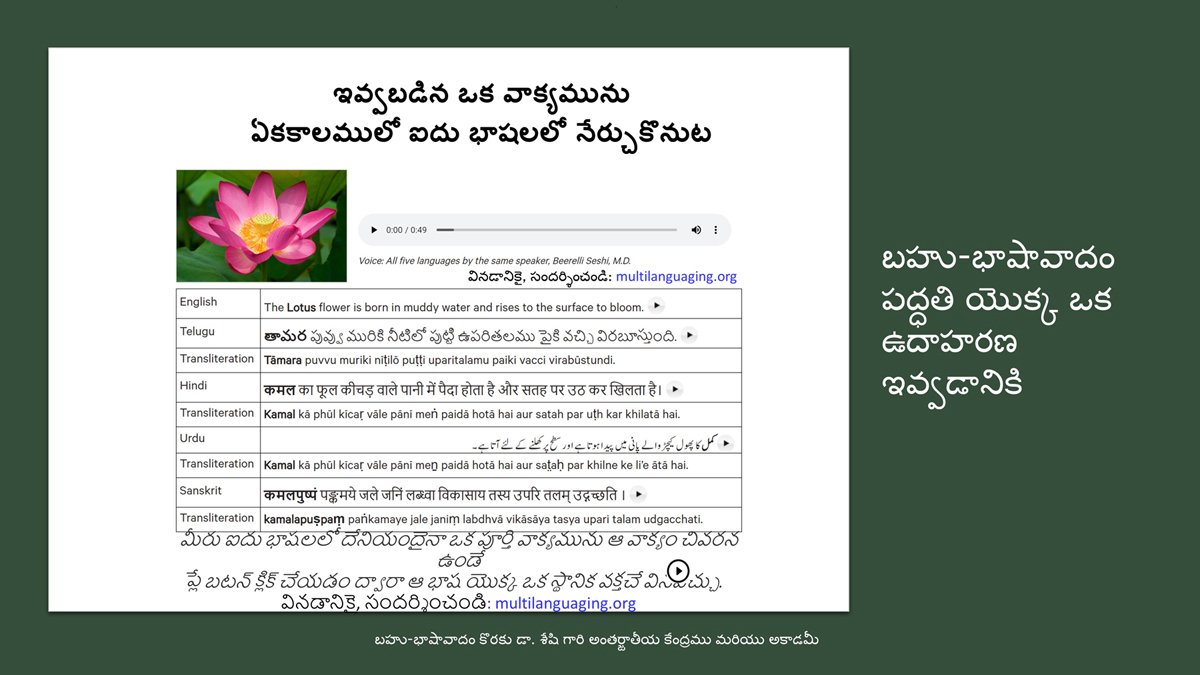
यह इस परियोजना में उपयोगित शब्द-दर-शब्द और वाक्य-दर-वाक्य अनुवाद के रूप से उल्टा है।
जहाँ पारम्परिक अनुवादों भाषाओं के बीच अर्थ का मानचित्रण करते हैं, वर्णानुक्रम विज्ञान में उच्चारण की आवाज़ों का मानचित्रण होता है।
अक्षर के स्तर पर किए गए अनुवाद को वैकल्पिक रूप से लिप्यंतरण के रूप में भी देखा जा सकता है।
जैसे कि शब्द/वाक्य अनुवाद अर्थ/अवधारणा/विचार का मानचित्रण करते हैं, अक्षर-दर-अक्षर अनुवाद एक भाषा के उच्चारण को दूसरी भाषा के उच्चारण से प्रतिचित्रित करता है।
एक प्रकार से, जहाँ पहला वाला अधिकतर रूप से शब्दों और वाक्यों में वर्णित वस्तु या विचार से सम्बंधित मानसिक व्यायाम है जो संलग्न आवाज़ों से अचेत है, वहां दूसरा, एक रूप से, आम तौर पर शारीरिक और संवेदी है जो अक्षर के द्वारा अवगत किए गए उच्चारण के प्रभाव पर केन्द्रित है।
संभावित रूप से, प्रारंभिक विचार में, छात्रों को पाँच भाषाओं की वर्णमाला सीखना देखने में चुनौतीपूर्ण और कठिन लग सकता है।
तथापि, एक बार छात्र जब उन्हें सीखना शुरू करेंगे तब यह इतना डरावना नहीं होगा।
संलग्न एक्सेल के कार्यपत्रक का उद्देश्य इन वर्णमालाओं के बीच की समानताओं को दर्शाना है जिस से उनकी अधिगम्यता में योगदान होगा।
जैसे कि कई पाठको को ज्ञान होगा, हिंदी और संस्कृत एक ही लिपि, देवनागरी, का उपयोग करते हैं।
