
Alphabetics: An Attempt at Character Mapping Across the Scripts for Sanskrit/Hindi (Devanagari), Telugu, and Urdu (Nastaleeq)
Beerelli Seshi, M.D.
BSeshi@multilanguaging.org
BSeshi@outlook.com
"Change your language and you change your thoughts."
Karl Albrecht

Beerelli Seshi, M.D.

Beerelli Seshi, M.D.
BSeshi@multilanguaging.org
BSeshi@outlook.com
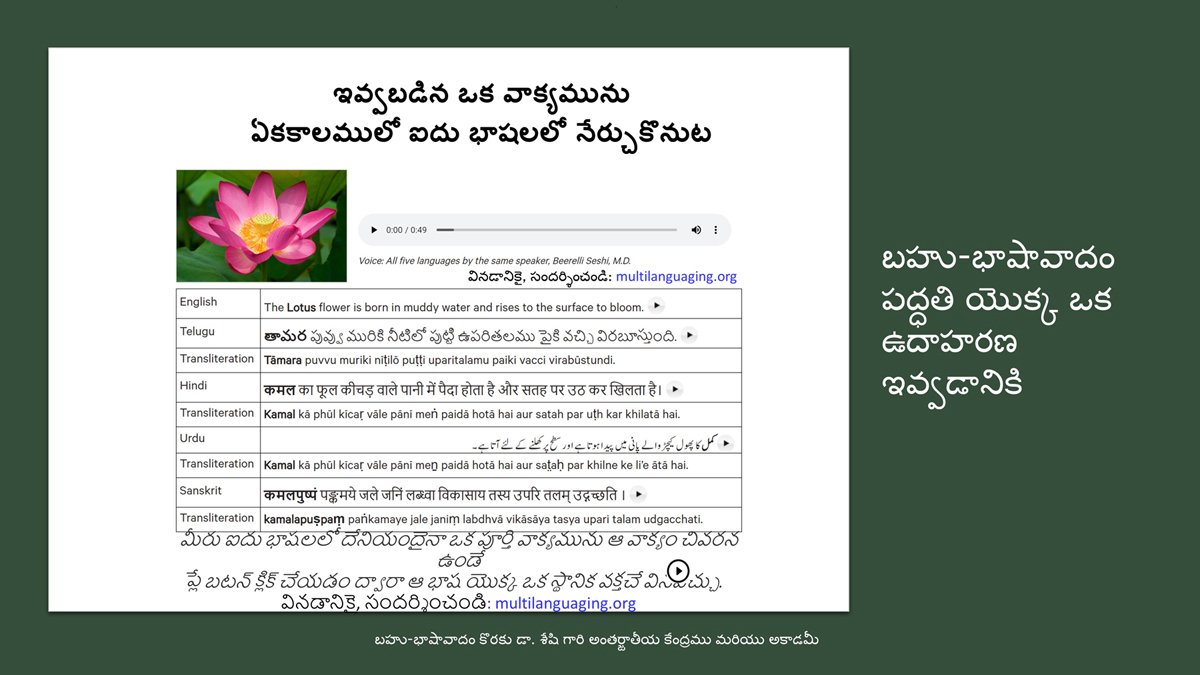
By character mapping, I mean character-by-character or letter-by-letter translation across languages (such as English, Telugu, Hindi, Urdu, and Sanskrit).
That is mapping the sounds of one language to others.
It is a converse of the word-by-word and sentence-by-sentence translations as they are implemented in this project.
While the conventional translations map meanings across languages, alphabetics maps sounds.
Letter-level translation between languages may interchangeably be viewed as transliteration.
Just as word/sentence translation maps meanings/concepts/ideas, so too letter-by-letter translation maps the sounds of one language to another.
In a sense, the former is more a mental exercise dealing with objects or ideas represented by words/sentences, regardless of the sounds that accompany them, whereas the latter, in a sense, is more physical and sensory, dealing exclusively with the impression of the sound that is conveyed by the letter.
It may, at first thought, appear to be challenging and difficult for the students to have to learn alphabets of five languages.
However, it may not be as intimidating as it appears to be once the students start learning them.
The purpose of the accompanying Excel worksheets is to highlight the kinship among these alphabets, contributing to their learnability.
As many of the readers would know, Hindi and Sanskrit use the same script, Devanagari.
Although Telugu uses a different script, its alphabet is essentially identical to Devanagari.
This is not to trivialize the differences, but the THS alphabets are practically one alphabet.
The difference is that, while Sanskrit and Hindi use Devanagari script, Telugu uses a different script―the same sounds, but different scripts/representations.
This concept of "same sound but different script symbol" is another visible form of India’s national motto, "Unity in Diversity"―"विविधतायामेकता"―"vividhatāyāmekatā".
The important message to be imparted to the children is that, although outward forms differ, the essence is the same―the same sound "a" is represented differently across scripts for Telugu, Sanskrit/Hindi, and Urdu―అ, अ/अ, and ا.
This could be achieved in an imaginative and entertaining manner through visual media, especially videos or smartphone apps for children.
It will be equally instructive for adult learners, as it would convey a powerful message of underlying sameness hidden by outwardly different form.
Moreover, it will emphasize the fact that all these languages are intimately connected to each other either as mother-daughter or as sisters/cousins.
I have also endeavored to convey this message while answering the FAQs, especially FAQ 3 and FAQ 10.
In fact, alphabetics makes this point rather more emphatically than the vocabulary/words of these languages.
With words, we see that an identical word may sometimes have a different sense or a more nuanced sense in different languages (sometimes leading to confusion in translations) due to the passage of time and variance from the source.
However, the sounds remain the same, new sounds may be added, or some old ones omitted, but the alphabet remains unaltered to a very great extent, especially among THS languages.
Therefore, I cannot overemphasize the importance of learning and cherishing these alphabets.
English uses the Latin/Roman alphabet, which to its credit is the easiest to learn.
The script that stands out in terms of difficulty is that of Urdu, which is based on a Perso-Arabic alphabet that is quite different from the Latin and THS alphabets.
On the other hand, although Urdu uses a different script from Hindi, their day-to-day language and grammar are basically identical.
As outlined above, my point is that it is not like having to learn five unrelated languages or scripts, like Arabic, Chinese, Devanagari, Greek, and Yucatec Maya, for example.
The accompanying "Alphabet Mapping Tables" section graphically highlights the relatedness of THUS alphabets.
To encourage the new learner and ensure that he/she not be intimidated by the chaotic-appearing Urdu script, I have tried to organize the Urdu letters into various groupings showing the underlying visual pattern within each group.
To facilitate the reference, learning, remembering and usage of the THUS alphabets, I have organized them in the form of ten tables laid out horizontally as in the accompanying "Alphabet Mapping Tables" section, from left to right:
Table 1 – Devanagari and Telugu Vowels
Table 2 – Devanagari and Telugu Consonants
Table 3 – Devanagari Consonant Clusters
Table 4 – Devanagari and Urdu Special Consonants
Table 5 – Devanagari Hindi vs. Urdu Vowels
Table 6 – Devanagari Hindi vs. Urdu Consonants
Table 7 – Devanagari vs. Urdu: Digraphs (Stressed Consonants/Aspirates)
Table 8 – Urdu Letters with Dots
Table 9 – Urdu Letters Without Dots
Table 10 – Complete Urdu Alphabet in All Forms
It is hoped that this will make it easier to learn, remember and use the alphabets in question.
