
Read Me First
 An Explanatory Note About the Documents and Their Translations
An Explanatory Note About the Documents and Their Translations
Beerelli Seshi, M.D.
BSeshi@multilanguaging.org
BSeshi@outlook.com
"Change your language and you change your thoughts."
Karl Albrecht

Beerelli Seshi, M.D.
An Explanatory Note About the Documents and Their Translations Beerelli Seshi, M.D.
BSeshi@multilanguaging.org
BSeshi@outlook.com
The documents included here, along with their translations, are:
DOC1 – Founder and President’s Message
DOC2 – Content, Syllabus and Curriculum
DOC3 – Biographies
DOC4 – Frequently Asked Questions (FAQs) and Answers, Read Me First and Read Me Last—What Next?
Dr. Seshi wrote these documents originally in English.
They have been translated into the four languages Telugu, Hindi, Urdu and Sanskrit by native professionals/experts.
Translations of the project documents are presented in three different ways:
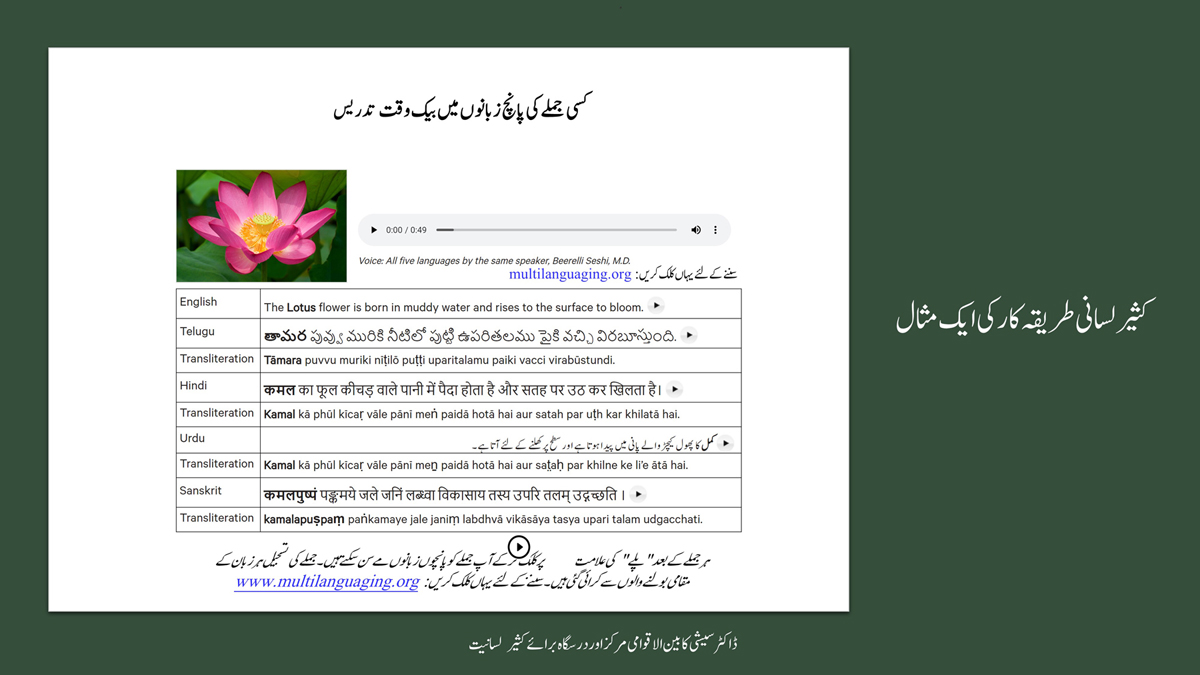
i) Continuous single-language or stand-alone format (DOCs 1-4):
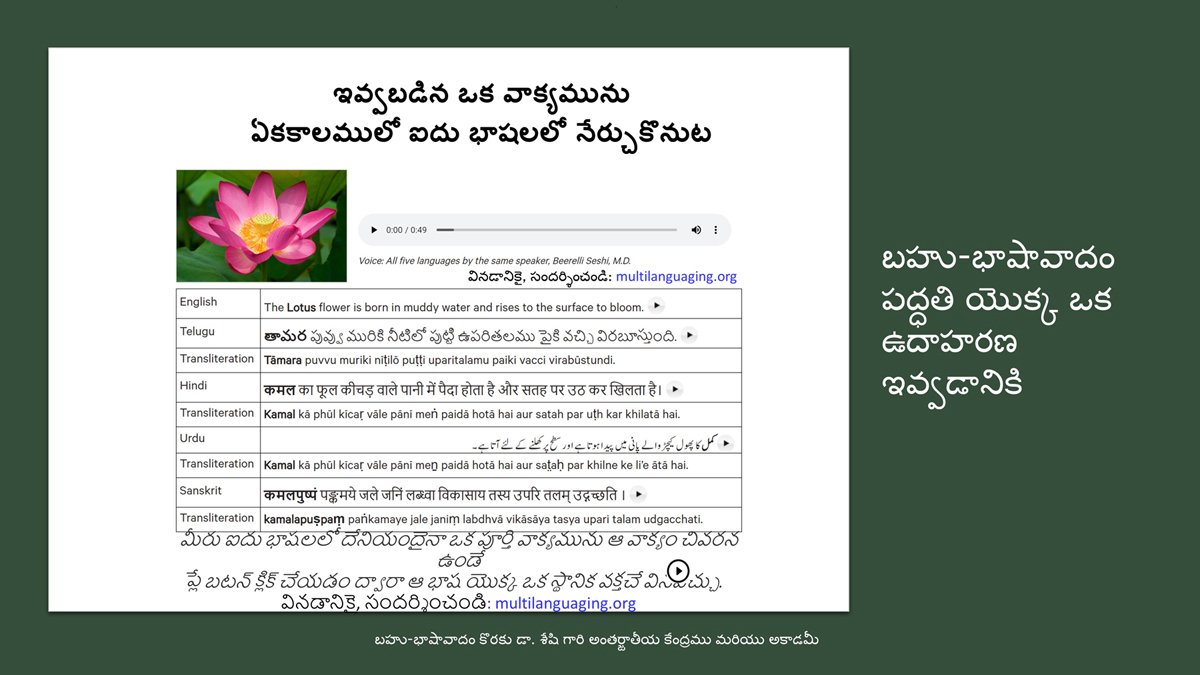
ii) Sentence-by-sentence (triplet) format (DOCs 1-4):
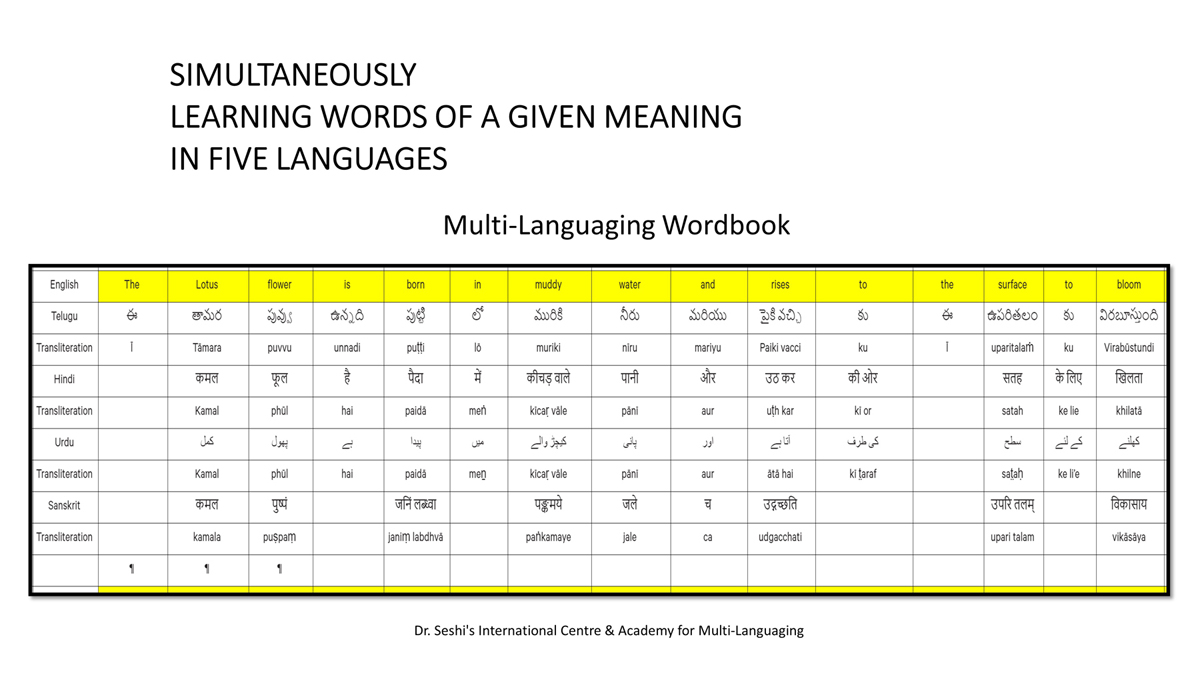
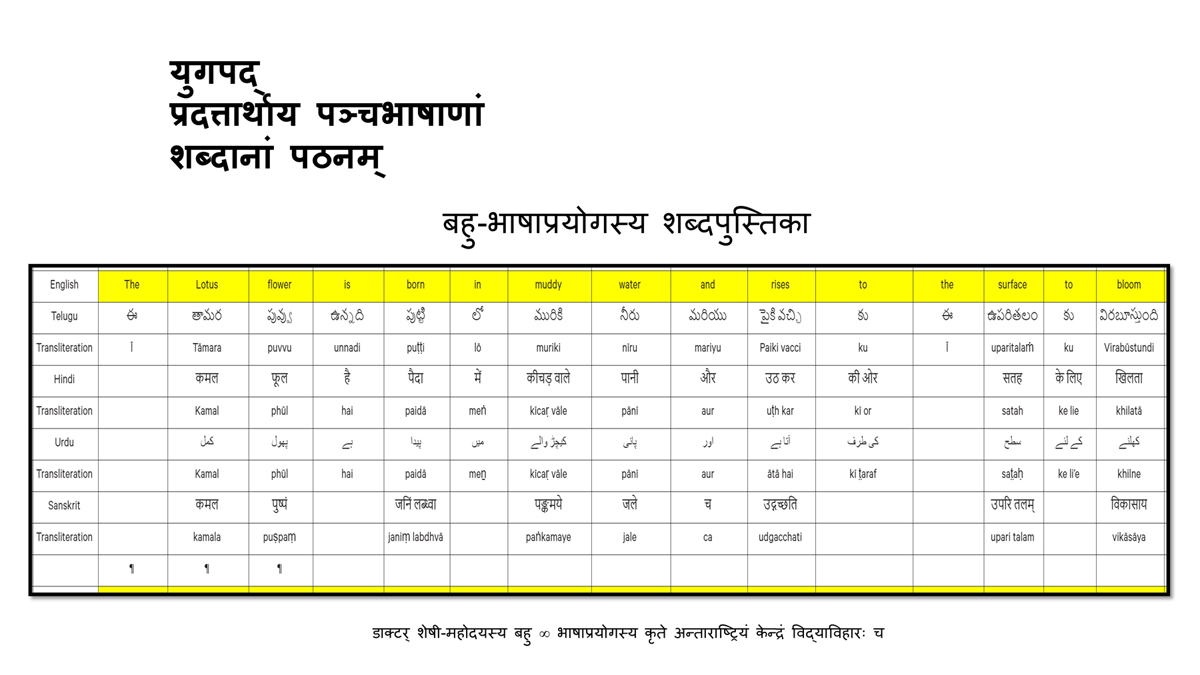
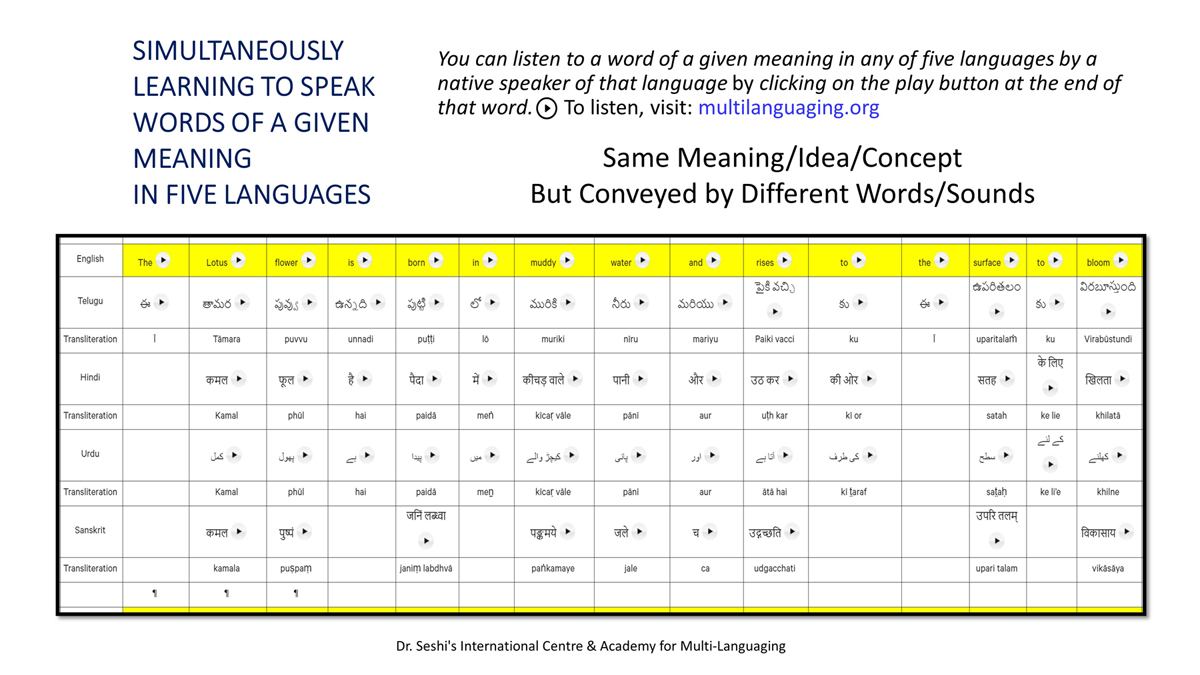