हालाँकि तेलुगु अलग लिपि का उपयोग करती हैं, उसकी वर्णमाला मूल रूप से देवनागरी के समान है।
विभिन्नता के महत्व को कम न करते हुए यह बताना आवश्यक है कि तेलुगु/हिंदी/संस्कृत (THS) वर्णमाला व्यावहारिक दृष्टि से एक समान हैं।
अंतर यह है कि जहाँ संस्कृत और हिंदी देवनागरी लिपि का उपयोग करते हैं, तेलुगु अलग लिपि का उपयोग करती हैं―आवाज़ें वही लेकिन लिपियाँ/प्रतिरूप अलग।
"एक ही आवाज़ परन्तु अलग लिपि" की यह अवधारणा भारत के राष्ट्रीय आदर्श-वाक्य "विविधतायामेकता" का एक और प्रत्यक्ष रूप है।
बच्चों को यह समझाना महत्वपूर्ण है कि अगर बाहरी रूप अलग भी हो, मूल तब भी वही है―तेलुगु, संस्कृत/हिंदी, और उर्दू में एक ही उच्चारण "a" ("अ") अलग अलग रूप में दर्शाएँ जाते हैं: అ, अ/अ, और ا.
इसे एक कल्पनाशील और मनोरंजक तरीके से दृश्य माध्यम, और विशेष रूप से बच्चों के लिए बनाए गए वीडियो या स्मार्टफोन ऐप, द्वारा प्राप्त किया जा सकता है।
यह वयस्क शिक्षार्थियों के लिए उतना ही शिक्षाप्रद होगा क्योंकि इसमें से भिन्न बाहरी रूप से छिपी हुई अन्तर्निहित समानता का शक्तिशाली सन्देश प्रकट होता है।
इसके अतिरिक्त, इन भाषाओं का एक दूसरे से या तो माँ-बहन जैसा और या बहनों/चचेरी बहनों जैसा अंतरंग संबंध इस विधि के द्वारा बल देकर दर्शाया जाएगा।
मैंने भी अधिक पूछे जाने वाले प्रश्न ३ और अधिक पूछे जाने वाले प्रश्न 10 में इस सन्देश को व्यक्त करने का प्रयास किया है।