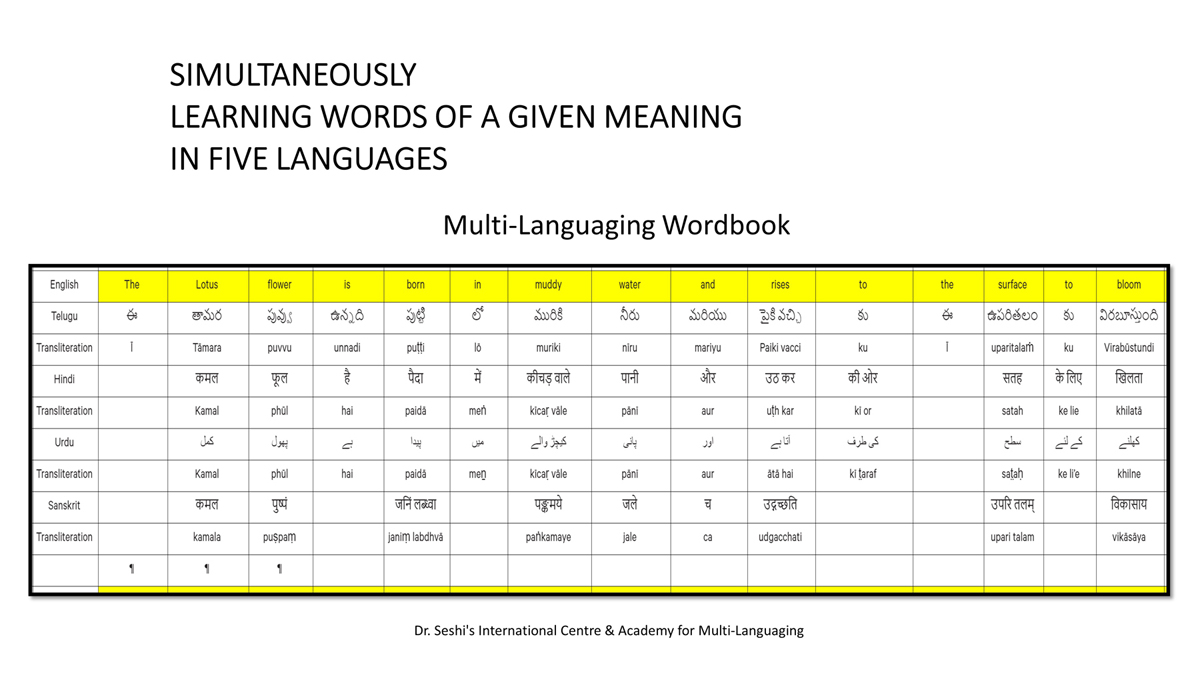
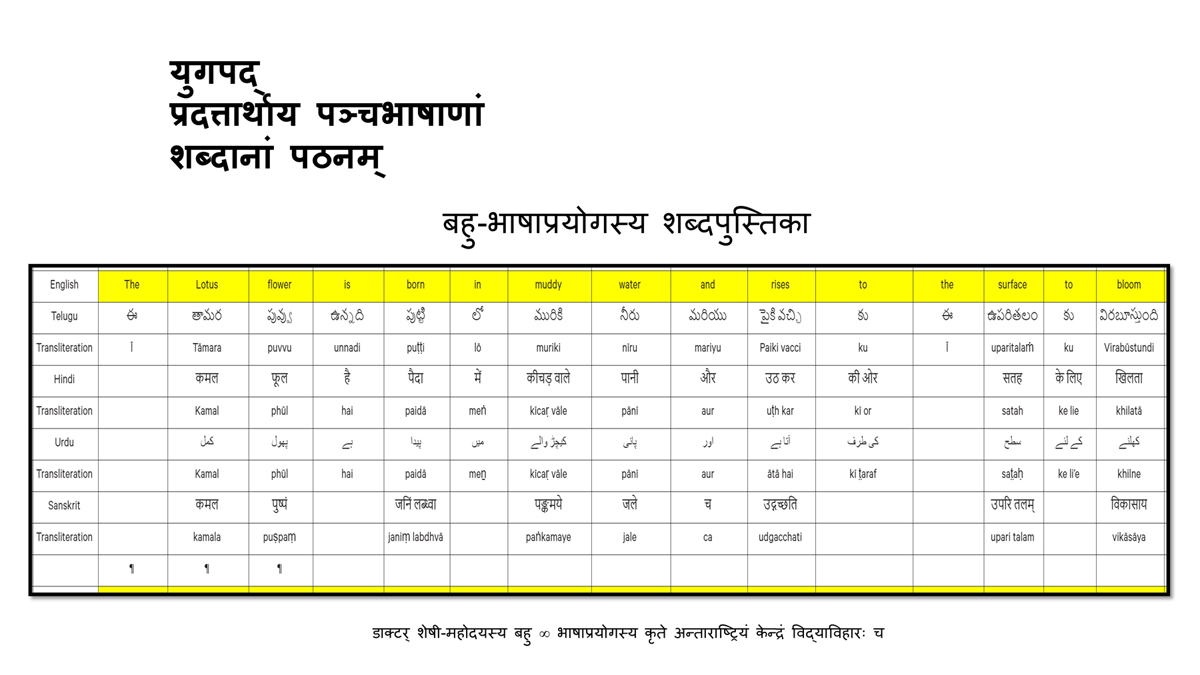
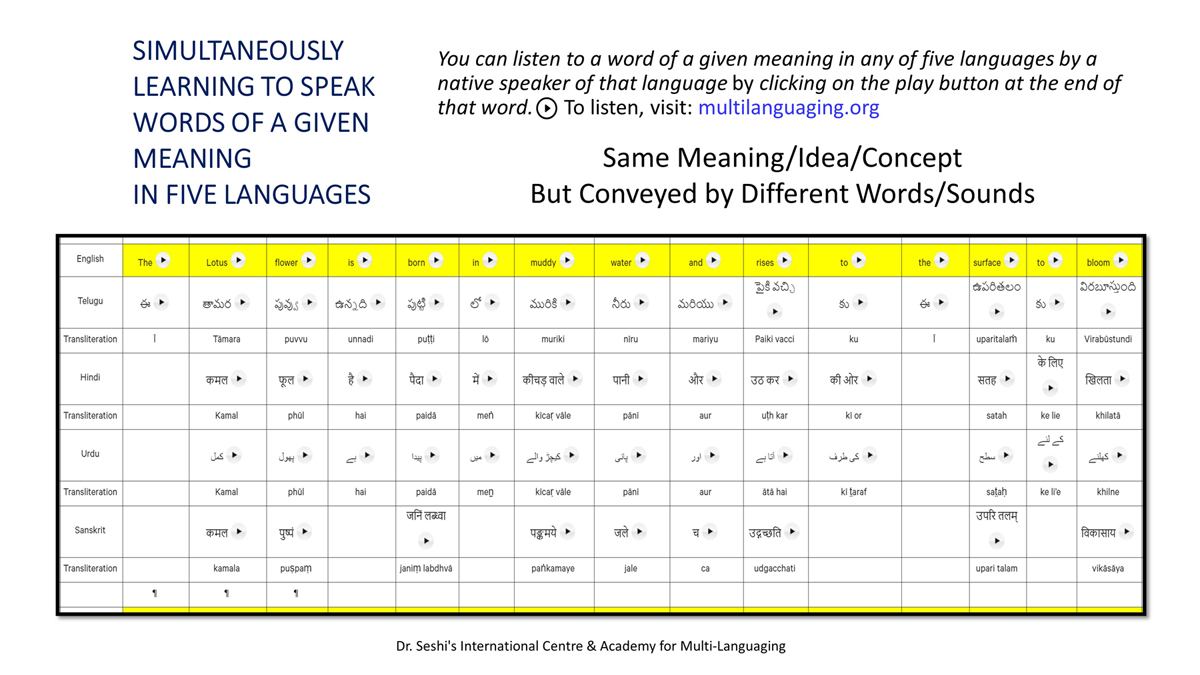
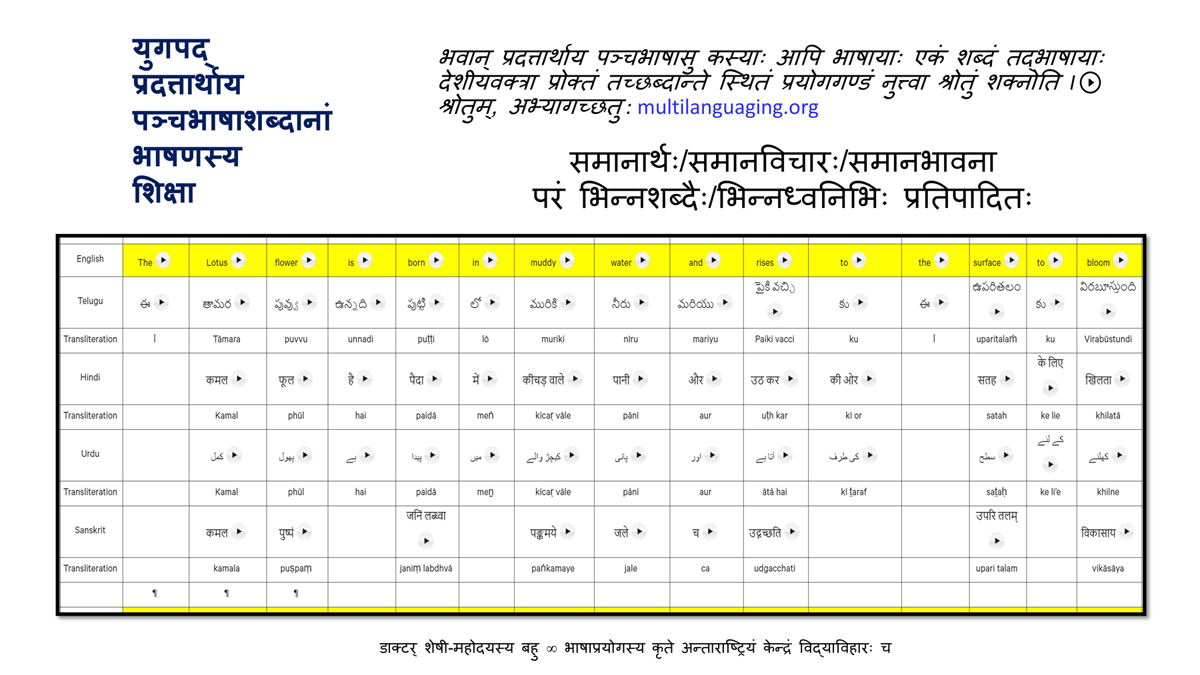
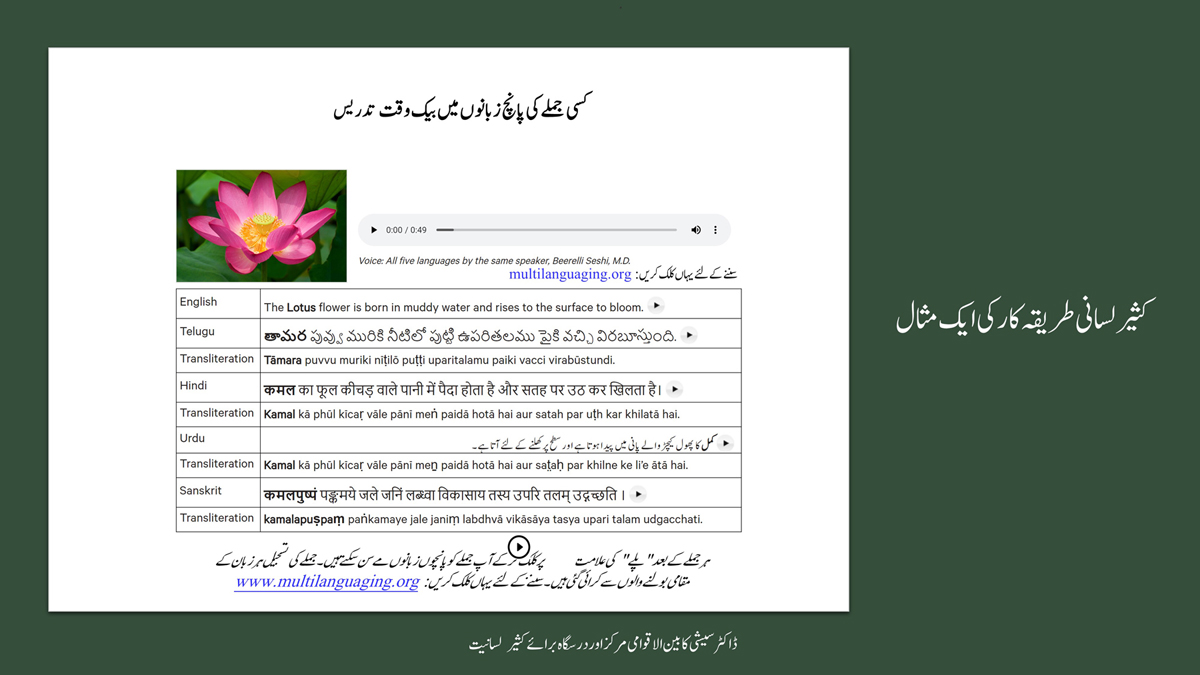
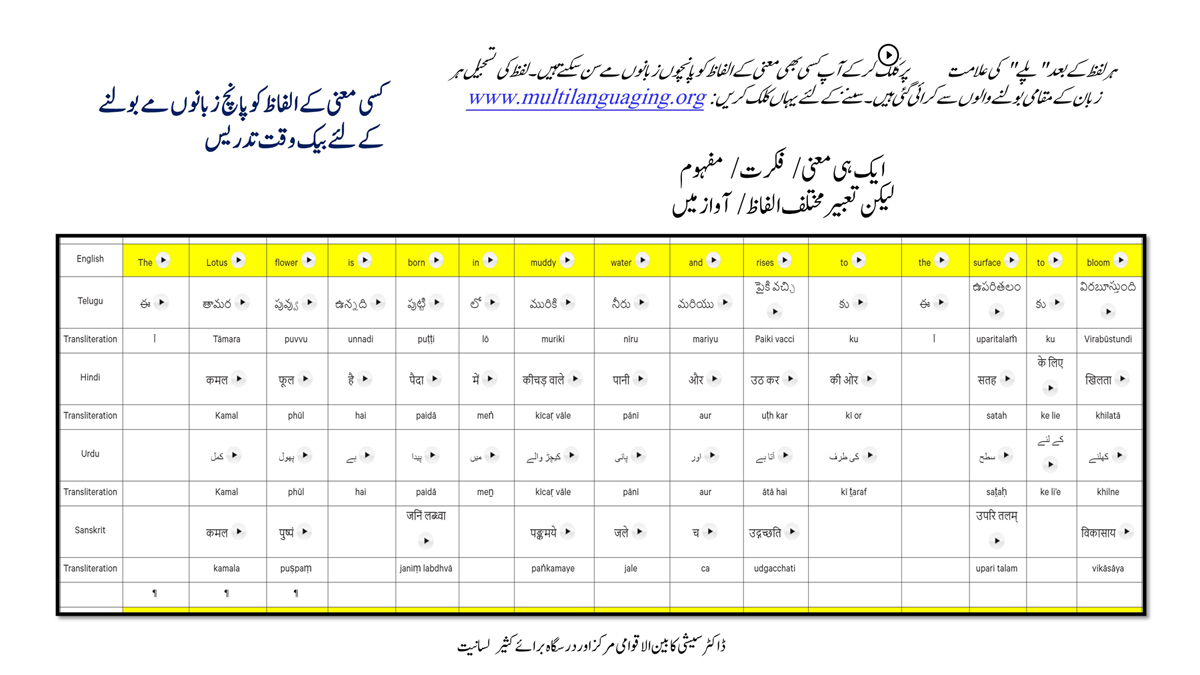
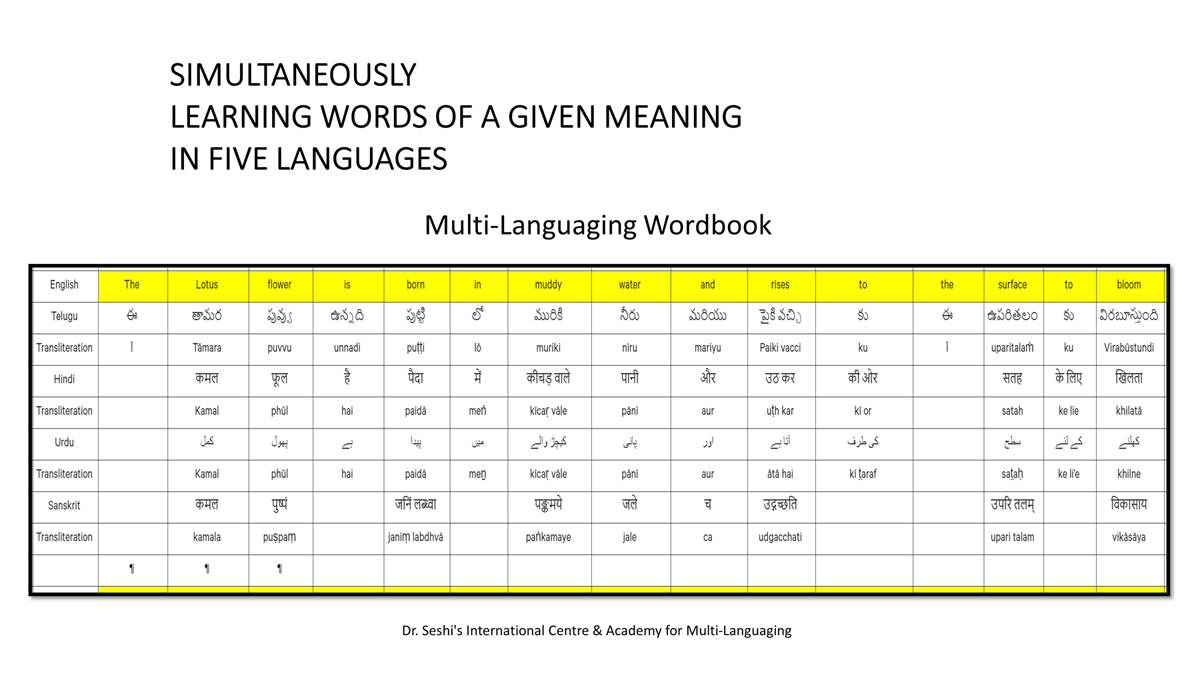
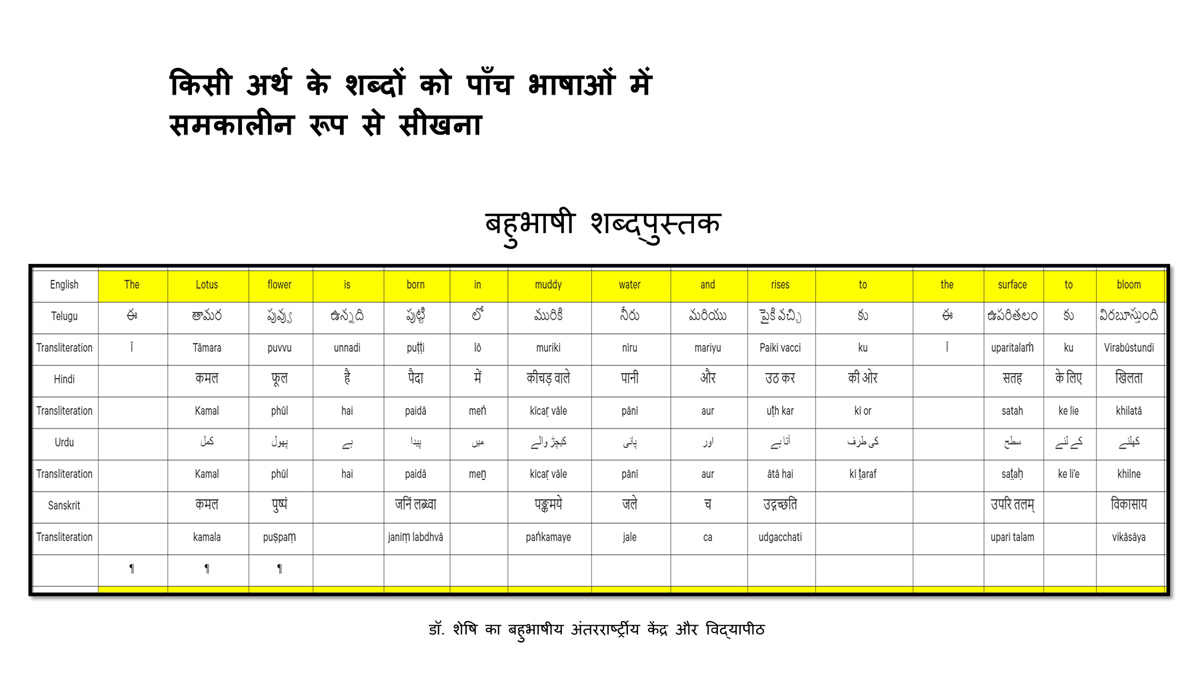
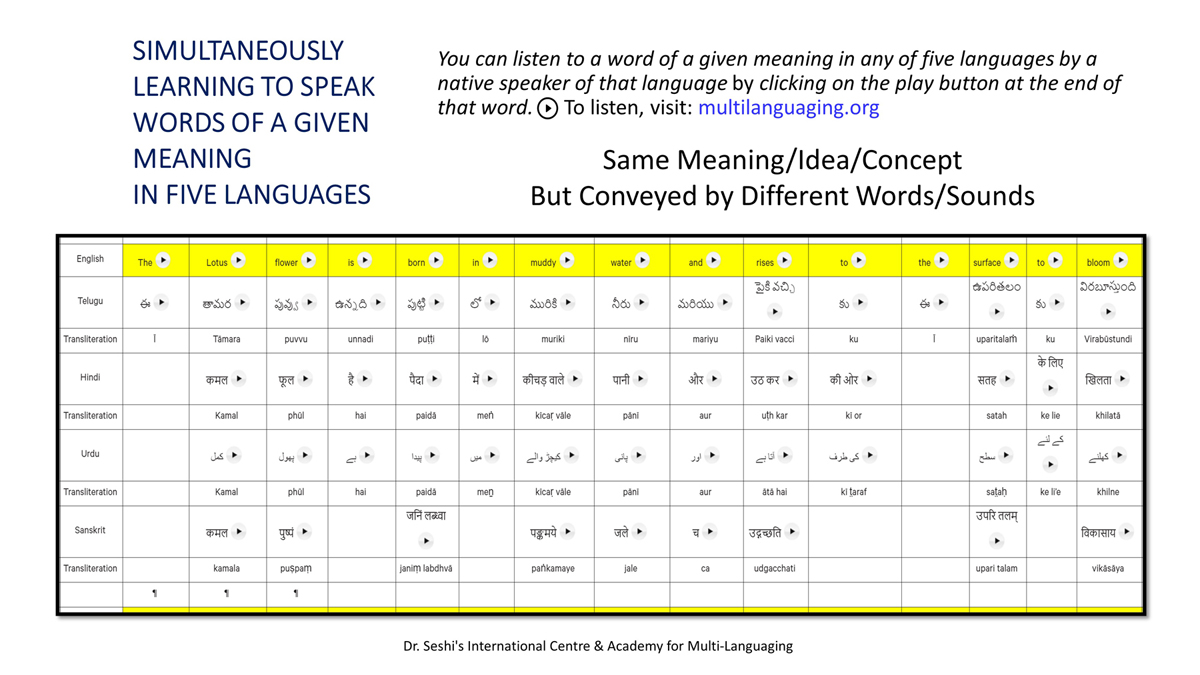
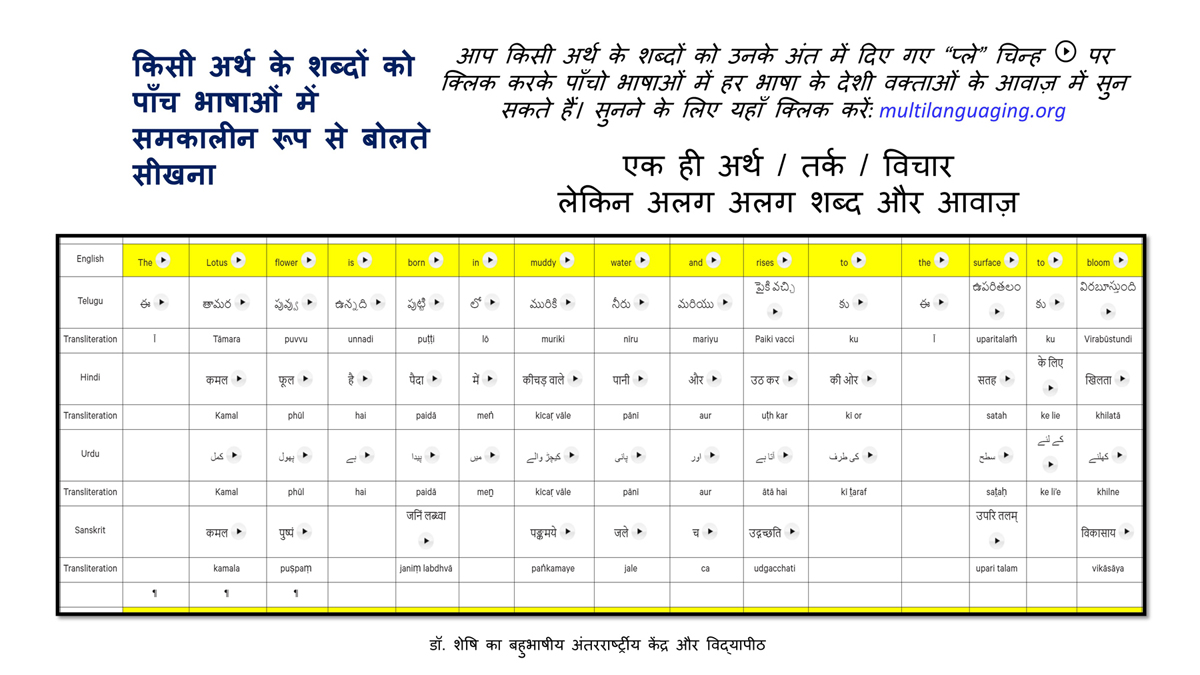
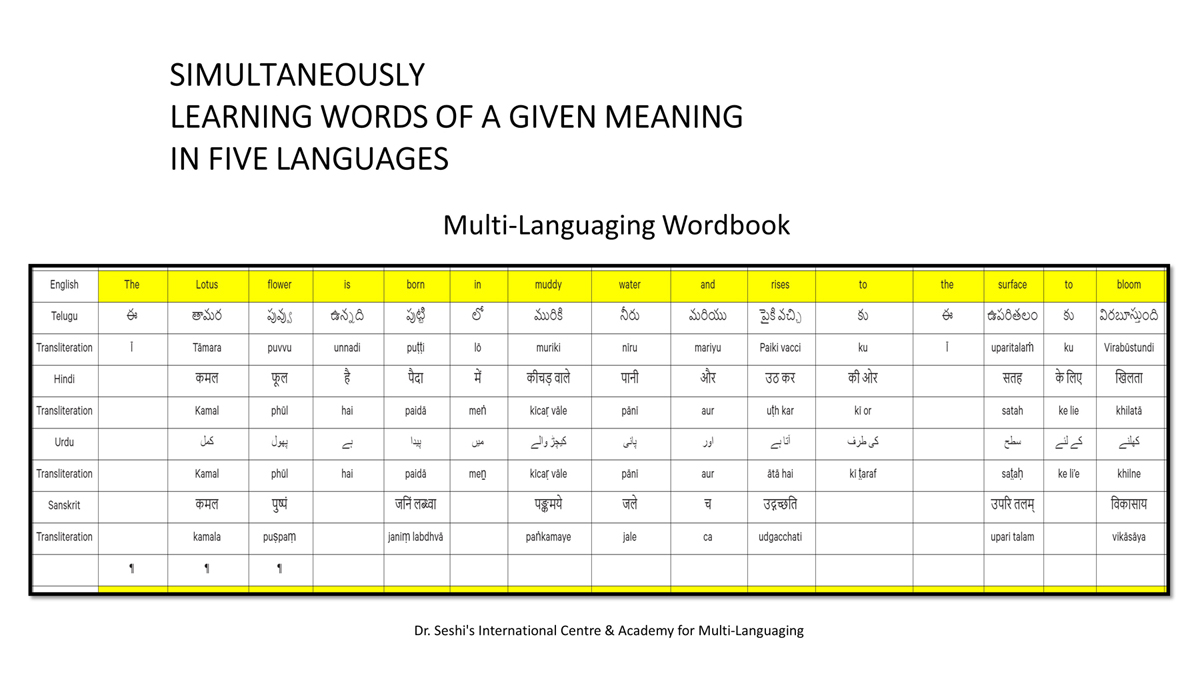
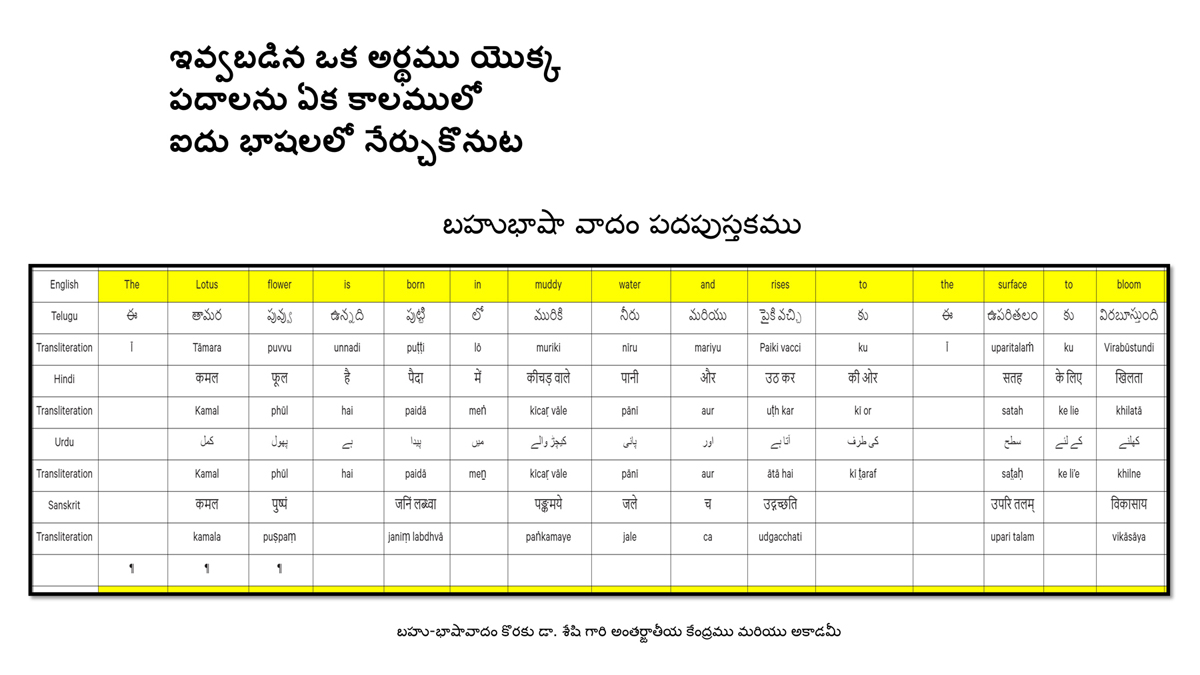
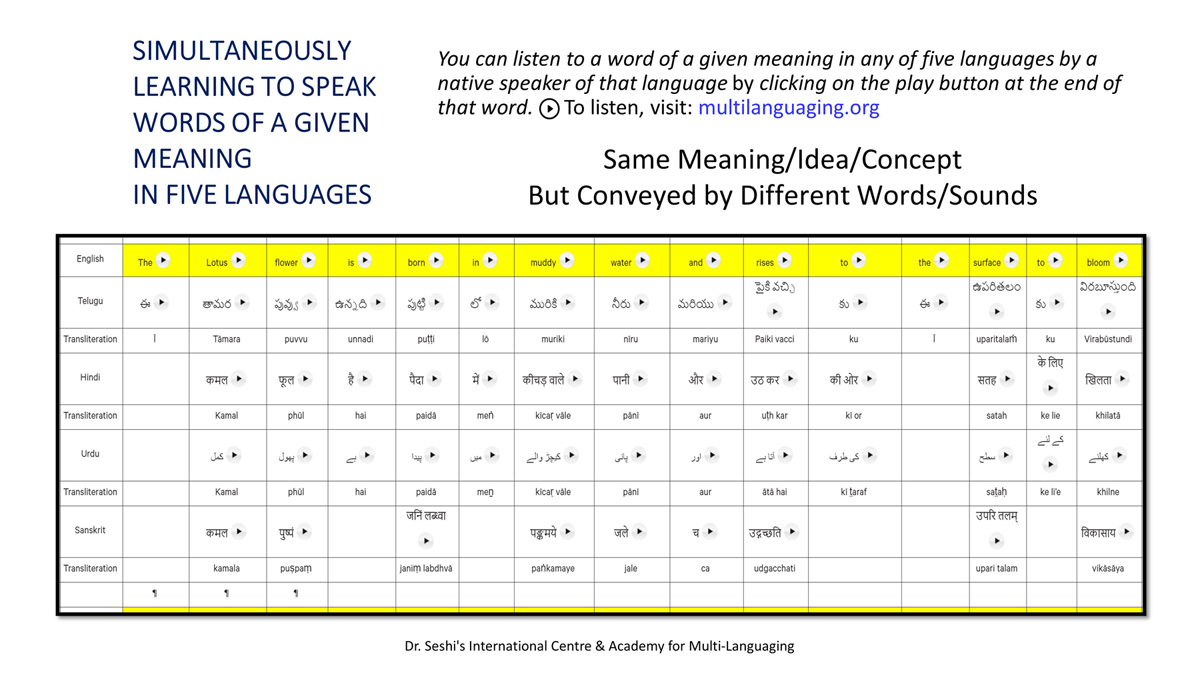
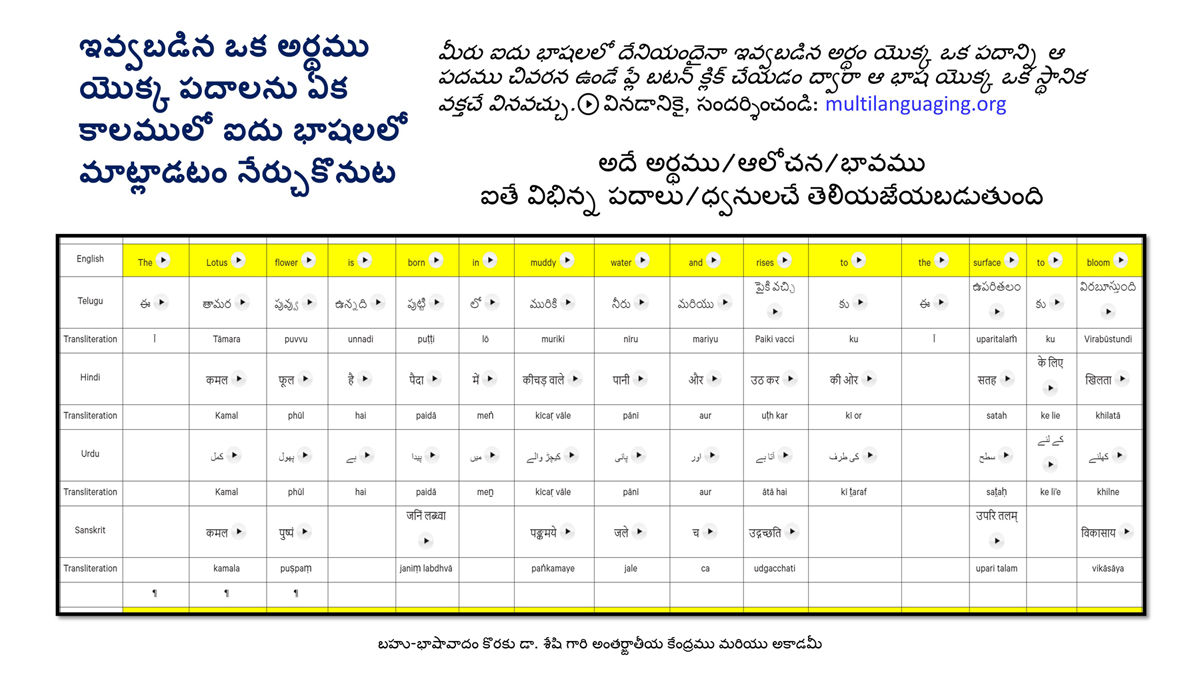
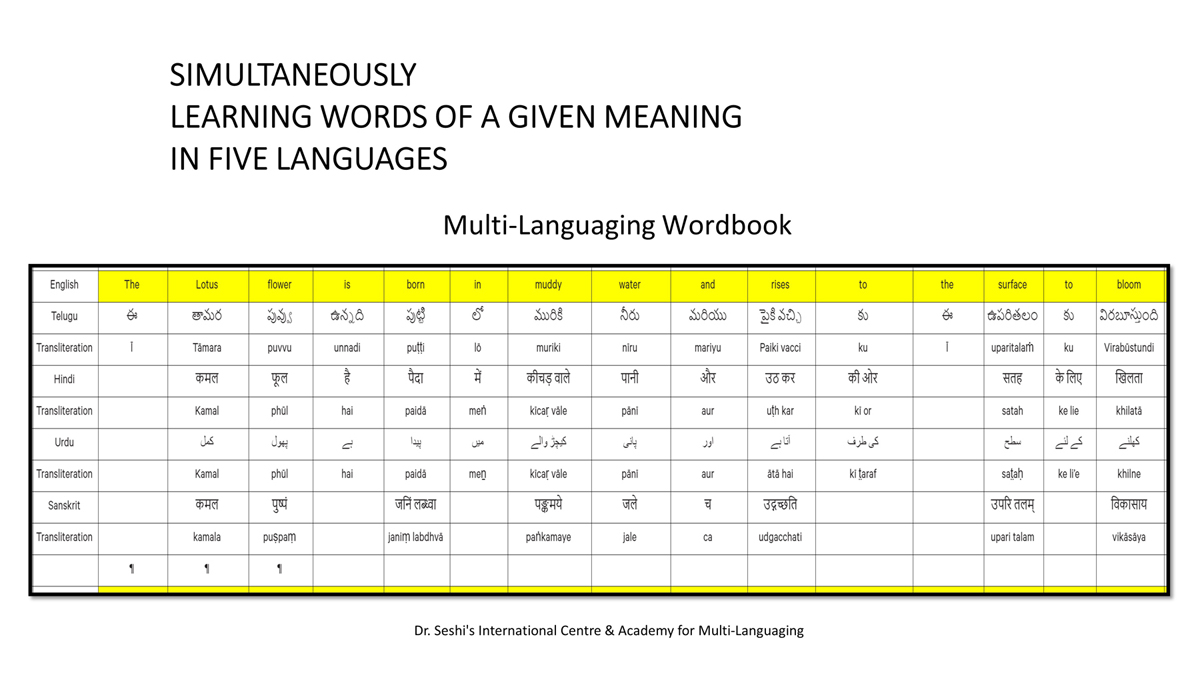
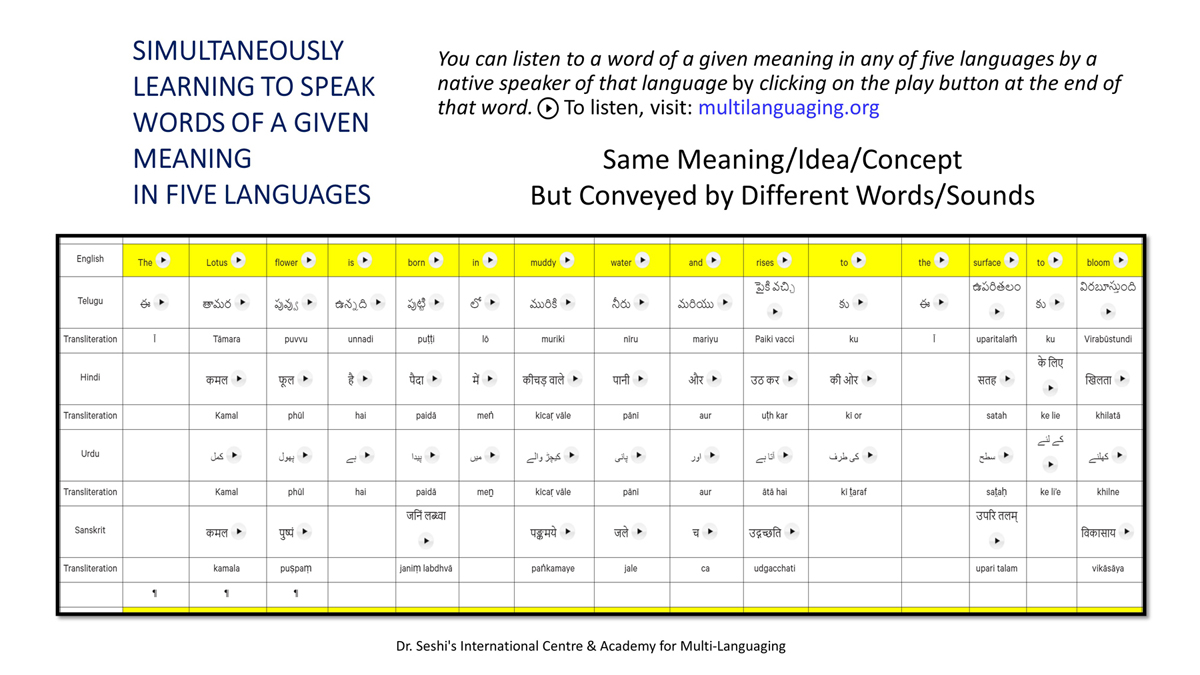
The accompanying section on "Alphabet Charts Showing Word-Level Mapping" presents the alphabet charts of five languages as children would traditionally