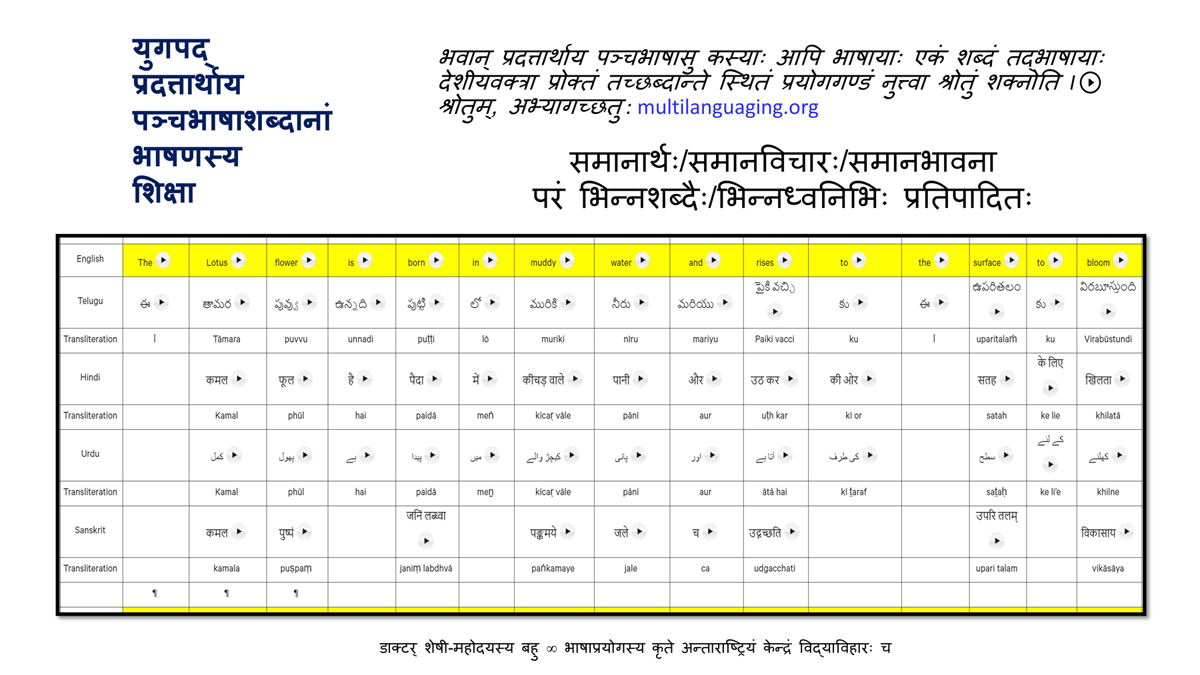
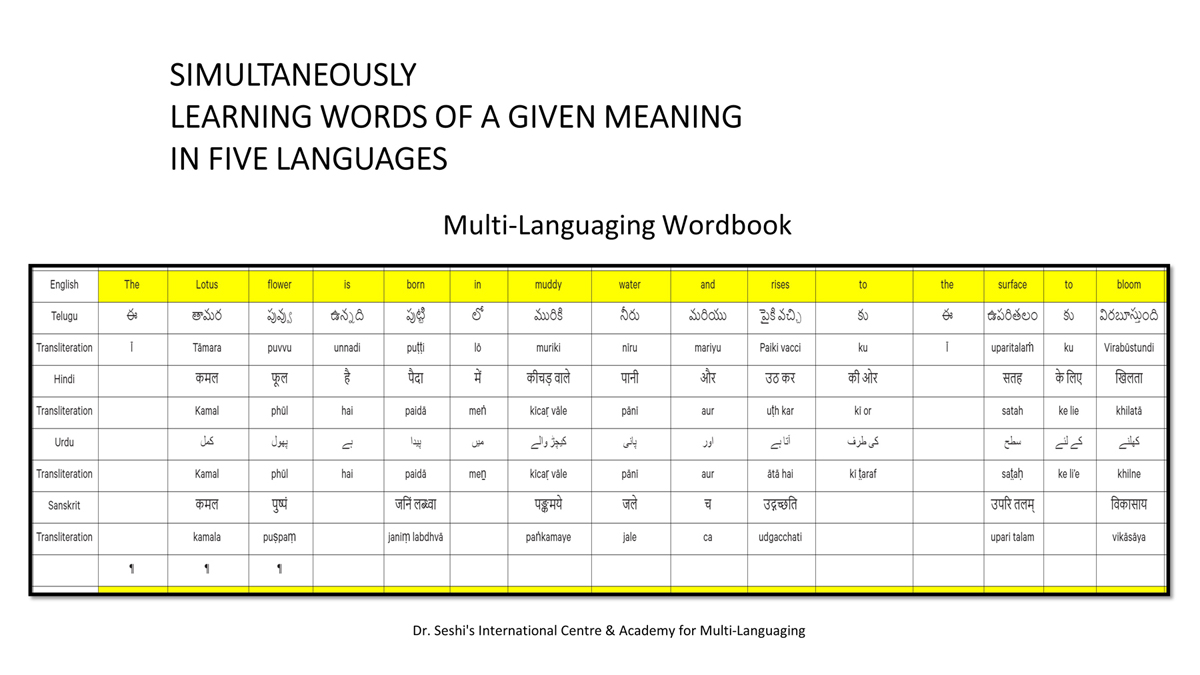
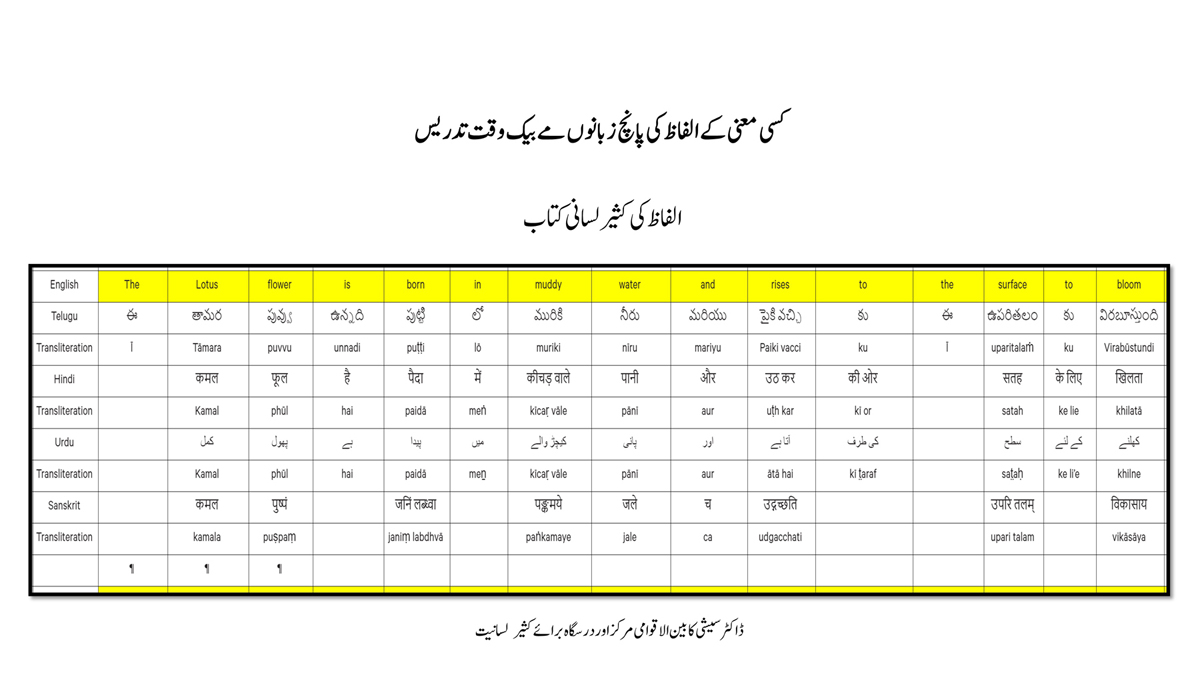
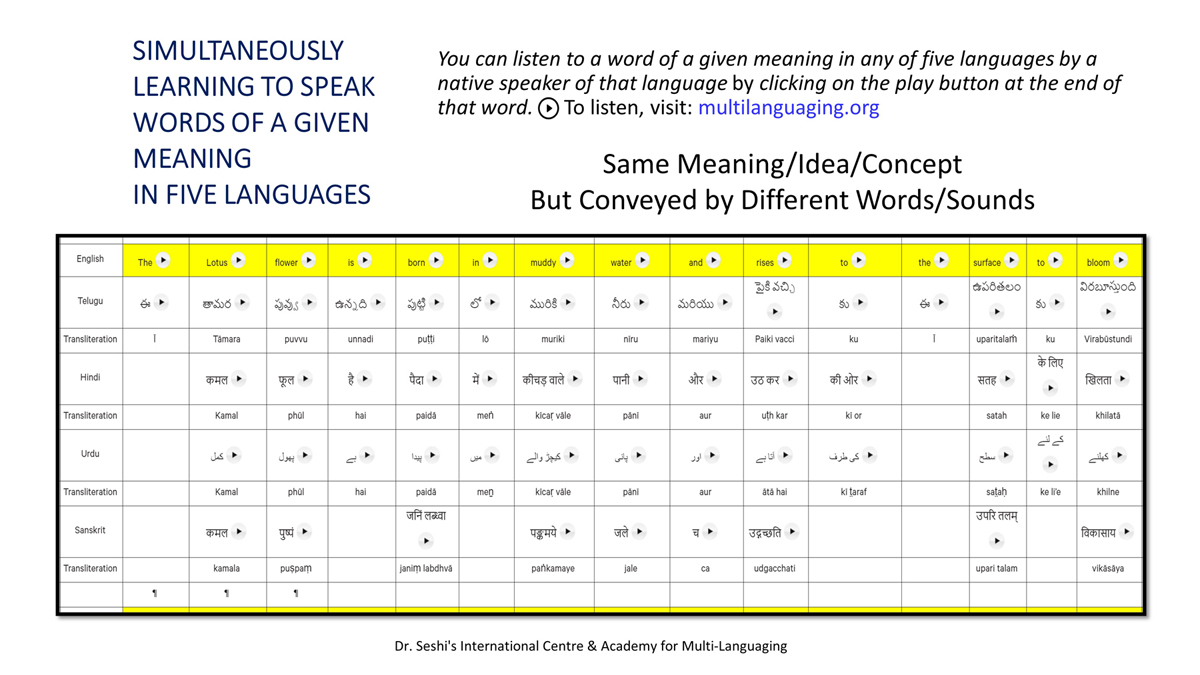
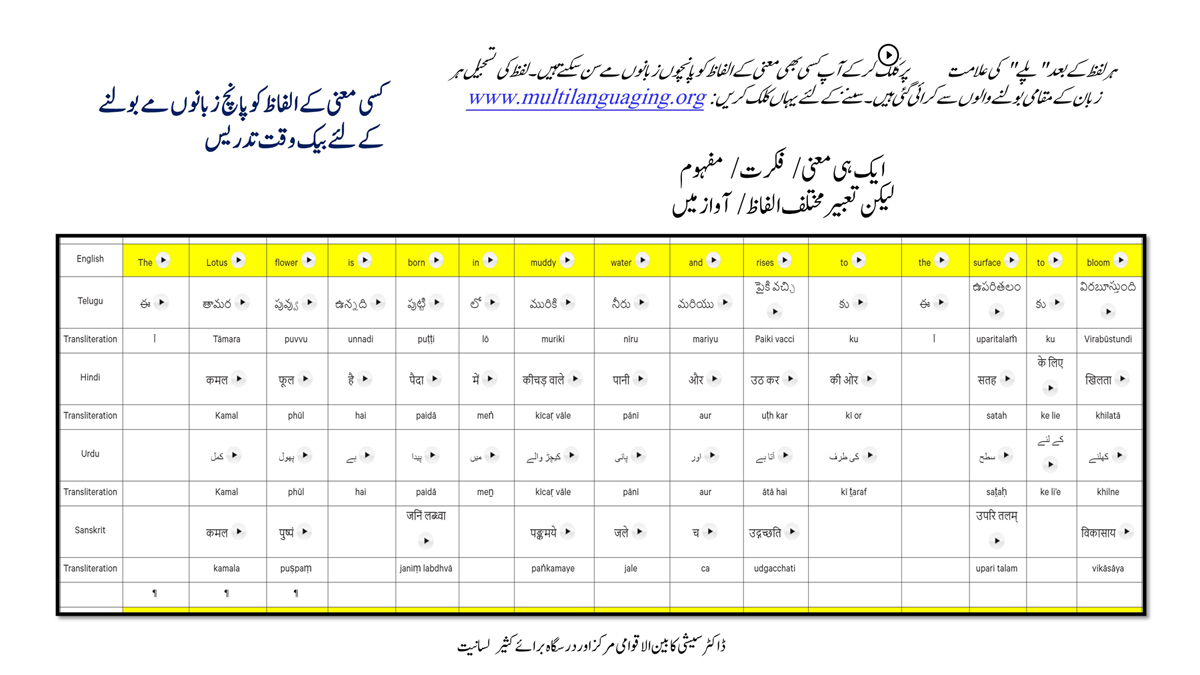
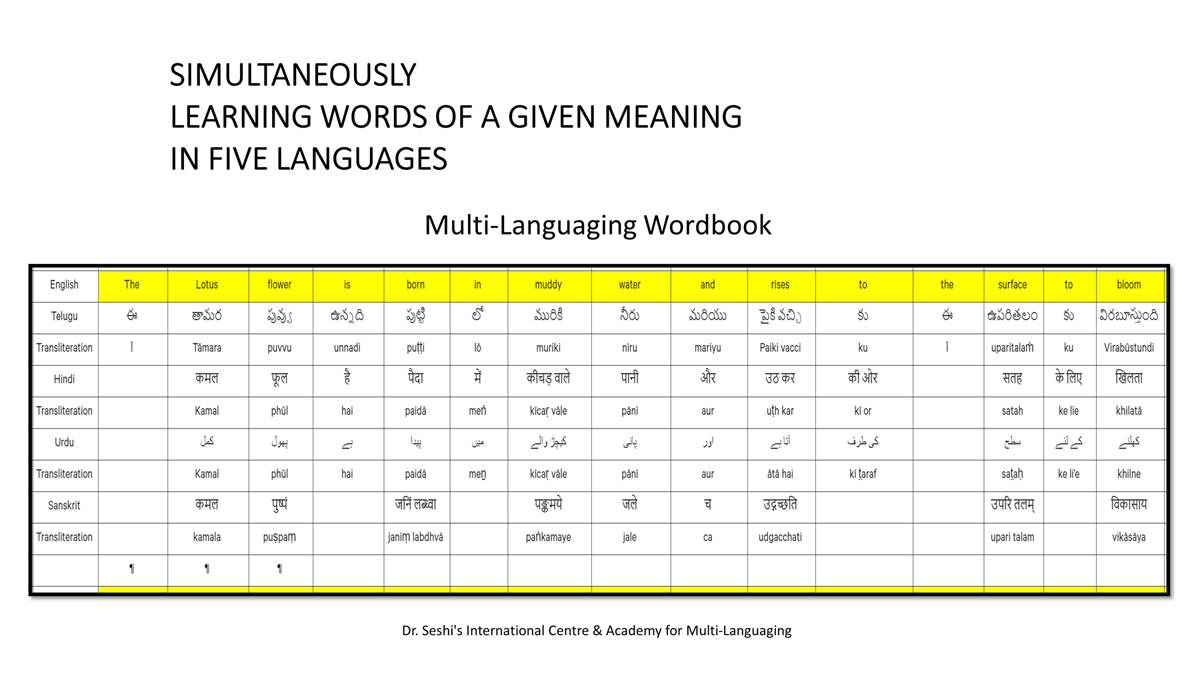
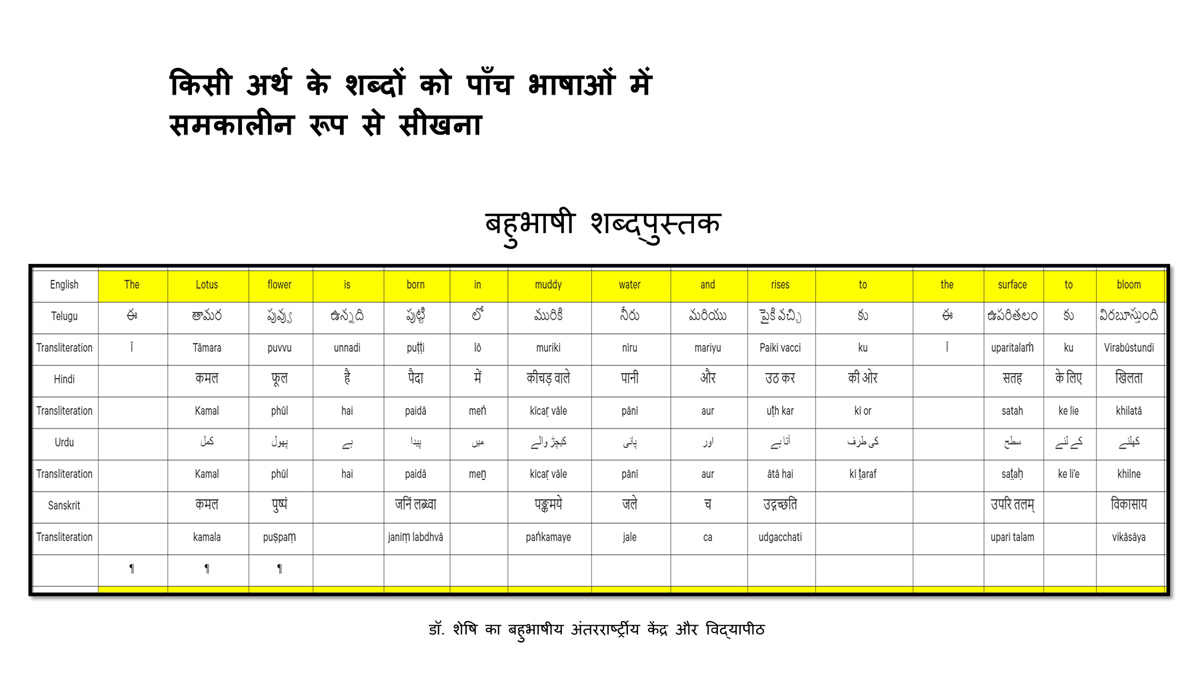
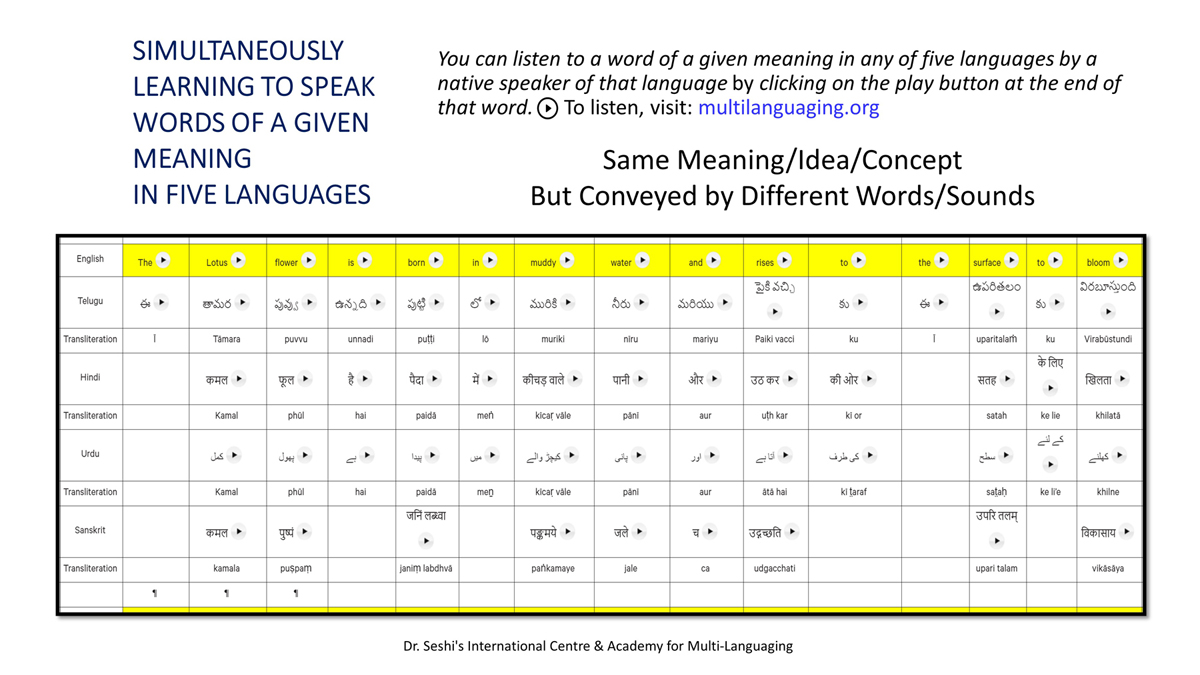
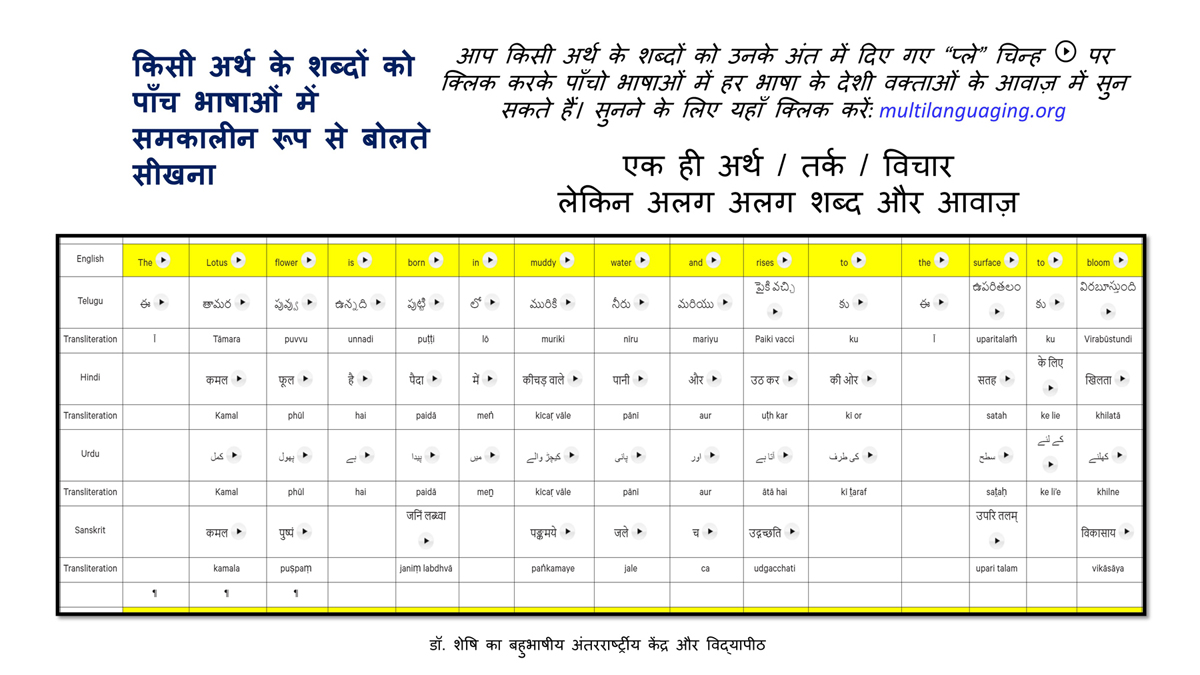
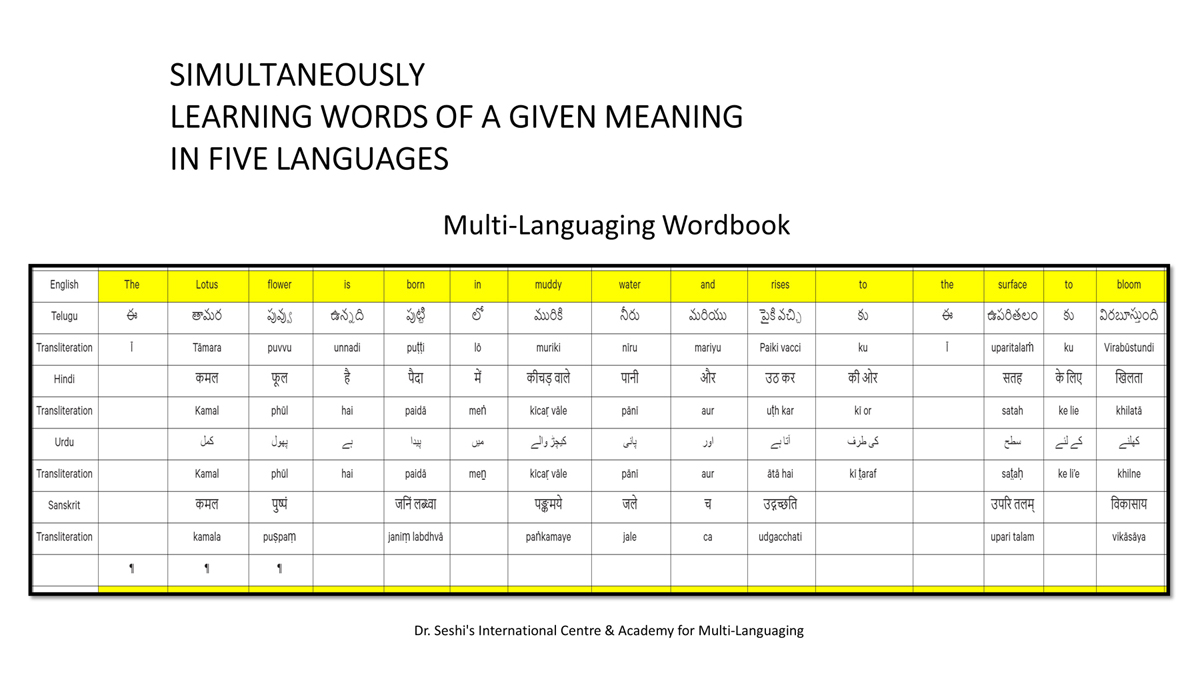
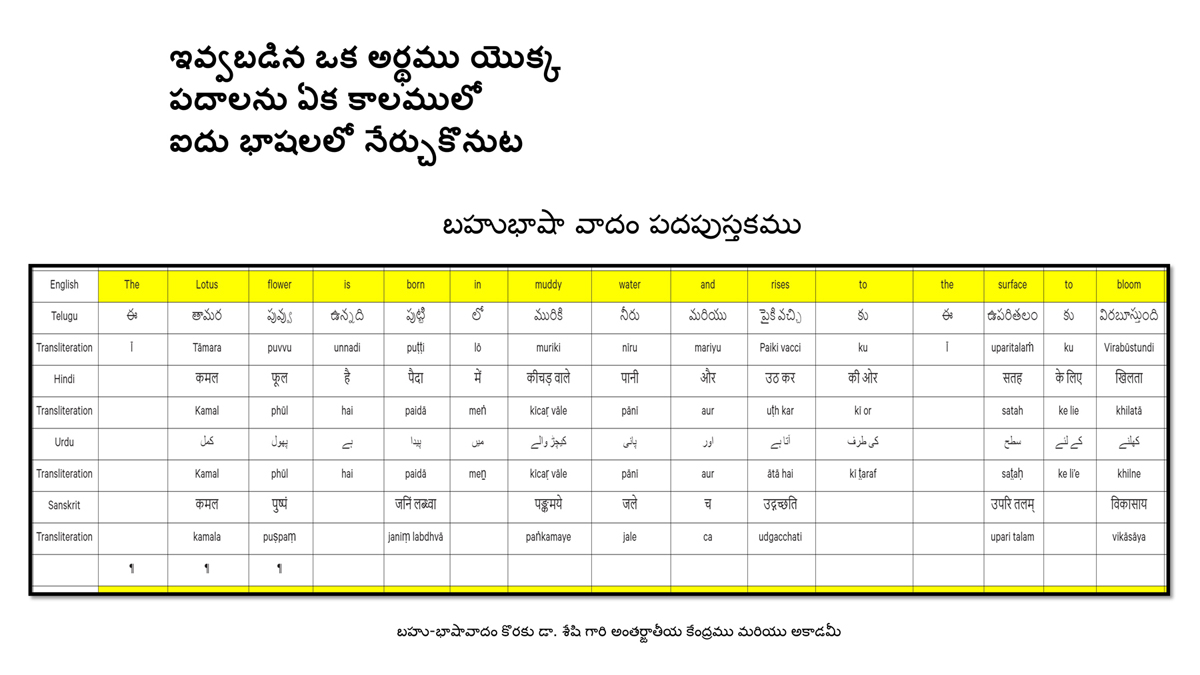
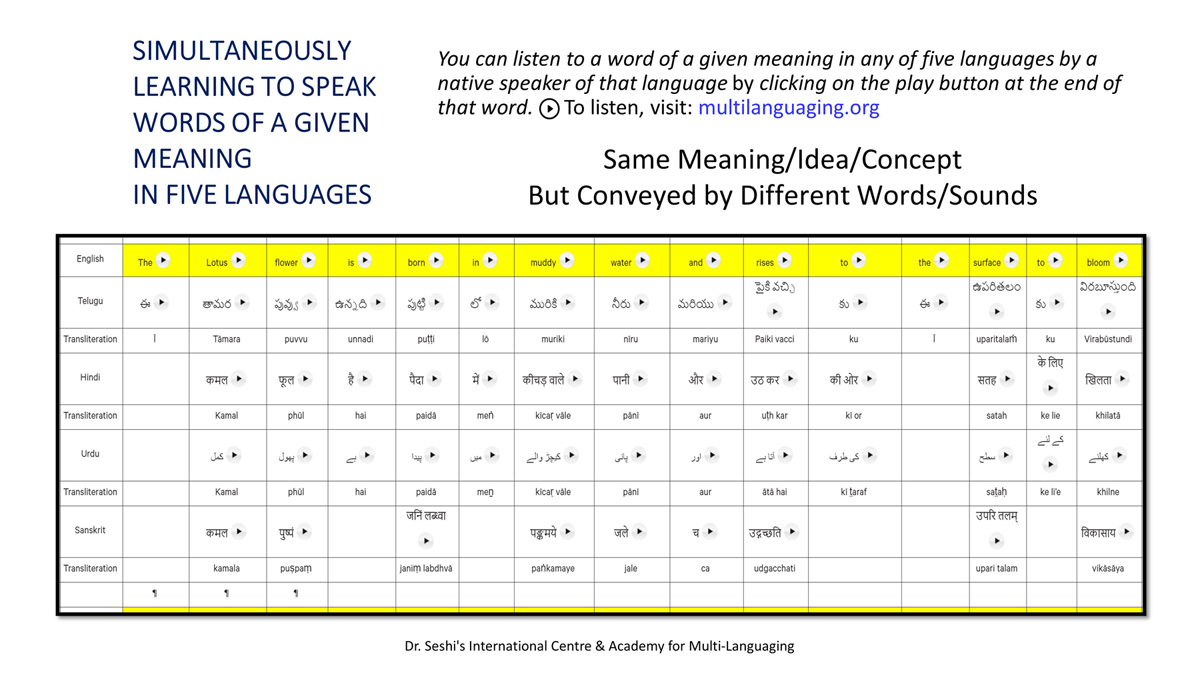
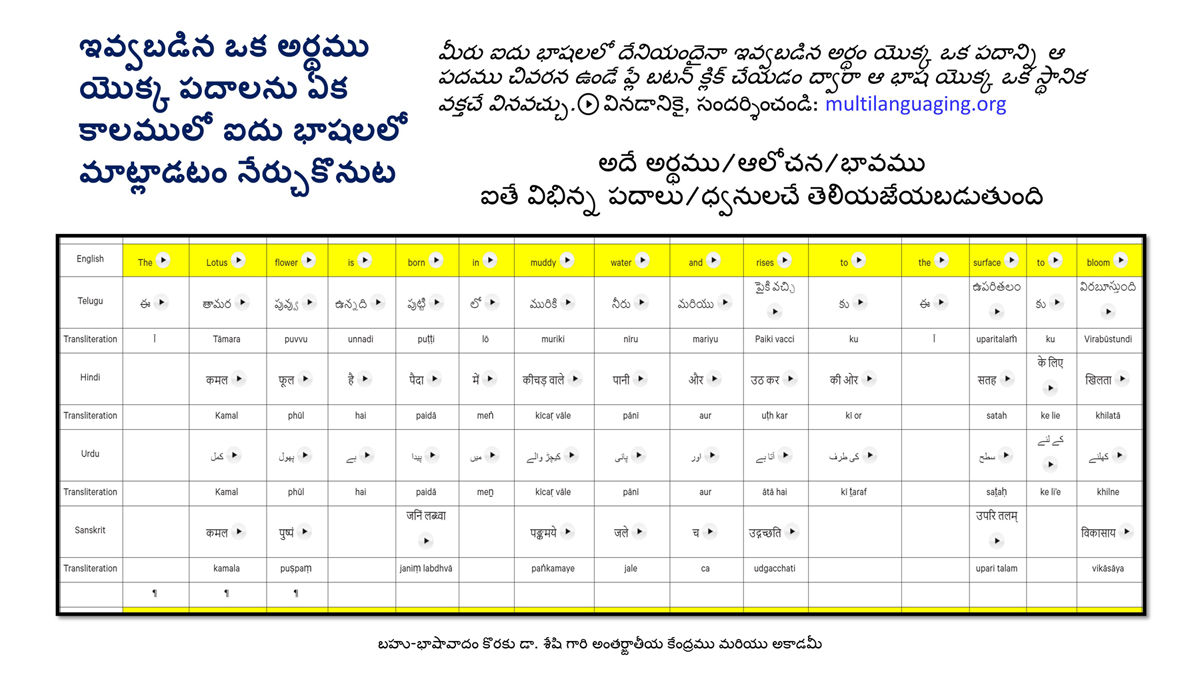
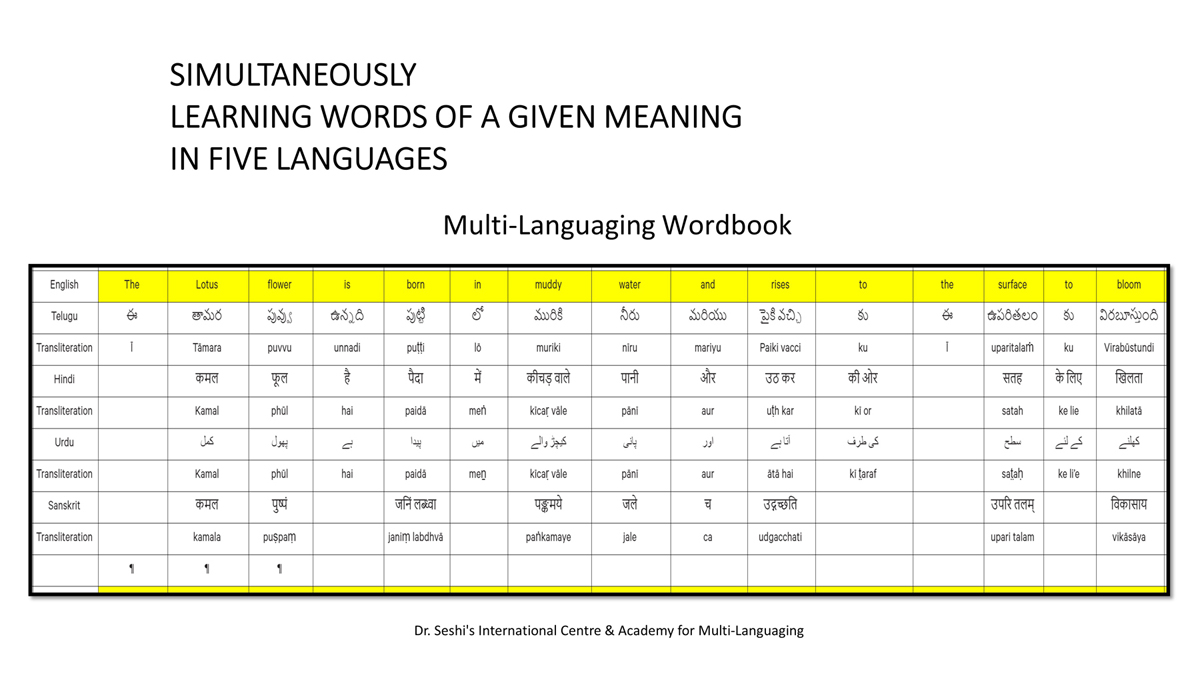
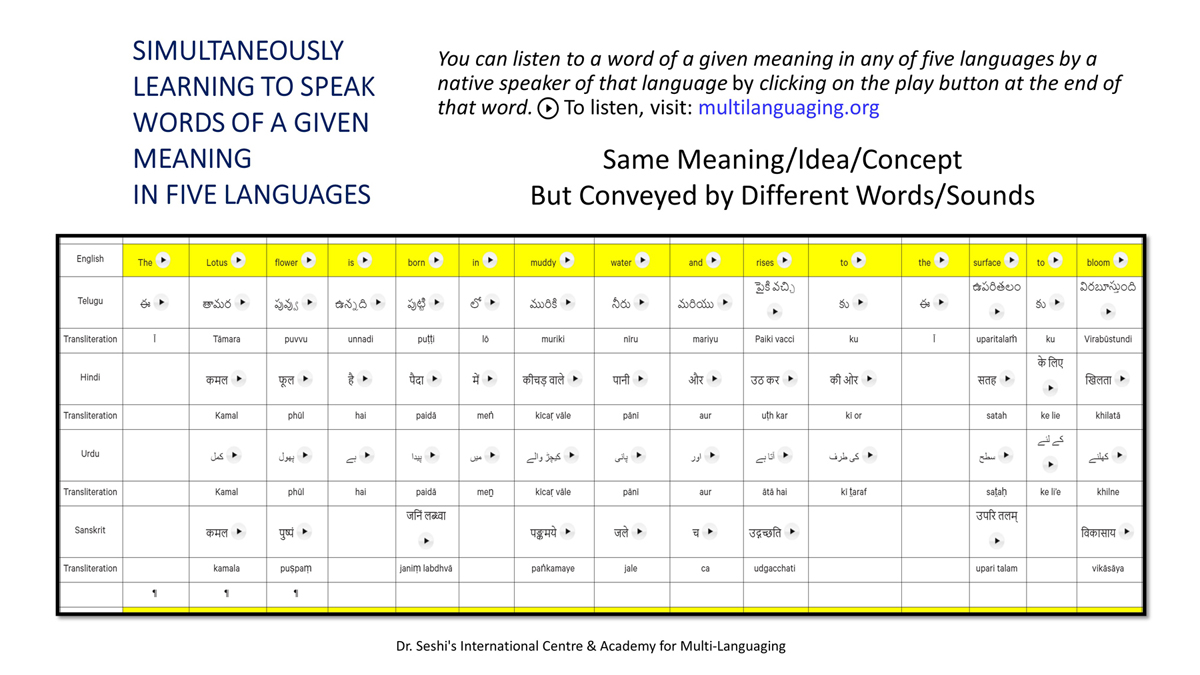