वास्तव में, वर्णानुक्रम विज्ञान इस तर्क को इन भाषाओं के शब्दावली / शब्द की तुलना में अधिक सशक्त ढंग से रखता है।
शब्दों में, हम देखते हैं कि समय बीतने और स्रोत से विचरण के कारण समान शब्द का कभी कभी दूसरी भाषाओं में अलग या सूक्ष्म भेद युक्त अर्थ बन जाता है (जिस से अनुवाद में कभी कभी भ्रम की स्थिति उत्पन्न होती है)।
परन्तु, आवाज़ें नहीं बदलती है; नइ आवाज़ें जुड़ सकती है और पुरानी ढल सकती है, लेकिन, विशेष रूप से तेलुगु/हिंदी/संस्कृत (THS) भाषाओं में, वर्णमाला बहुत हद तक स्थिर रहती है।
इसलिए, मैं इन वर्णमालाओं को सीखने और इन पर ध्यान देने के महत्व को जितना बल दूँ कम है।
अंग्रेज़ी भाषा लातीनी/रोमन वर्णमाला का उपयोग करती हैं, जो – इसके सौभाग्य से – सीखने में सब से आसान है।
फारसी-अरबी वर्णमाला पर आधारित उर्दू की लिपि सब से कठिन है, और यह लातीनी और तेलुगु/हिंदी/संस्कृत (THS) वर्णमाला से बिलकुल विभिन्न है।
दूसरी ओर, जहाँ उर्दू की लिपि हिंदी से भिन्न है, वहां दोनों भाषाओं की आम बोली और व्याकरण मूल रूप से समान है।
जैसा कि ऊपर बताया गया, मेरा तर्क है कि यह पाँच असंबंधित भाषाएँ, उदाहरणार्थ अरबी, चीनी, देवनागरी, यूनानी और युकाटेक माया, सीखने जैसा नहीं है।
संलग्न "वर्णमाला मानचित्रण तालिकाओं" का अनुभाग तेलुगु/हिंदी/उर्दू/संस्कृत (THUS) भाषाओं की वर्णमालाओं की संबंधता को दर्शाता है।