learn them in a given language, by associating each letter with an example word that typically starts with that letter and is represented by a concrete image.
The targeted students will be pre-school children, ages 3-5 years.
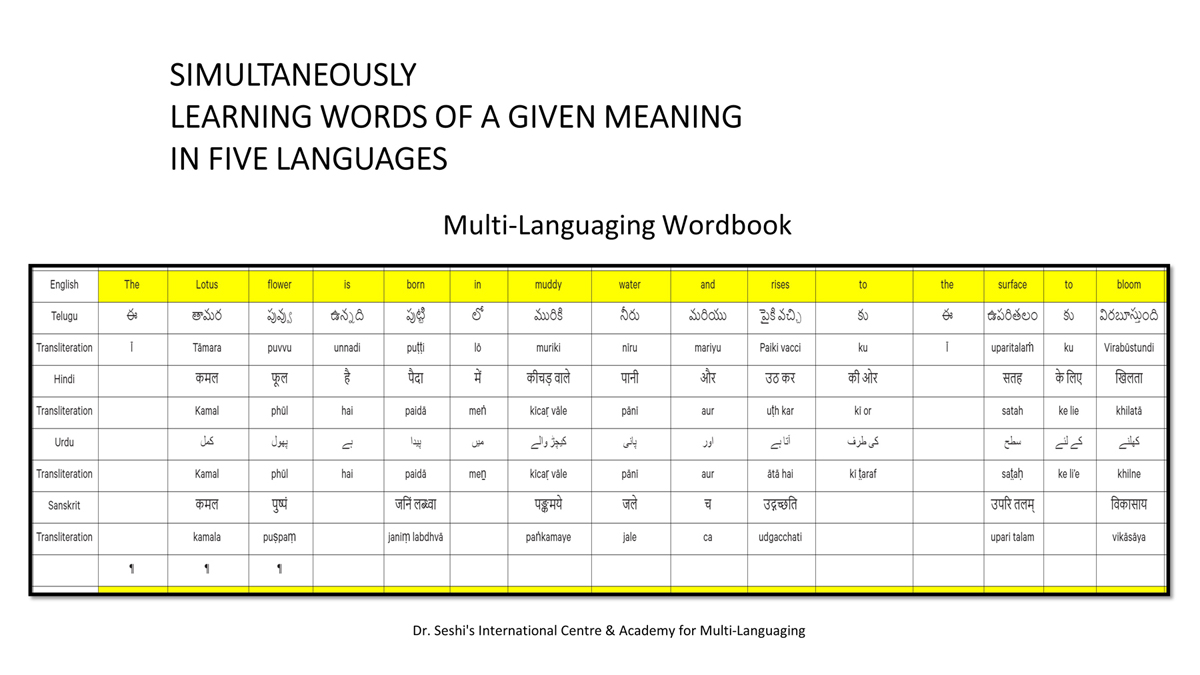
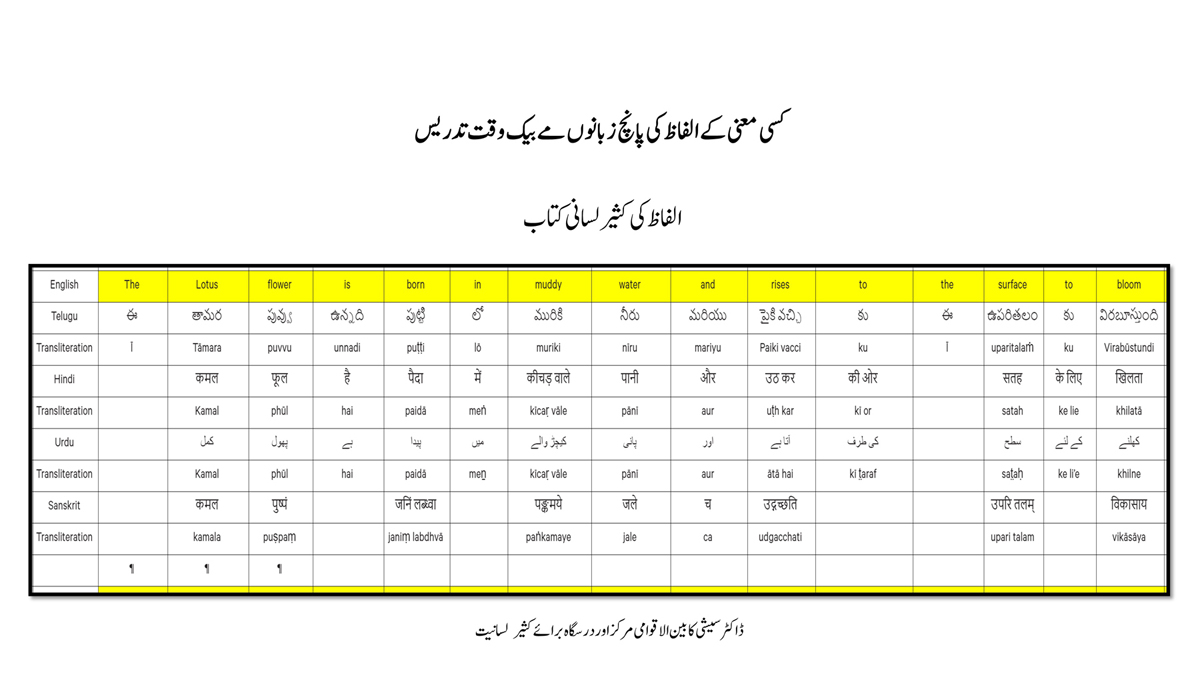
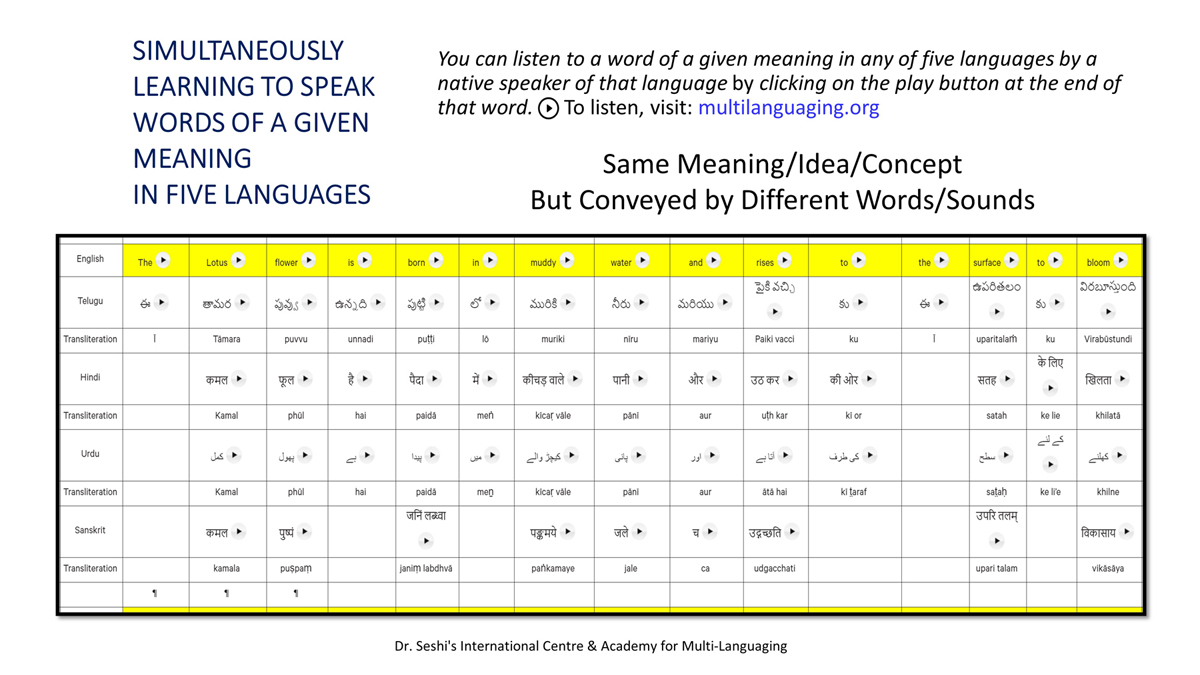
Importantly, to allow for comparative/correlative thinking and learning by their "absorbent minds," this section simultaneously introduces familiarity with the corresponding example words by translating them from each language into the remaining four languages.
The example word meanings elected to illustrate each language alphabet are exclusive to that language, without overlapping.