iii) Word-by-word format using spreadsheets (DOCs 1, 2 and 4):
It is possible that for the same word in one language (for example, for "water" in English) there may be two equally appropriate words in another language ("jal" and "udaka" in Sanskrit, in this case).
Similarly, for a word like "hoped" in English, there may be two equally appropriate expressions in Urdu ("tawaqqo ki jati" and "umeed ki jati").
Correspondingly, for a word like "providence" in English there may be two equally suitable words in Telugu ("bhagavanthudu" and "devudu") and in Hindi ("ishwar" and "bhagavaan").
The same issue would arise if translation were to be done from one of these languages into English—for example, "hoped" has several appropriate synonyms, like "wished," "longed" and "desired."
Keeping this in mind, care has been taken and cross-checking has been done to maintain consistency of translation according to the context among all three formats―for a given word in each sentence in each language.
That some words have several meanings will be discussed in the class.
There exist many common words or roots among some or all of these languages (Telugu, Hindi, Urdu and Sanskrit), but this is not evident in writing because of their different scripts.
The purpose of the use of transliteration is to:
When considering class textbook lessons as part of the "Our Languages" subject:
It should be further realized that unlike class textbook lessons, DOCs 1-4 are necessarily advanced documents meant mainly for parents, educators, policy decision makers and interested citizens.
Long sentences can become too unwieldy to read in the spreadsheet Wordbook format.
Also, one is not expected to go to a Wordbook to look up the word-by-word translation for a word obvious within the standard translation (five-sentence format or full lesson format).
Nonetheless, these documents are being productively utilized as examples not only to illustrate the essential underlying concepts of the proposal but also to investigate the limits of the new language learning system and to meticulously document them as they are observed.
It is hoped that these insights would come in handy while devising the class textbook lessons for the students, where small, simple sentences may be the norm, but that depends on the level of the class in question.
It is safe to say that it is a complex and important project, and that there is going to be much to learn and develop from the forthcoming feedback once its implementation begins.






































प्रदीपकदृश्यार्थम् अत्र नुदतु
प्रदीपकदृश्यस्य सरद्बिम्बप्रदर्शनार्थम् अत्र नुदतु





































وضاحتی ویڈیو کے لئے یہاں کلک کریں
وضاحتی ویڈیو کے سلائیڈ شو کے لئے یہاں کلک کریں






































व्याख्यात्मक विडियो के लिए यहाँ क्लिक करें
व्याख्यात्मक विडियो के स्लाइड शो के लिए यहाँ क्लिक करें





































వివరణాత్మక వీడియో కోసం ఇక్కడ క్లిక్ చేయండి
వివరణాత్మక వీడియో స్లైడ్ షో కోసం ఇక్కడ క్లిక్ చేయండి



















Click here for Explainer Video
Click here for Explainer Video Slideshow