नए शिक्षार्थी को प्रोत्साहित करने के लिए और यह सुनिश्चित करने के लिए कि वह अराजक दिखने वाली उर्दू लिपि से भयभीत न हो जाए, मैं ने उर्दू अक्षरों को विभिन्न समूहों में व्यवस्थित करने का प्रयास किया है जिस में हर समूह के अक्षरों के बीच के अन्तर्निहित दृश्य स्वरूप को दिखाया गया है।
तेलुगु/हिंदी/उर्दू/संस्कृत (THUS) भाषाओं की वर्णमालाओं के अध्ययन, सीखने, याद रखने और उपयोग को सुगम बनाने के लिए मैं ने उन्हें संलग्न "वर्णमाला मानचित्रण तालिकाओं" के अनुभाग के अंदाज़ में क्षितिज के समांतर दिशा में बनी दस तालिकाओं में बाएं से दाएं व्यवस्थित किया है:
तालिका १ – देवनागरी और तेलुगु स्वर
तालिका २ – देवनागरी और तेलुगु व्यंजन
तालिका ३ – देवनागरी व्यंजन समूह
तालिका ४ – देवनागरी और उर्दू विशेष व्यंजन
तालिका 5 – देवनागरी हिंदी बनाम उर्दू स्वर
तालिका 6 – देवनागरी हिंदी बनाम उर्दू व्यंजन
तालिका 7 – देवनागरी बनाम उर्दू: महाप्राण व्यंजन
तालिका 8 – नुक़्ता वाले उर्दू अक्षर
तालिका 9 – बिना नुक़्ता वाले उर्दू अक्षर
तालिका १० – सभी रूपों में पूरी उर्दू वर्णमाला
आशा की जाती है कि इन तालिकाओं से सम्बंधित वर्णमालाओं को सीखने, याद रखने और उनका उपयोग करने में सरलता होगी।
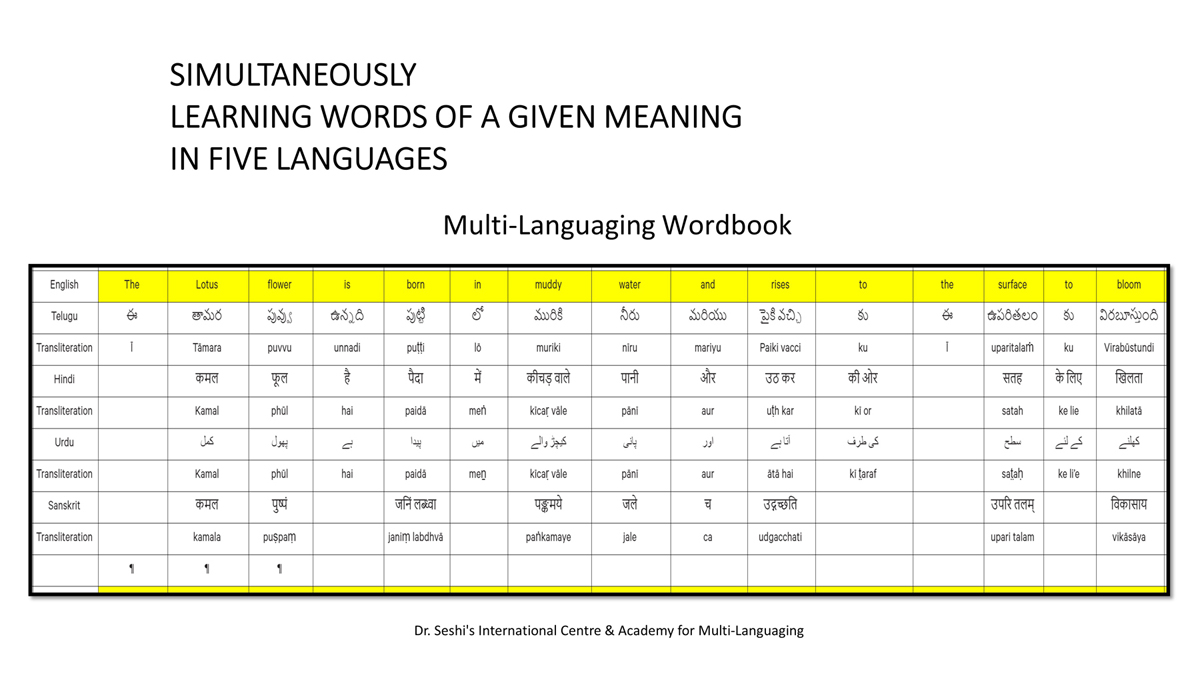
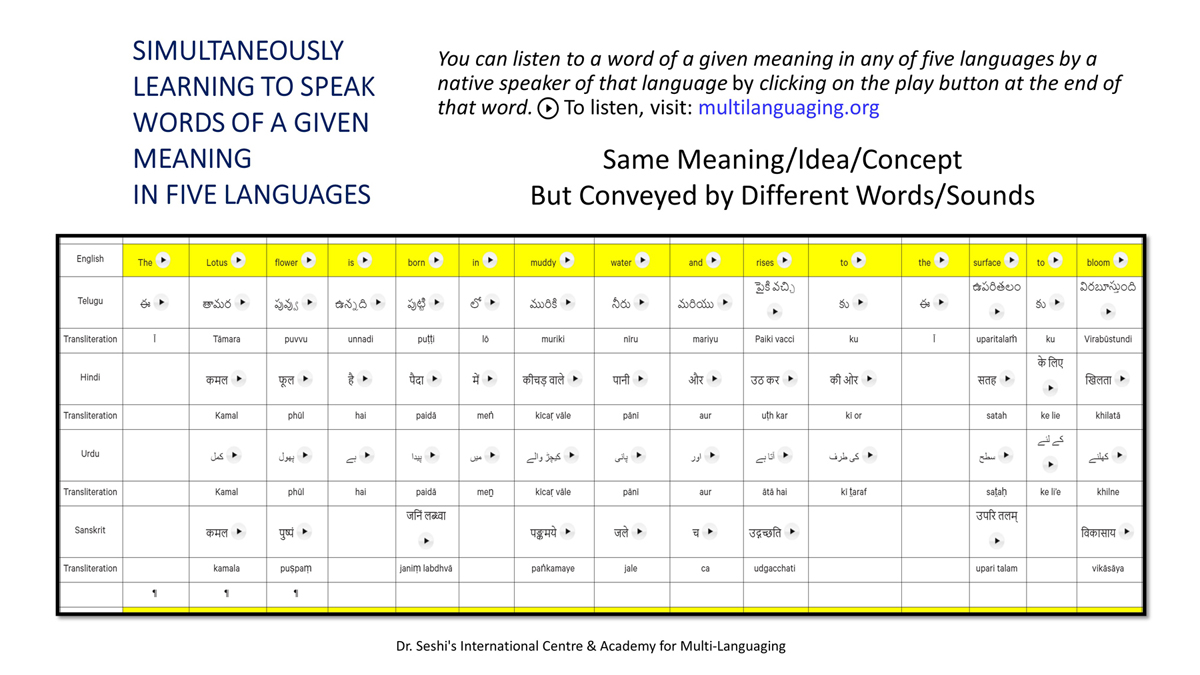
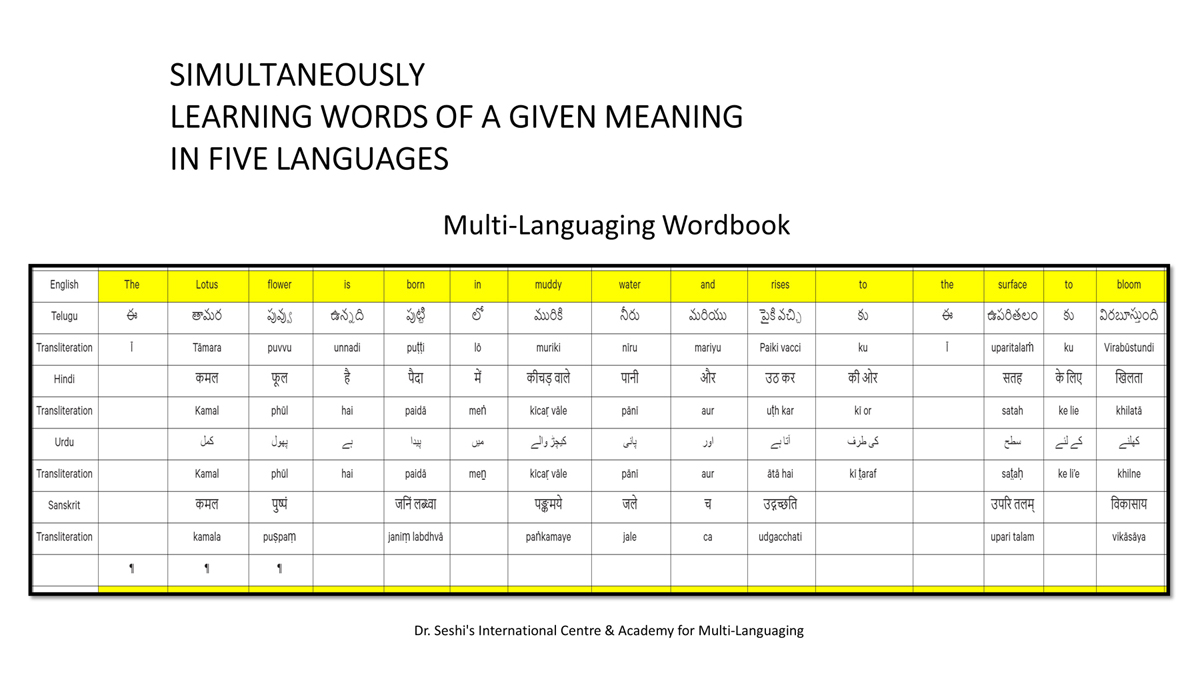