Considering that English, Telugu, Hindi, Urdu, and Sanskrit respectively have 26, 51, 57, 39, and 49 characters/letters, it allows for the inculcation of the young minds with the cultural value of a mosaic of 222 images/words/meanings in five different languages.
By learning two example words instead of one for each character/letter, this number will increase twofold (making it a few over 440).
This expanded scope allows the introduction of additional new meanings/concepts/ideas, especially as they may relate to the cultural mores of these languages, to the formative minds further than the standard lists of words that have been in vogue for decades would allow.
To facilitate reference and learning, I have organized these charts, 1-5, laid out horizontally from left to right―English, Telugu, Hindi, Urdu, and Sanskrit.
In future pictorial examples, voice-overs and animations will be portrayed by employing fictional teachers, like:
Ms. Saroja (for Sarojini Naidu – English)
Mr. Vema (for Vemana – Telugu)
Mr. Prem (for Premchand – Hindi)
Mr. Mirza (for Ghalib – Urdu)
Mr. Kalidas (for Kalidasa – Sanskrit)
Mix-and-match letter and/or word games and exercises will be created with the objective of integrating the knowledge of all five language alphabets learned.
Envision a child with a mastery of the alphabets as outlined above, going to school feeling empowered, like a juggernaut or colossus, with full confidence.
As we progress on this project, and as mentioned above and discussed under FAQ 13, we may need to write a smartphone app, prepare a video, or even create a video game treating the letters as human characters in a play, highlighting the similarities and differences between these alphabets.