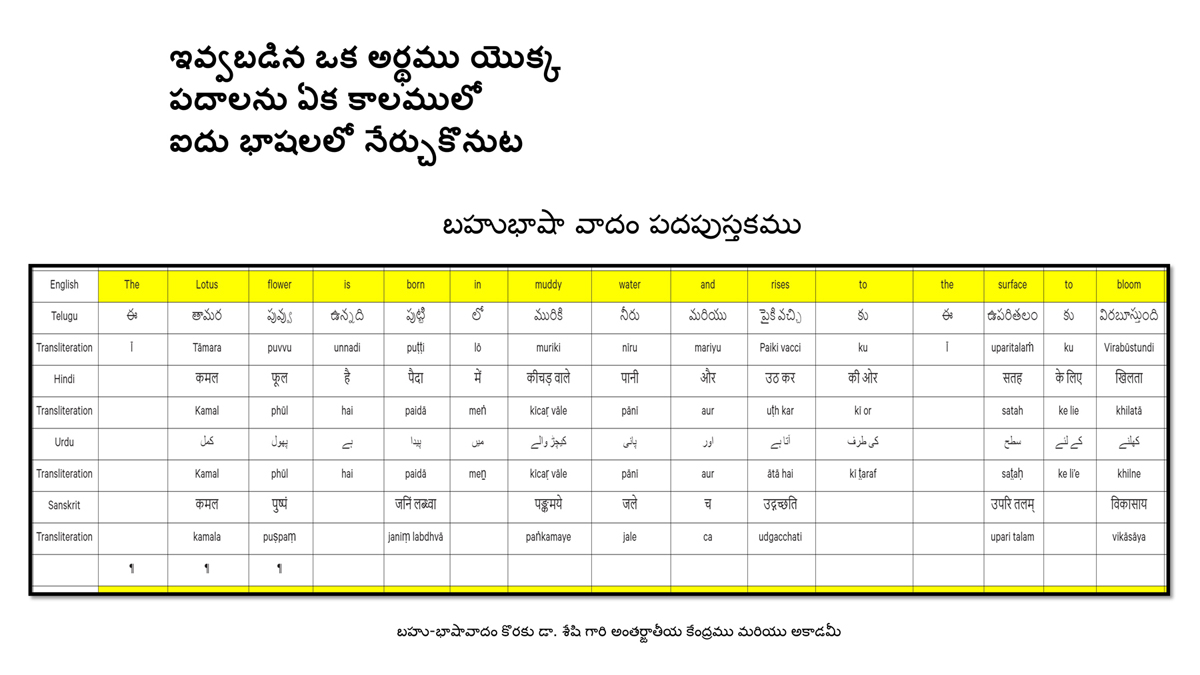
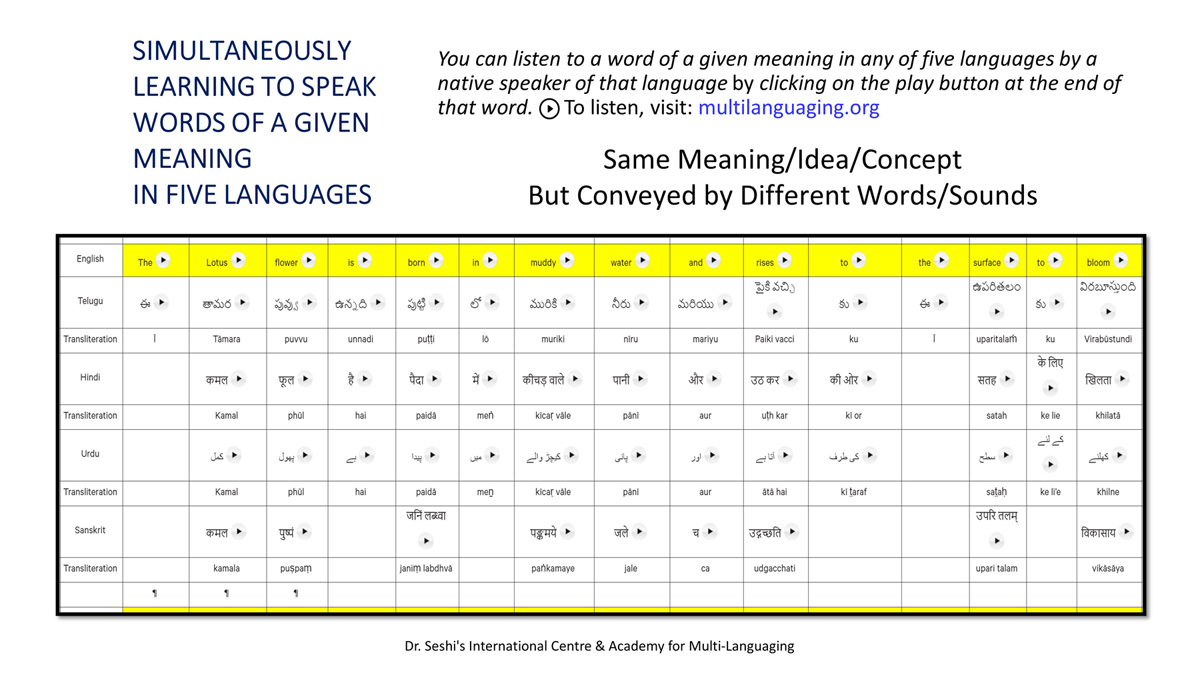
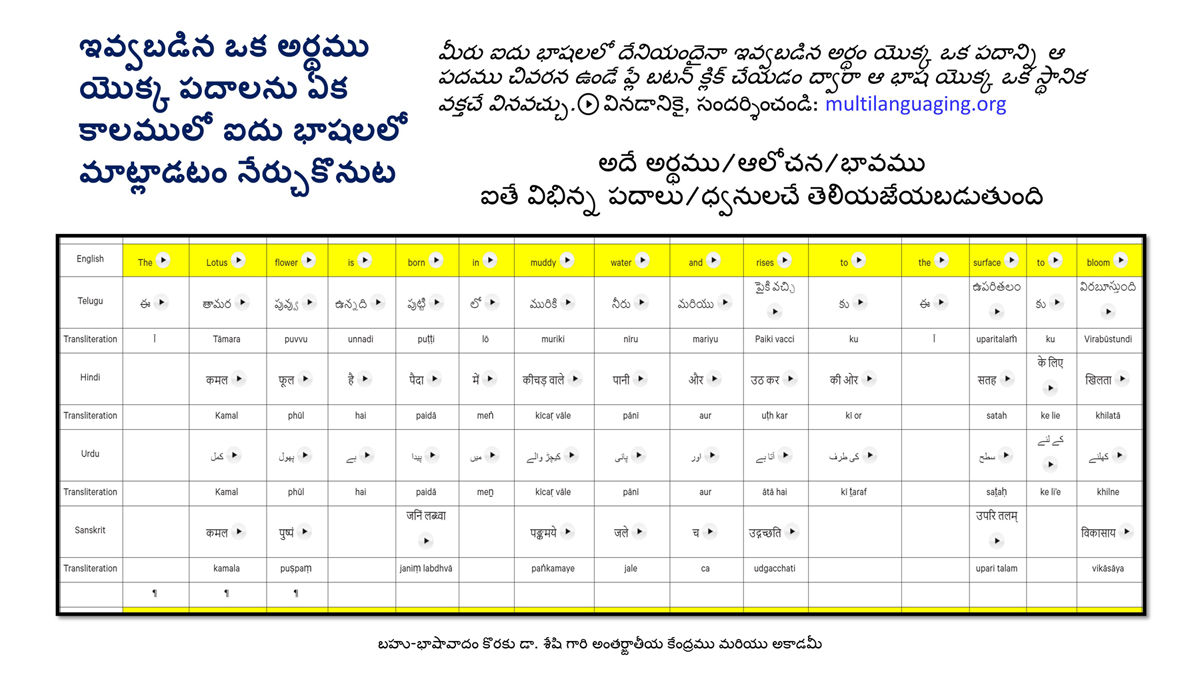
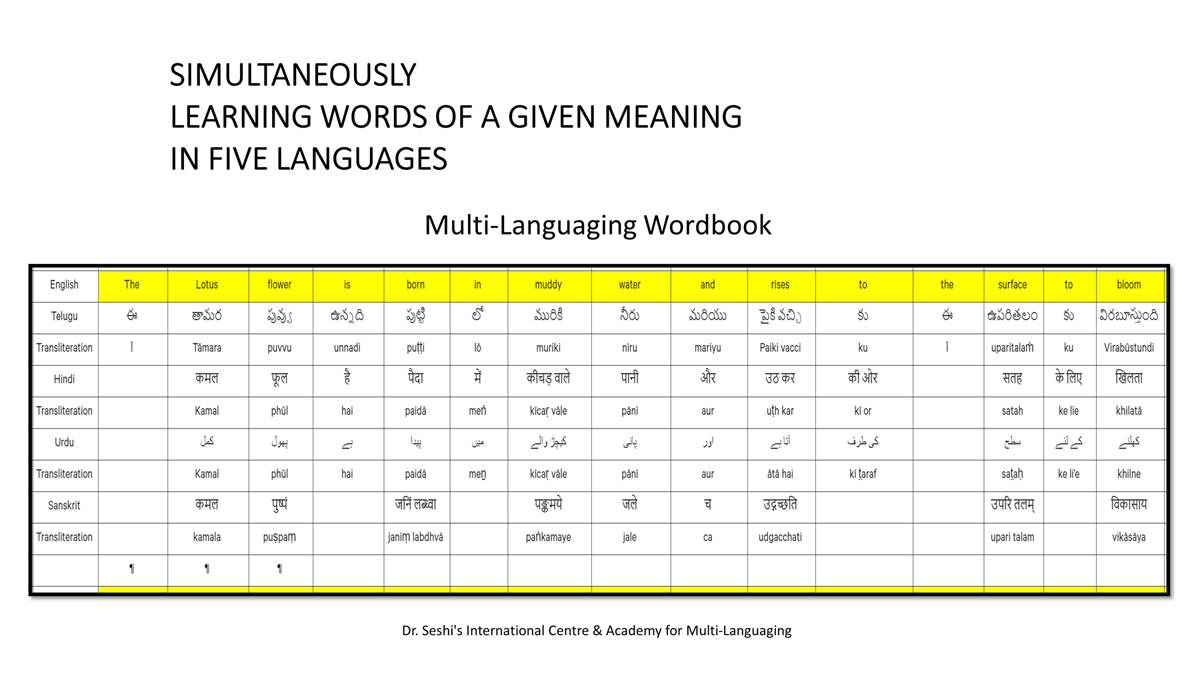
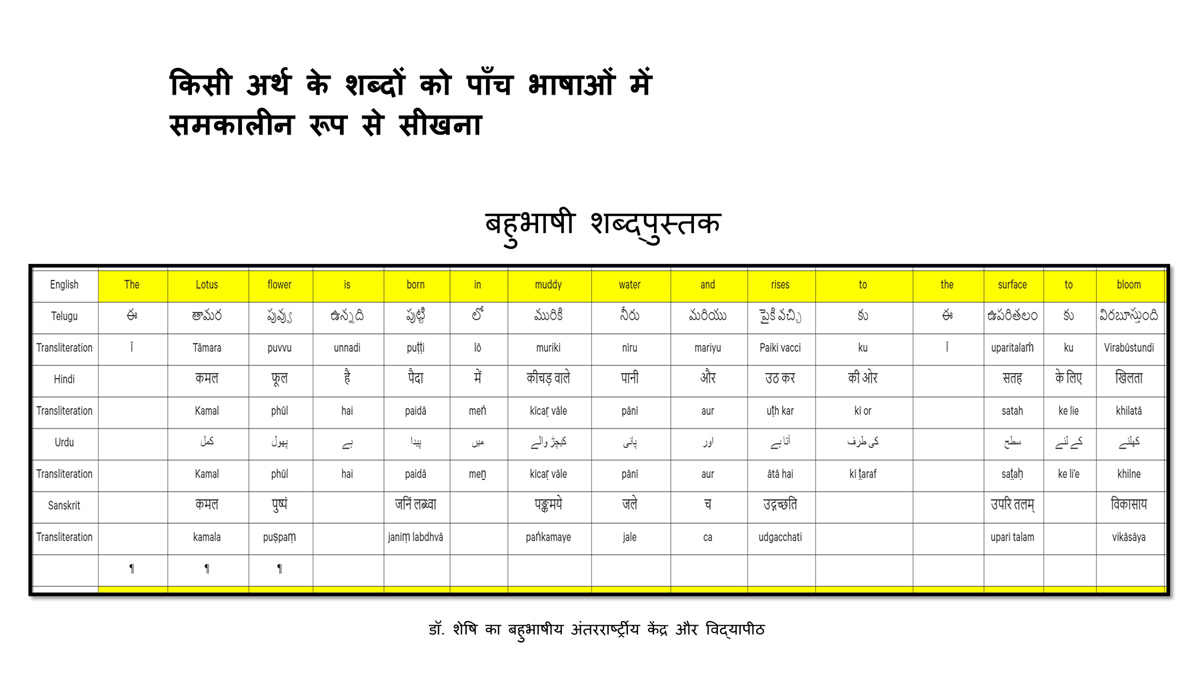
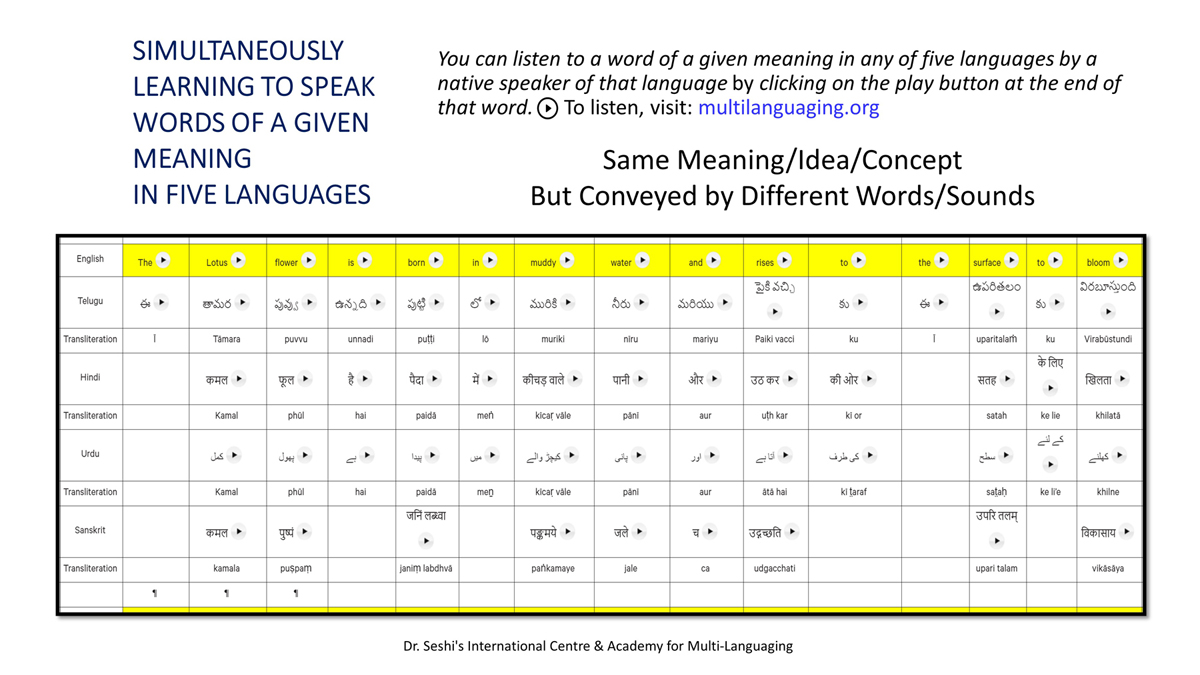
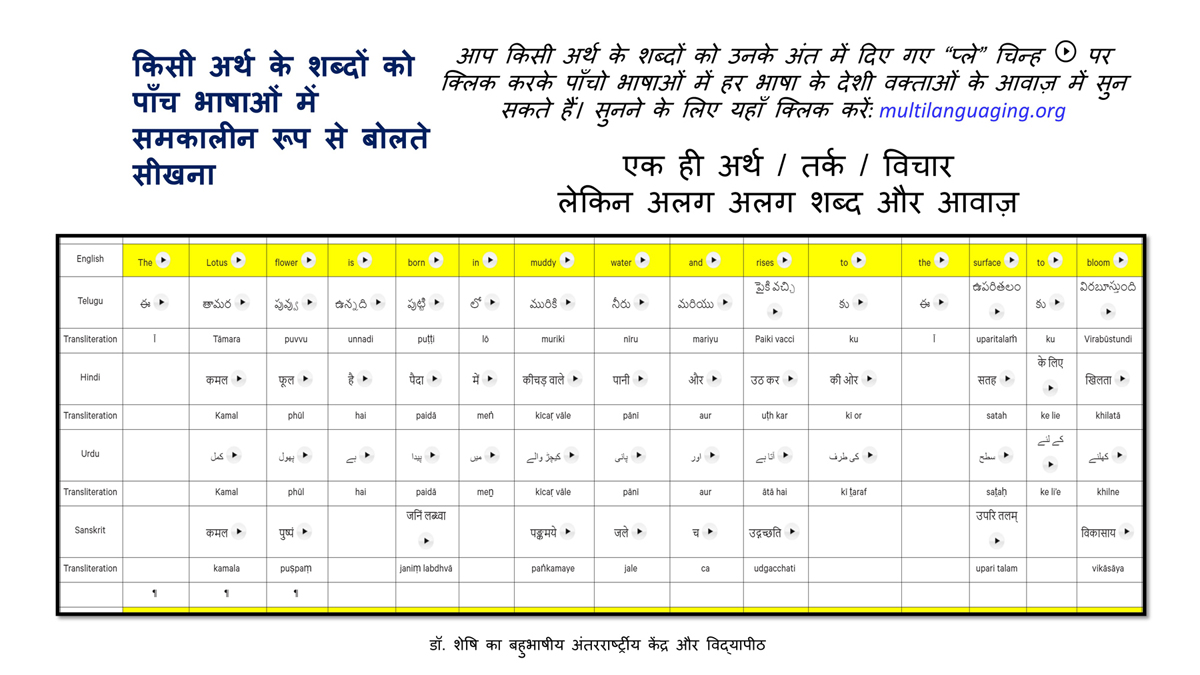
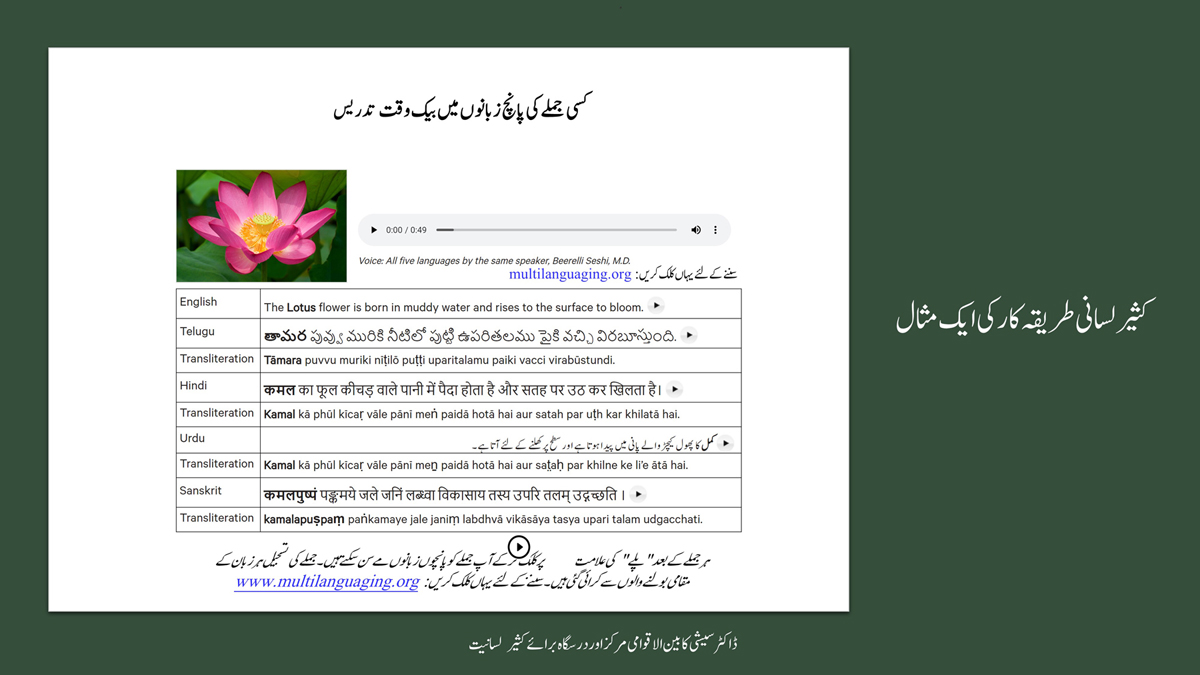
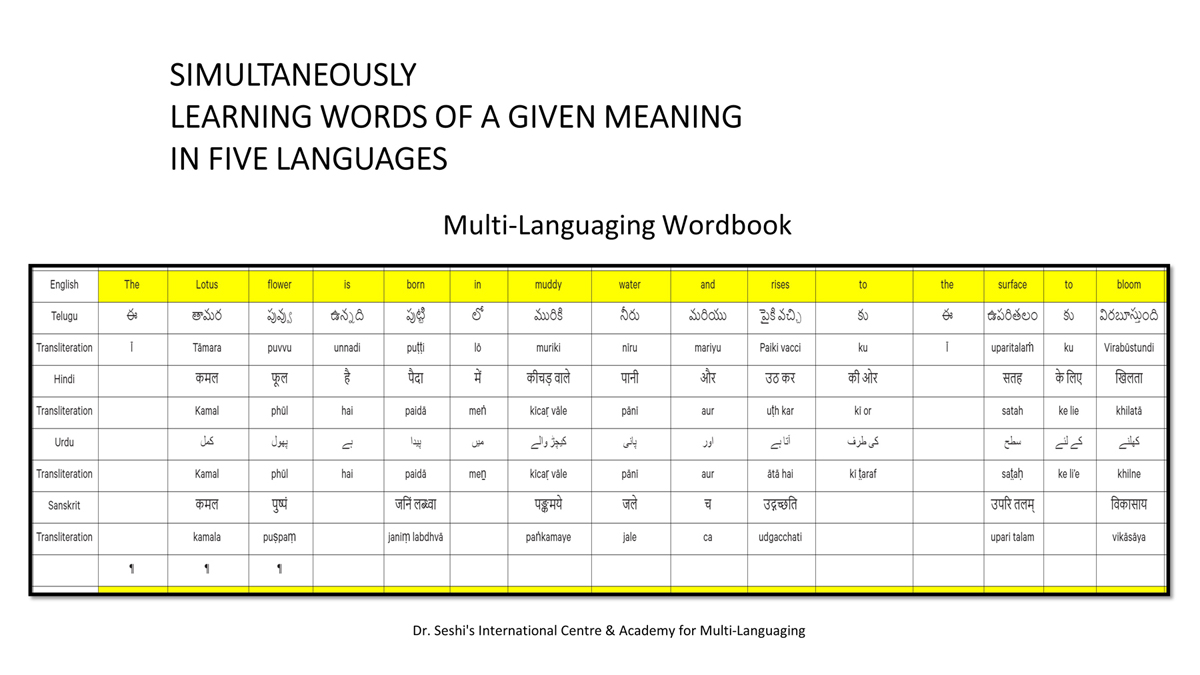
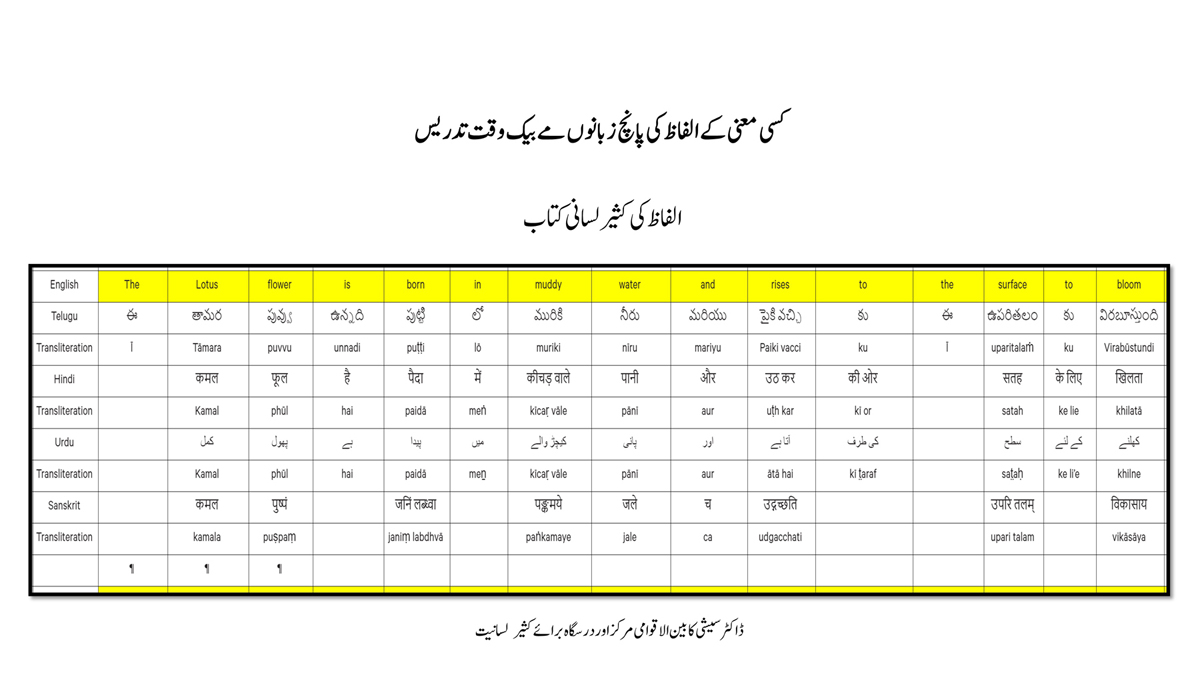
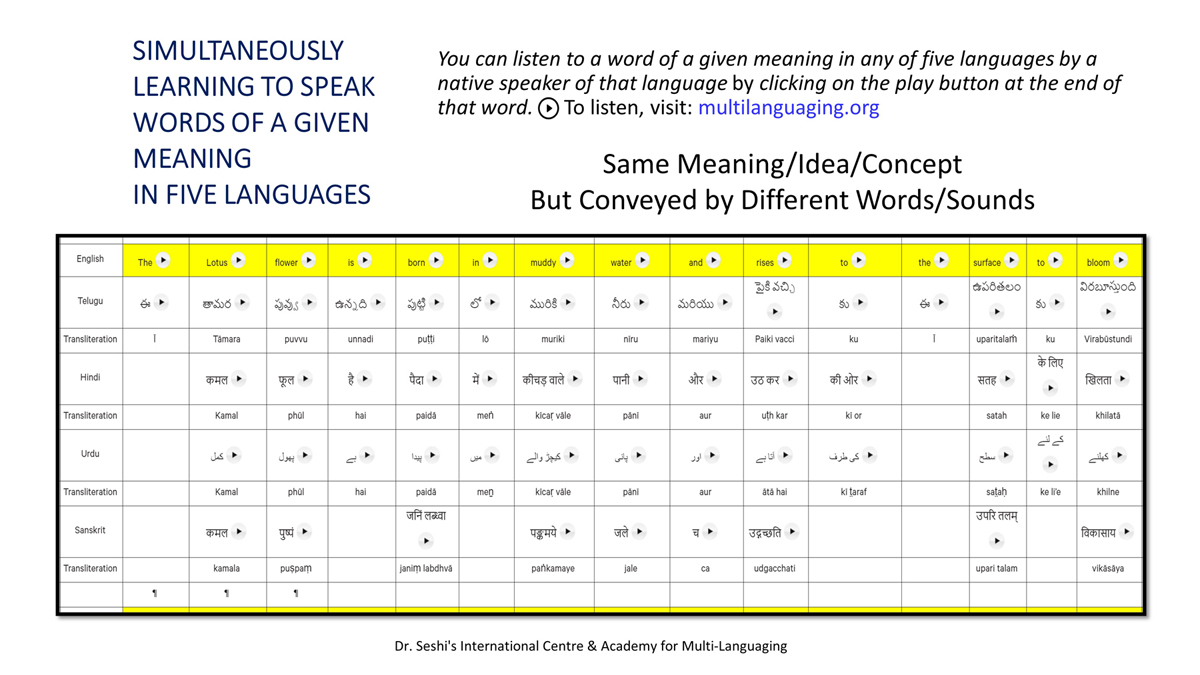
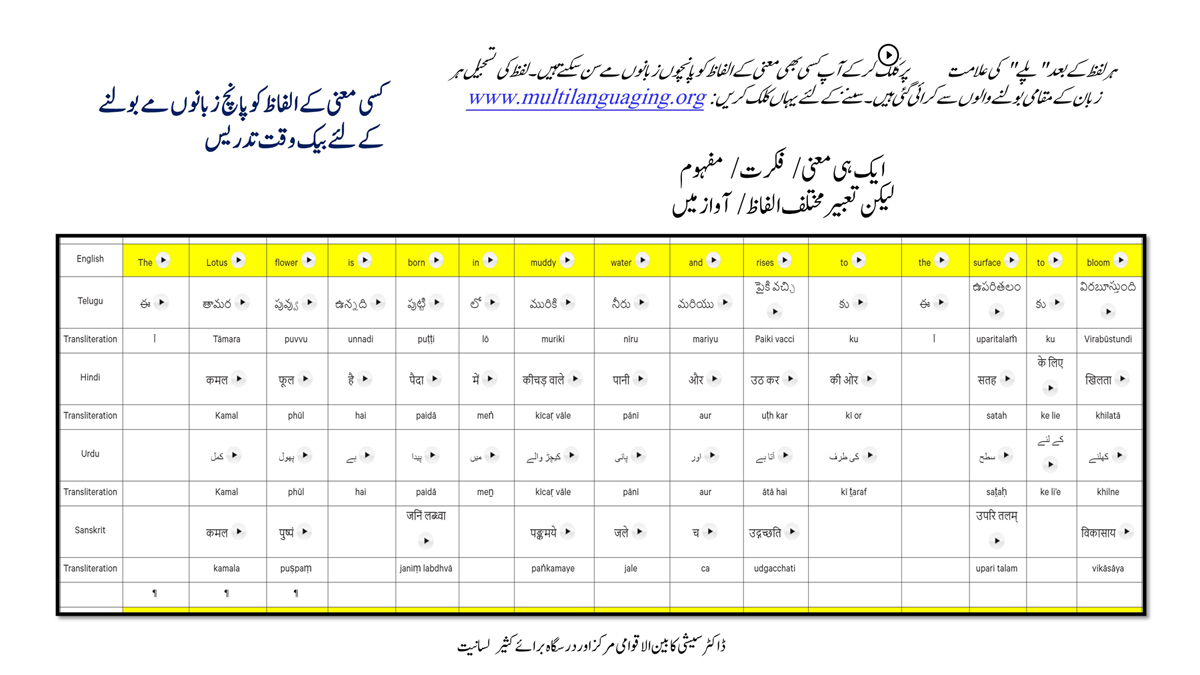
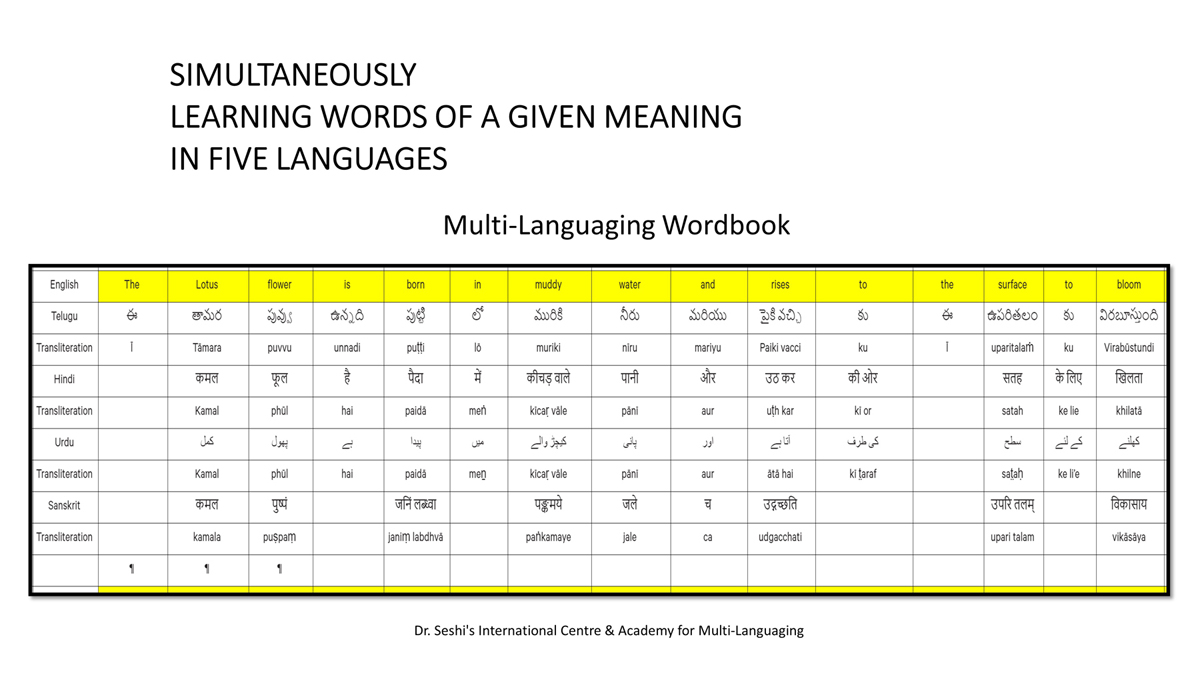
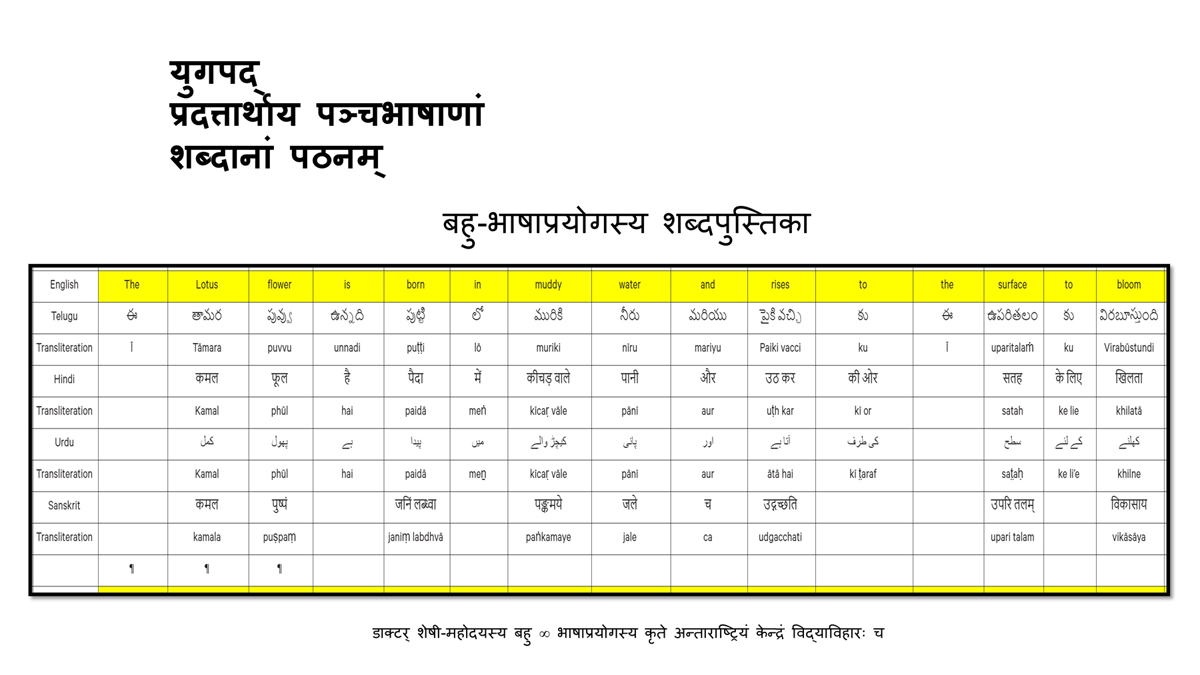
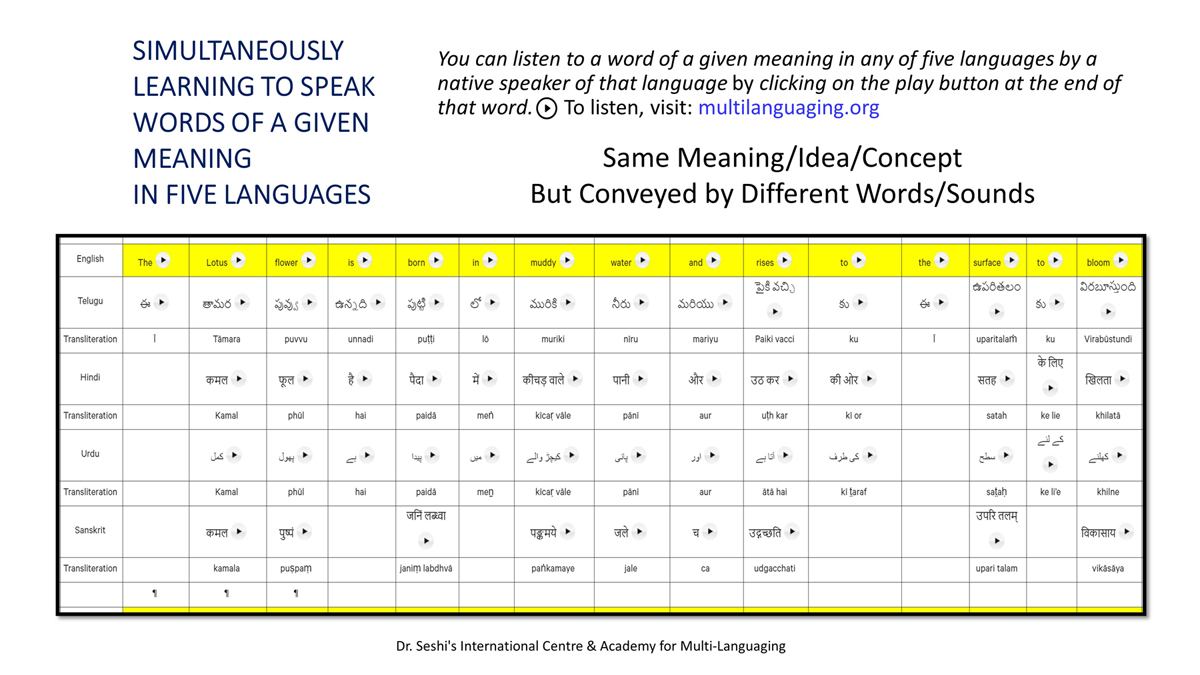
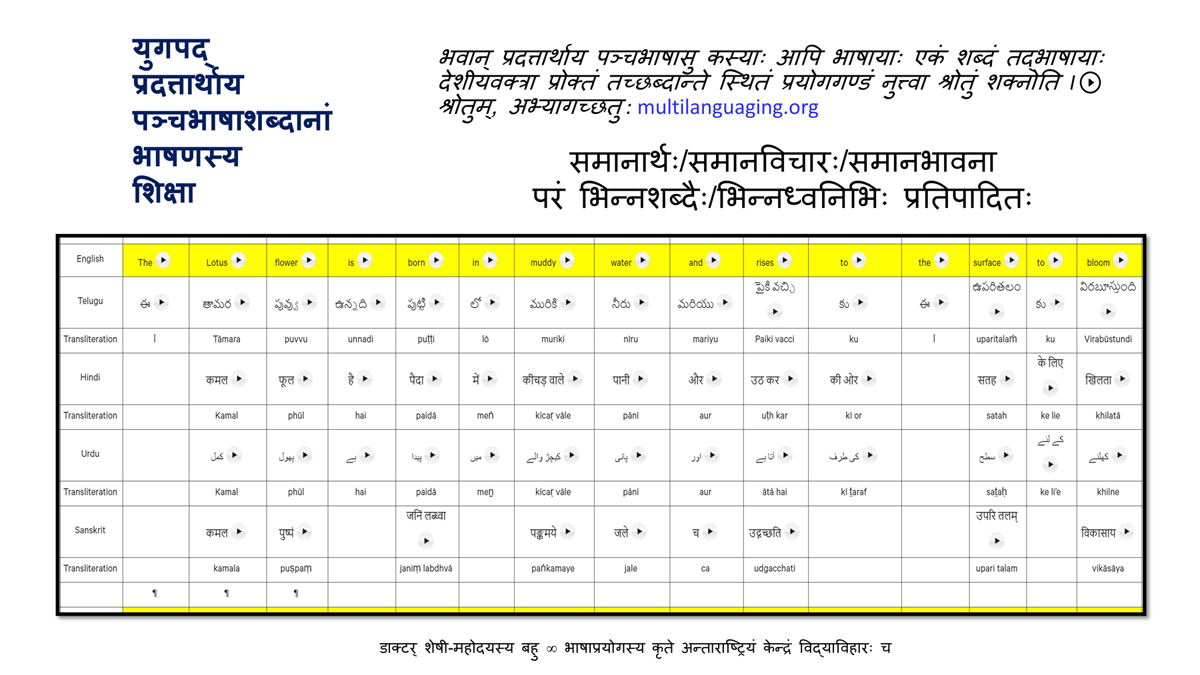
संलग्न "शब्द-स्तर का मानचित्रण दिखाने वाले वर्णमाला विवरणपट" पाँचो भाषाओं की वर्णमालाओं को उस रूप में उपस्थित करते हैं जैसे बच्चे पारंपरिक रूप से किसी भाषा को सीखते हो, अर्थात्, हर अक्षर को एक उदाहरण शब्द से जोड़ कर जो आम तौर पर उसी अक्षर से शुरू होता है और एक ठोस छवि के माध्यम से वर्णित किया जाता है।
लक्षित छात्र ३-५ वर्ष के उम्र वाले प्री-स्कूल के बच्चे होगे।
महत्त्वपूर्ण रूप से, बच्चों के "शोषक मन" द्वारा तुलनात्मक/सहसंबंधी विचारशक्ति और शिक्षा को सुगम बनाने के लिए यह अनुभाग में एक साथ हर भाषा के उदाहरण शब्दों को परिचय हेतु अन्य चार भाषाओं में अनुवादित किया जाता है।
हर भाषा के अक्षरों को दर्शाने के लिए चयनित उदाहरण शब्द-अर्थ उस भाषा के लिए विशेष है; एक भाषा का उदाहरण शब्द किसी दूसरी भाषा की सूचि में नहीं पाया जाएगा।
यह देखते हुए कि अंग्रेज़ी, तेलुगु, हिंदी, उर्दू और संस्कृत में क्रमश: २६, ५१, ५७, ३९ और ४९ अक्षर है, इस से बच्चों के प्रगतिशील बुद्धि में २२२ चित्र/शब्द/अर्थ के सांस्कृतिक मूल्य वाली एक संयोजित तस्वीर बिठाई जाती हैं।
हर अक्षर के दो उदाहरण शब्द सीखने से यह गिनती दुगनी हो जाती हैं (४४० से कुछ अधिक)।
यह विस्तारित दायरा अतिरिक्त रूप से बच्चों के रचनात्मक दिमागों में नए अर्थ/अवधारणा/विचार को स्थापित करने की अनुमति देता है, विशेषतः क्योंकि उनका सम्बन्ध इन भाषाओं के सांस्कृतिक परंपराओं के साथ जुड़ा है, और इसका प्रभाव दशकों से चली आ रहीं शब्दों की मानक सूचीयों से कई अधिक होगा।
अध्ययन और शिक्षण को आगे बढ़ाने के लिए मैं ने इन पाँच विवरणपटो – संख्या १ से ५ – को क्षितिज के समांतर दिशा में बाएं से दाएं व्यवस्थित किया है – अंग्रेज़ी, तेलुगु, हिंदी, उर्दू, और संस्कृत।
भविष्य में चित्रात्मक उदाहरण, पार्श्व आवाज़ और चंचल चित्र को काल्पनिक शिक्षको द्वारा चित्रित किया जाएगा:
श्रीमती सरोजा (सरोजिनी नायडू के लिए – अंग्रेज़ी)
श्री वेमा (वेमना के लिए – तेलुगु)
श्री प्रेम (प्रेमचंद के लिए – हिंदी)