Furthermore, lullabies or nursery rhymes focused on alphabets can be written and joyfully sung.
This will help achieve the comparative teaching of these alphabets with a hilarious effect.
Ultimately, this multi-languaging project is expected to promote the preservation of the diversity of scripts and languages from extinction, as they embody an integral part of human culture and history.
For now, it suffices to be able to see their close relatedness, or lack thereof.
The following transliteration (Romanization) schemes are used in this multi-languaging project:
Devanagari – Sanskrit: International Alphabet of Sanskrit Transliteration (IAST)
Devanagari – Hindi: Library of Congress (LoC) system
Telugu: LoC system
Urdu: LoC system
It may help to know that IAST and LoC systems are, in fact, similar.
It is hoped that the above groundwork will pave the way as we progress toward implementing the idea of teaching scripts concurrently.
At this stage of the project, this "Introduction" on alphabetics is targeted primarily for adult learners, parents, teachers/educators, software developers, policy decision makers and interested citizens.
This work undoubtedly will help prepare the appropriate tools (software or otherwise) needed for simultaneously teaching these scripts to pre-school children, which is the eventual goal.
Finally, it is important to keep in mind that the information presented is by no means complete and may not have addressed all the nuances and intricacies which are expected to be learned in classroom.
See the accompanying "References" section for a detailed picture.
Acknowledgment:
I thank the anonymous linguists, Mr. SS and Mr. TS, for offering strong encouragement, critical review, and helpful comments in preparing the Alphabetics documents.






































प्रदीपकदृश्यार्थम् अत्र नुदतु
प्रदीपकदृश्यस्य सरद्बिम्बप्रदर्शनार्थम् अत्र नुदतु





































وضاحتی ویڈیو کے لئے یہاں کلک کریں
وضاحتی ویڈیو کے سلائیڈ شو کے لئے یہاں کلک کریں






































व्याख्यात्मक विडियो के लिए यहाँ क्लिक करें
व्याख्यात्मक विडियो के स्लाइड शो के लिए यहाँ क्लिक करें





































వివరణాత్మక వీడియో కోసం ఇక్కడ క్లిక్ చేయండి
వివరణాత్మక వీడియో స్లైడ్ షో కోసం ఇక్కడ క్లిక్ చేయండి



















Click here for Explainer Video
Click here for Explainer Video Slideshow