श्री मिर्ज़ा (ग़ालिब के लिए – उर्दू)
श्री कालिदास (कालिदास के लिए – संस्कृत)
पाँचों भाषाओं की वर्णमाला के ज्ञान को एकत्रित करने के उद्देश्य से मिश्रण और मेल अक्षर और/या शब्द खेल और अभ्यास पत्र तैयार किए जाएगे।
उपरोक्त वर्णमालाओं पर निपुणता पाए हुए एक ऐसे बच्चे की कल्पना करें जो पूरे आत्मविश्वास के साथ, सशक्त बन कर एक प्रकांड व्यक्ति के समान पाठशाला की ओर बढ़ता है।
आगे बढ़ते हुए, और जैसे कि ऊपर बताया गया और अधिक पूछे जाने वाले प्रश्न १३ में चर्चा हुई, हमें इन अक्षरों के बीच की भिन्नता को उजागर करने के लिए एक स्मार्टफोन ऐप या एक वीडियो तैयार करना होगा, या यहां तक कि अक्षरों को एक नाटक के अभिनेताओं के रूप में प्रस्तुत करते हुए एक वीडियो गेम बनाना होगा।
इसके अलावा, वर्णमाला पर केंद्रित लोरी या नर्सरी कविता को लिखा और खुशी से गाया जा सकता है।
यह इन वर्णमालाओं के तुलनात्मक शिक्षण को एक मनोरंजक ढंग से प्राप्त करने में मदद करेगा।
मूलभूत रूप से, यह बहुभाषी परियोजना से अपेक्षा की जाती है कि इस से लिपियों और भाषाओं के बीच की विविधता को विलोपन से बचाया जा सकेगा क्योंकि वे मानव संस्कृति और इतिहास का एक अभिन्न अंग हैं।
अभी के लिए इनका निकट सम्बन्ध या असंबद्धता देख लेना ही पर्याप्त होगा।
इस बहुभाषी परियोजना में निम्नलिखित लिप्यान्तरण (रोमनीकरण) प्रणालीयों का उपयोग हुआ है:
देवनागरी – संस्कृत: अन्तर्राष्ट्रीय संस्कृत लिप्यन्तरण वर्णमाला – आई.ए.एस.टी. (IAST)
देवनागरी – हिंदी: लाइब्रेरी ऑफ़ कांग्रेस – एल.ओ.सी. (LoC) प्रणाली
तेलुगु: एल.ओ.सी. (LoC) प्रणाली
उर्दू: एल.ओ.सी. (LoC) प्रणाली
यह जान लेना महत्वपूर्ण होगा कि आई.ए.एस.टी. (IAST) और एल.ओ.सी. (LoC), वास्तव में, समान हैं।
आशा की जाती हैं कि उपरोक्त आधार पर किए गए कार्य लिपियों के सहसंबंध शिक्षण के विचार के क्रियान्वयन के लिए मार्ग प्रशस्त करेंगे।
परियोजना के इस मोड़ पर, वर्णानुक्रम विज्ञानं का यह "परिचय" मूल रूप से वयस्क शिक्षार्थी, माता-पिता, शिक्षक, सॉफ्टवेयर डेवलपर, नीति निर्णय निर्माता और इच्छुक नागरिकों की ओर लक्षित है।
यह कार्य उपरोक्त लिपियों के सह्सम्बन्धी शिक्षण के लिए उपयुक्त उपकरण (सॉफ्टवेयर या अन्य) बनाने में बेशक मदद करेगा, जिसका अंतिम लक्ष्य प्री स्कूल के छात्र हैं।
अंत में, यह याद रखना उचित होगा कि यहाँ रखी गई जानकारी किसी भी रूप से पूर्ण नहीं है और यह बिलकुल मुमकिन है कि कक्षा में सीखी जाने वाली बारीकियों और पेचीदगियों का व्यापक उल्लेख इस में न किया गया हो।
विस्तार में समझने के लिए संलग्न "सन्दर्भ" अनुभाग देखें।
स्वीकृति
मैं गुमनाम भाषाविदों श्री स.स. और श्री त.श. का धन्यवाद करता हूँ कि दोनों ने वर्णानुक्रम विज्ञान के दस्तावेज़ के निर्माण में शक्तिशाली प्रोत्साहन, महत्वपूर्ण समीक्षा और सहायक टिप्पणियों की पेशकश की।